






1. 容器
Java实用类库提供了一套相当完整的容器类来保存对象。
1.1. 基本概念
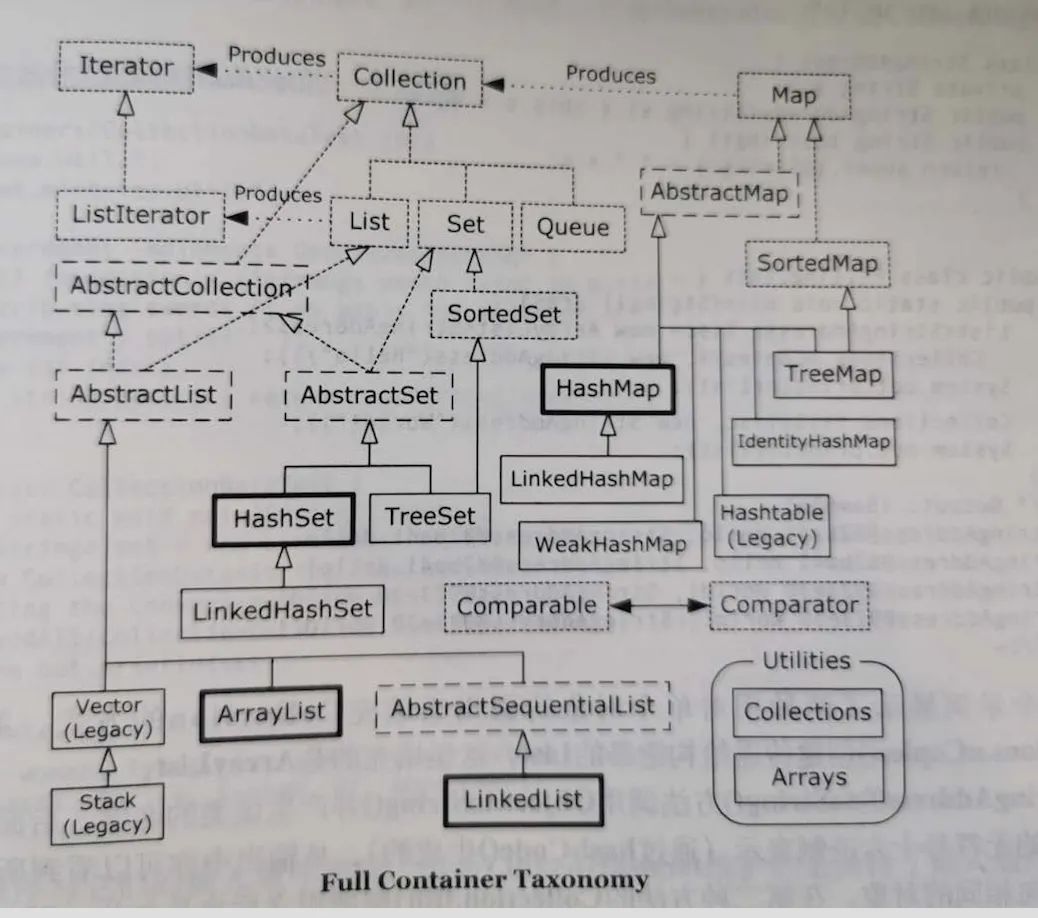
Java容器类类库的用途是保存元素,容器可以划分为两类:
Collection:一个独立元素的序列,这些元素都服从一条或多条规则。例如List必须按照插入顺序保存元素;Set不能有重复元素;Queue按照排队规则来确定对象产生的顺序。
Map:一组成对的“键值对”对象,允许你使用键来查找值。
下面是完整的容器分类法:
Java SE5新加了:
Queue接口及其实现PriorityQueue和各种风格的BlockingQueue
ConcurrentMap接口及其实现ConcurrentHashMap,用于多线程机制
CopyOnWriteArrayList和CopyOnWriteArraySet,它们也是用于多线程机制的
EnumSet和EnumMap,为使用enum而设计的Set和Map的特殊实现
1.2. 添加一组元素
在java.util包中的Arrays和Collections类中有很多实用方法。
已经有一个元素序列时,可以用Arrays.asList()将数组,或是用逗号分隔的元素列表转换成一个List对象。然后用Collections.addAll()方法将Collection对象,添加到Collection中。
1.3. 容器的打印
你必须使用Arrays.toString()来产生数组的可打印表示,但是打印容器就不用。
import java.util.*;public class PrintingContainers { static Collection fill(Collection collection) { List fruitList = Arrays.asList("apple", "banana", "banana"); collection.addAll(fruitList); return collection; } static Map fill(Map map) { map.put("apple", "red"); map.put("banana", "yellow"); map.put("banana", "green"); return map; } public static void main(String[] args) { System.out.println("ArrayList:" + fill(new ArrayList<>())); System.out.println("LinkedList:" + fill(new LinkedList<>())); System.out.println("HashSet:" + fill(new HashSet<>())); System.out.println("TreeSet:" + fill(new TreeSet<>())); System.out.println("LinkedHashSet:" + fill(new LinkedHashSet<>())); System.out.println("HashMap:" + fill(new HashMap<>())); System.out.println("TreeMap:" + fill(new TreeMap<>())); System.out.println("LinkedHashMap:" + fill(new LinkedHashMap<>())); }}/*ArrayList:[apple, banana, banana]LinkedList:[apple, banana, banana]HashSet:[banana, apple]TreeSet:[apple, banana]LinkedHashSet:[apple, banana]HashMap:{banana=green, apple=red}TreeMap:{apple=red, banana=green}LinkedHashMap:{apple=red, banana=green}*/1.4. 填充容器
像Arrays一样,相应的Collections类也有fill()方法,但是只能用来复制同一个对象引用来填充整个容器,并且只对List对象有用,不过所产生的列表可以传递给其他容器的构造器或addAll()方法。
class Address{ private String s; public Address(String s) { this.s = s; } @Override public String toString() { return super.toString() + " " + s; }}public class FillingList { public static void main(String[] args) { List list = new ArrayList<>(Collections.nCopies(3, new Address("Hello")));
System.out.println(list); Collections.fill(list, new Address("good")); System.out.println(list); }}/* Output:[Address@2b193f2d Hello, Address@2b193f2d Hello, Address@2b193f2d Hello][Address@355da254 good, Address@355da254 good, Address@355da254 good]*/
1.4.1. 一种Generator解决方案
可以使用泛型一章引入的Generator工具,与数组一章引入的CollectionData工具
// Generator.javapublic interface Generator<T> { T next();}// CollectionData.javapublic class CollectionData<T> extends ArrayList<T> { public CollectionData(Generator generator, int quantity) { for (int i = 0; i < quantity; i++) { add(generator.next()); } } public static CollectionDatalist(Generator generator, int quantity) { return new CollectionData<>(generator, quantity); }}下面是一个初始化LinkedHashSet的示例:
class Animal implements Generator<String> { private String[] small = "This cat is a kind of small animal".split(" "); private int index; @Override public String next() { return small[index++]; }}public class CollectionDataTest { public static void main(String[] args) { Set set = new LinkedHashSet<>(new CollectionData<>(new Animal(), 8)); set.addAll(CollectionData.list(new Animal(), 8)); System.out.println(set); }}1.4.2. Map生成器
可以对Map使用相同的方式,但这需要一个Pair类:
public class Pair<K, V> { public final K key; public final V value; public Pair(K key, V value) { this.key = key; this.value = value; }}然后编写可以使用各种不同Generator、Iterator和常量值的Map适配器:
public class MapData<K, V> extends LinkedHashMap<K, V> { public MapData(Generator> generator, int quantity) { for (int i = 0; i < quantity; i++) { Pair pair = generator.next(); put(pair.key, pair.value); } } public MapData(Generator generatorKey, Generator generatorValue, int quantity) { for (int i = 0; i < quantity; i++) { put(generatorKey.next(), generatorValue.next()); } } public MapData(Generator generatorKey, V value, int quantity) { for (int i = 0; i < quantity; i++) { put(generatorKey.next(), value); } } public MapData(Iterable generatorKey, Generator generatorValue) { for (K key : generatorKey) { put(key, generatorValue.next()); } } public MapData(Iterable generatorKey, V value) { for (K key : generatorKey) { put(key, value); } } public static MapDatamap(Generator> generatorPair, int quantity) { return new MapData<>(generatorPair, quantity); } public static MapDatamap(Generator generatorKey, Generator generatorValue, int quantity) { return new MapData<>(generatorKey, generatorValue, quantity); } public static MapDatamap(Iterable generatorKey, Generator generatorValue) { return new MapData<>(generatorKey, generatorValue); } public static MapDatamap(Iterable generatorKey, V value) { return new MapData<>(generatorKey, value); }}下面是一个使用MapData的示例,此处使用了数组一章引入的RandomGenerator工具:
class Letters implements Generator<Pair<Integer, String>>, Iterable<Integer> { private int size = 9; private int number = 1; private char letter = 'A'; @Override public Iteratoriterator() { return new Iterator() { @Override public boolean hasNext() { return number < size; } @Override public Integer next() { return number++; } public void remove() { throw new UnsupportedOperationException(); } }; } @Override public Pairnext() { return new Pair<>(number++, "" + letter++); }}public class MapDataTest { public static void main(String[] args) { System.out.println(MapData.map(new Letters(), 6)); System.out.println(MapData.map(new RandomGenerator.Character(), new RandomGenerator.String(3), 6)); System.out.println(MapData.map(new RandomGenerator.Character(), "Value", 6)); System.out.println(MapData.map(new Letters(), new RandomGenerator.String(6))); System.out.println(MapData.map(new Letters(), "Hello")); }}/* Output:{1=A, 2=B, 3=C, 4=D, 5=E, 6=F}{Y=Nzb, r=nyG, c=FOW, Z=nTc, Q=rGs, e=GZM}{m=Value, J=Value, M=Value, R=Value, o=Value, E=Value}{1=suEcUO, 2=neOEdL, 3=smwHLG, 4=EahKcx, 5=rEqUCB, 6=bkInaM, 7=esbtWH, 8=kjUrUk}{1=Hello, 2=Hello, 3=Hello, 4=Hello, 5=Hello, 6=Hello, 7=Hello, 8=Hello}*/1.5. Collection的常用方法
| 方法名 | 说明 |
| boolean add(T) | 添加一项 |
| boolean addAll(Collection extends T>) | 添加参数中的所有元素 |
| void clear() | 移除容器中的所有元素 |
| boolean contains(T) | 判断是否有某个值 |
| Boolean containsAll(Collection>) | 判断是否有参数中的所有值 |
| boolean isEmpty() | 容器是否为空 |
| Iterator iterator() | 返回一个Iterator用来遍历元素 |
| Boolean remove(Object) | 移除一个元素 |
| boolean removeAll(Collection>) | 移除参数中的所有元素 |
| Boolean retainAll(Collection>) | 只保存参数中的元素 |
| int size() | 返回容器中的元素数量 |
| Object[] toArray() | 返回包含容器中所有元素的数组 |
| T[] toArray(T[] a) | 返回有具体类型的数组 |
1.6. 可选操作
执行各种不同的添加和移除的方法在Collection接口中都是可选操作,这意味着实现类并不需要为这些方法提供功能定义。将方法定义为可选,是想延迟到需要时再实现,可以防止在设计中出现接口爆炸的情况。
对于大多数类来说,操作都应该可以工作,只有在特例中才会有未获支持的操作。如果有一个操作是未获支持的,那么在实现接口时可能会导致UnsupportedOperationException异常。
最常见的未获支持的操作,都源于背后固定尺寸的数据结构支持的容器,如用Arrays.asList()把数组转换为List时,就会得到这样的容器;还可以通过使用Collection类中不可修改的方法;选择创建任何会抛出UnsupportedOperationException异常的容器。
public class Unsupported { static void test(String msg, List list) { System.out.println("--- " + msg + " ---"); Collection collection = list; Collection subList = list.subList(1, 8); Collection collection2 = new ArrayList<>(subList); try { collection.retainAll(collection2); } catch (Exception e) { System.out.println("retainAll(): " + e); } try { collection.removeAll(collection2); } catch (Exception e) { System.out.println("removeAll(): " + e); } try { collection.clear(); } catch (Exception e) { System.out.println("clear(): " + e); } try { collection.add("X"); } catch (Exception e) { System.out.println("add(): " + e); } try { collection.addAll(collection2); } catch (Exception e) { System.out.println("addAll(): " + e); } try { collection.remove("C"); } catch (Exception e) { System.out.println("remove(): " + e); } try { list.set(0, "X"); } catch (Exception e) { System.out.println("List.set(): " + e); } } public static void main(String[] args) { List list = Arrays.asList("A B C D E F G H I J K L".split(" ")); test("Modifiable Copy", new ArrayList<>(list)); test("Arrays.asList()", list); test("UnmodifiableList()", Collections.unmodifiableList(new ArrayList<>(list))); }}/* Output:--- Modifiable Copy ------ Arrays.asList() ---retainAll(): java.lang.UnsupportedOperationExceptionremoveAll(): java.lang.UnsupportedOperationExceptionclear(): java.lang.UnsupportedOperationExceptionadd(): java.lang.UnsupportedOperationExceptionaddAll(): java.lang.UnsupportedOperationExceptionremove(): java.lang.UnsupportedOperationException--- UnmodifiableList() ---retainAll(): java.lang.UnsupportedOperationExceptionremoveAll(): java.lang.UnsupportedOperationExceptionclear(): java.lang.UnsupportedOperationExceptionadd(): java.lang.UnsupportedOperationExceptionaddAll(): java.lang.UnsupportedOperationExceptionremove(): java.lang.UnsupportedOperationExceptionList.set(): java.lang.UnsupportedOperationException*/1.7. List
List将元素维护在特定的序列中。基本的List很容易使用,大多数时候只是调用add()方法添加对象,用get()方法一次取出一个元素,以及调用iterator()获取用于该序列的Iterator。
有两种类型的List:
ArrayList:擅长随机访问元素,但是在List的中间插入和移除元素时较慢
LinkedList:它通过代价较低的在List中间进行的插入和删除操作,提供了优化的顺序访问。LinkedList在随机访问方面相对比较慢。
1.8. 迭代器
任何容器类,都必须有某种方式可以插入元素并将它们再次取回。迭代器是一个对象,它的作用是遍历并选择序列中的对象,而使用者不需要关注该序列底层的结构。
Java中的Iterator只能单向移动,它可以用来:
使用方法iterator(),要求容器返回一个Iterator。这个Iterator将准备好返回序列的第一个元素。
使用next()获得序列中的下一个元素。
使用hasNext()检查序列中是否还有元素。
使用remove()将迭代器新近返回的元素删除。
import java.util.ArrayList;import java.util.Arrays;import java.util.Iterator;import java.util.List;class Animal { private String name; public Animal(String name) { this.name = name; } static ListarrayList() { return new ArrayList<>(Arrays.asList( new Animal("dog"), new Animal("cat"), new Animal("sheep"), new Animal("bird"), new Animal("fish") )); } @Override public String toString() { return name; }}public class SimpleIteration { public static void main(String[] args) { List animalList = Animal.arrayList(); Iterator it = animalList.iterator(); while (it.hasNext()) { Animal animal = it.next(); System.out.print(animal + " "); } System.out.println(); for (Animal animal : animalList) { System.out.print(animal + " "); } System.out.println(); it = animalList.iterator(); for (int i = 0; i < 3; i++) { it.next(); it.remove(); } System.out.println(animalList); }}/* Output:dog cat sheep bird fish dog cat sheep bird fish [bird, fish]*/1.9. LinkedList
LinkedList添加了可以使其用作栈、队列或双端队列的方法。
常用方法有:
getFirst()、element()和peek():三者都返回列表的第一个元素,而不移除它,第三个方法在列表为空时返回null
removeFirst()、remove()和poll():三者都移除并返回列表的头,第三个方法在列表为空时返回null
addFirst()、add()和addLast():将某个元素插入到列表的头(尾)部
removeLast():移除并返回列表的最后一个元素。
1.9.1. Stack
栈(Stack)通常是指后进先出(LIFO)的容器。我们可以用LinkedList来实现一个栈:
import java.util.LinkedList;public class Stack<T> { private LinkedList storage = new LinkedList<>(); public void push(T v) { storage.addFirst(v); } public T peek() { return storage.getFirst(); } public T pop() { return storage.removeFirst(); } public boolean empty() { return storage.isEmpty(); } public String toString() { return storage.toString(); }}使用Stack:
public class StackTest { public static void main(String[] args) { Stack stack = new Stack<>(); for(String s : "My dog is pretty cute".split(" ")){ stack.push(s); } while(!stack.empty()){ System.out.print(stack.pop() + " "); } }}1.10. Set和存储顺序
| 类名 | 说明 |
| Set | Set接口中的元素是不重复且无序的。存入Set的元素必须定义equals()方法以确保对象的唯一性。 |
| HashSet | 为快速查找而设计的Set。存入HashSet的元素必须定义hashCode()方法。 |
| TreeSet | 维护元素次序的Set,底层是树结构。存入的元素必须实现Comparable接口。 |
| LinkedHashSet | 具有HashSet的查询速度,内部用链表维护元素的顺序(插入顺序)。存入的元素也必须定义hashCode()方法。 |
在下面的示例中,为了证明哪些方法对于某种特定的Set是必需的,创建了三个类。
// 只有equals方法class SetType { int i; public SetType(int i) { this.i = i; } @Override public boolean equals(Object o) { return o instanceof SetType && (i == ((SetType) o).i); } @Override public String toString() { return Integer.toString(i); }}// 有equals和hashCode方法class HashType extends SetType { public HashType(int i) { super(i); } @Override public int hashCode() { return i; }}// 有equals、hashCode和compareTo方法class TreeType extends SetType implements Comparable<TreeType> { public TreeType(int i) { super(i); } @Override public int compareTo(TreeType o) { return Integer.compare(o.i, i); }}public class TypesForSets { // 填充int类型的数据 static Setfill(Set set, Class type) { try { for (int i = 0; i < 6; i++) { set.add(type.getConstructor(int.class).newInstance(i)); } } catch (Exception e) { throw new RuntimeException(e); } return set; } static void test(Set set, Class type) { fill(set, type); // 尝试增加重复的数据 fill(set, type); System.out.println(set); } public static void main(String[] args) { test(new HashSet<>(), HashType.class); test(new LinkedHashSet<>(), HashType.class); test(new TreeSet<>(), TreeType.class); test(new HashSet<>(), SetType.class); test(new HashSet<>(), TreeType.class); test(new LinkedHashSet<>(), SetType.class); test(new LinkedHashSet<>(), TreeType.class); try { test(new TreeSet<>(), SetType.class); }catch (Exception e){ System.out.println(e.getMessage()); } try { test(new TreeSet<>(), HashType.class); }catch (Exception e){ System.out.println(e.getMessage()); } }}/* Output:[0, 1, 2, 3, 4, 5][0, 1, 2, 3, 4, 5][5, 4, 3, 2, 1, 0][0, 1, 0, 4, 5, 2, 1, 3, 2, 5, 3, 4][4, 4, 0, 5, 3, 1, 0, 2, 3, 1, 2, 5][0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5][0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5]java.lang.ClassCastException: SetType cannot be cast to java.lang.Comparablejava.lang.ClassCastException: HashType cannot be cast to java.lang.Comparable*/从输出可以看出,HashSet和LinkedSet默认都是正序的,TreeSet是倒序的。根据报错可以看出TreeSet必须实现Comparable。
如果没有恰当的支持必要的equals和hashCode方法,Set中就会出现重复数据,但是又不会有运行时错误。
1.11. Map
映射表(也称为关联数组)的基本思想是它维护的是键-值(对)关联。标准Java类库中包含了Map的几种基本实现:HashMap、TreeMap、LinkedHashMap、WeakHashMap、ConcurrentHashMap、IdentityHashMap。它们在效率、键值对的保存及呈现次序、对象的保存周期、映射表如何在多线程的程序中工作、判定键等价性的策略等方面都有所不同。
下面是一个极简单的关联数组的示例:
public class AssociativeArray<K, V> { private Object[][] pairs; private int index; public AssociativeArray(int length) { pairs = new Object[length][2]; } public void put(K key, V value) { if (index >= pairs.length) { throw new ArrayIndexOutOfBoundsException(); } pairs[index++] = new Object[]{key, value}; } @SuppressWarnings("unchecked") public V get(K key) { for (int i = 0; i < index; i++) { if (key.equals(pairs[i][0])) { return (V) pairs[i][1]; } } return null; } @Override public String toString() { StringBuilder result = new StringBuilder(); for (int i = 0; i < index; i++) { result.append(pairs[i][0].toString()); result.append(" : "); result.append(pairs[i][1].toString()); if (i < index - 1) { result.append("\n"); } } return result.toString(); } public static void main(String[] args) { AssociativeArray map = new AssociativeArray<>(3); map.put("sky","blue"); map.put("grass","green"); map.put("sun","warm"); System.out.println(map); }}/* Output:sky : bluegrass : greensun : warm*/1.11.1. 性能
性能是映射表中的一个重要问题,在get()方法中使用线性搜索时,执行速度会相当地慢。HashMap使用了散列码来取代对键的缓慢搜索。散列码是相对唯一的、用以代表对象的int值。
| 类名 | 说明 |
| HashMap | 基于散列表的实现,可以通过构造器设置容量和负载因子来调整容器的性能。在JDK1.8中,修改为链表加红黑树的实现。 |
| LinkedHashMap | 类似于HashMap,但在取键值对的时候是按照插入次序或者最近最少使用次序(LRU)。 |
| TreeMap | 基于红黑树的实现,键值对是经过排序的,还带有一个supMap()方法来返回一个子树。 |
| WeakHashMap | 弱键映射,允许释放映射指向的对象,这是为了解决某类特殊问题而设计的。 |
| ConcurrentHashMap | 一种线程安全的Map |
| IdentityHashMap | 使用==代替equals()方法来对键进行比较的散列映射,也是专为解决特殊问题而设计的。 |
1.11.2. LinkedHashMap
为了提高速度,LinkedHashMap散列化所有的元素,但在遍历键值对时,却又以元素的插入顺序返回健值对。可以在构造器中进行设定,使其采用LRU算法,这样没有被访问过的元素就会出现在队列的前面。
首先自定义一个CountingMapData,通过继承java.util.AbstractMap来创建定制的Map:
public class CountingMapData extends AbstractMap<Integer, String> { private int size; private static String[] chars = "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" "); public CountingMapData(int size) { if (size < 0) { this.size = 0; return; } this.size = size; } private static class Entry implements Map.Entry<Integer, String> { int index; public Entry(int index) { this.index = index; } @Override public boolean equals(Object obj) { return Integer.valueOf(index).equals(obj); } @Override public Integer getKey() { return index; } @Override public String getValue() { return chars[index % chars.length] + (index / chars.length); } @Override public String setValue(String value) { throw new UnsupportedOperationException(); } @Override public int hashCode() { return Integer.valueOf(index).hashCode(); } } public Set> entrySet() { Set> entries = new LinkedHashSet<>(); for(int i = 0; i< size; i++){ entries.add(new Entry(i)); } return entries; } public static void main(String[] args) { System.out.println(new CountingMapData(3)); }}/* Output:{0=A0, 1=B0, 2=C0}*/下面示例展示了LinkedHashMap的这两个特点:
public class LinkedHashMapDemo { public static void main(String[] args) { // LinkedHashMap是排序的 LinkedHashMap linkedHashMap = new LinkedHashMap<>(new CountingMapData(8)); System.out.println(linkedHashMap); // 开启LRU算法 linkedHashMap = new LinkedHashMap<>(16, 0.75f, true); linkedHashMap.putAll(new CountingMapData(8)); // 先只访问前6个元素,这样后两个元素就会出现在队列前面 for (int i = 0; i < 6; i++) { linkedHashMap.get(i); } System.out.println(linkedHashMap); linkedHashMap.get(0); System.out.println(linkedHashMap); }}/* Output:{0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0}{6=G0, 7=H0, 0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0}{6=G0, 7=H0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 0=A0}*/1.12. Queue队列
队列是一个典型的先进先出(FIFO)的容器。队列常被当作一种可靠的对象从程序的某个区域传输到另一个区域的途径。队列在并发编程中特别重要。
public class QueueBehavior { private static int count = 10; static void test(Queue queue, Generator generator) { for (int i = 0; i < count; i++) { queue.offer(generator.next()); } while (queue.peek() != null) { System.out.print(queue.remove() + " "); } System.out.println(); } static class Gen implements Generator<String> { String[] s = "one two three four five six seven eight nine ten".split(" "); int i; @Override public String next() { return s[i++]; } } public static void main(String[] args) { test(new LinkedList<>(), new Gen()); test(new PriorityQueue<>(), new Gen()); test(new ArrayBlockingQueue<>(count), new Gen()); test(new ConcurrentLinkedQueue<>(), new Gen()); test(new PriorityBlockingQueue<>(), new Gen()); }}/* Output:one two three four five six seven eight nine ten eight five four nine one seven six ten three two one two three four five six seven eight nine ten one two three four five six seven eight nine ten eight five four nine one seven six ten three two */可以看到除了优先级队列,基他队列都是按照元素先后顺序来处理的。
除了并发应用,队列在Java SE5中仅有的两个实现是LinkedList和PriorityQueue,它们的差异在于排序行为而不是性能。
LinkedList提供了方法以支持队列的行为,并且它实现了Queue接口。
public class QueueDemo { public static void printQueue(Queue queue) { while (queue.peek() != null) { System.out.print(queue.remove() + " "); } System.out.println(); } public static void main(String[] args) { Queue queue = new LinkedList<>(); Random random = new Random(20); for (int i = 0; i < 10; i++) { queue.offer(random.nextInt(i + 10)); } printQueue(queue); Queue characterQueue = new LinkedList<>(); for(char c : "Orange".toCharArray()){ characterQueue.offer(c); } printQueue(characterQueue); }}/* Output:3 10 9 2 3 0 2 11 1 7 O r a n g e */PriorityQueue描述了最典型的队列规则。队列规则是指在给定的一组队列中的元素的情况下,确定下一个弹出队列的元素的规则。优先级队列声明下一个弹出元素是具有最高优先级的。
当在PriorityQueue上调用offer()方法来插入一个对象时,这个对象会在队列中被排序。PriorityQueue可以确保调用peek()、poll()和remove()方法时,获取的元素将是队列中优先级最高的元素。
import java.util.*;public class PriorityQueueDemo { public static void main(String[] args) { // 随机生成5个数,在PQ中自动按数字大小排序 PriorityQueue priorityQueue = new PriorityQueue<>(); Random random = new Random(20); for (int i = 0; i < 5; i++) { priorityQueue.offer(random.nextInt(i + 10)); } QueueDemo.printQueue(priorityQueue); // 正序和逆序输出列表 List integerList = Arrays.asList(20, 15, 10, 5, 0); priorityQueue = new PriorityQueue<>(integerList); QueueDemo.printQueue(priorityQueue); priorityQueue = new PriorityQueue<>(integerList.size(), Collections.reverseOrder()); priorityQueue.addAll(integerList); QueueDemo.printQueue(priorityQueue); // 字符串按字母排序 String apple = "A red apple"; List appleString = Arrays.asList(apple.split("")); PriorityQueue stringPQ = new PriorityQueue<>(appleString); QueueDemo.printQueue(stringPQ); stringPQ = new PriorityQueue<>(appleString.size(), Collections.reverseOrder()); stringPQ.addAll(appleString); QueueDemo.printQueue(stringPQ); // 用HashSet来除重 Set charSet = new HashSet<>(); for(char c : apple.toCharArray()){ charSet.add(c); } PriorityQueue characterPQ = new PriorityQueue<>(charSet); QueueDemo.printQueue(characterPQ); }}/* Output:2 3 3 9 100 5 10 15 20 2525 20 15 10 5 0 A a d e e l p p rr p p l e e d a A A a d e l p r*/1.13. Collection和Iterator
Collection是描述所有序列容器的共性的根接口。通过继承AbstractCollection能更容易创建自己的容器类,但是需要实现iterator()方法和size()方法。
import java.util.AbstractCollection;import java.util.Iterator;class Animal { private String name; public Animal(String name) { this.name = name; } static Animal[] animalArray() { return new Animal[]{ new Animal("dog"), new Animal("cat"), new Animal("sheep"), new Animal("bird"), new Animal("fish"), }; } @Override public String toString() { return name; }}public class CollectionSequence extends AbstractCollection<Animal> { private Animal[] animals = Animal.animalArray(); @Override public Iteratoriterator() { return new Iterator() { private int index = 0; @Override public boolean hasNext() { return index < animals.length; } @Override public Animal next() { return animals[index++]; } }; } @Override public int size() { return animals.length; } public static void main(String[] args) { CollectionSequence collectionSequence = new CollectionSequence(); for(Animal animal: collectionSequence){ System.out.print(animal + " "); } }}1.14. Foreach与迭代器
foreach语法不仅可以用于数组,也可以用于Collection对象。在Java SE5中引入了新的被称为Iterable的接口,该接口包含一个能够产生Iterator的iterator()方法,并且Iterable接口被foreach用来在序列中移动。所以任何实现Iterable的类都可以将它用于foreach语句中。
import java.util.Iterator;public class IterableClass implements Iterable<String> { protected String[] words = "I have a red apple".split(" "); @Override public Iteratoriterator() { return new Iterator() { private int index = 0; @Override public boolean hasNext() { return index < words.length; } @Override public String next() { return words[index++]; } }; } public static void main(String[] args) { for (String s : new IterableClass()) { System.out.print(s + " "); } }}1.15. 适配器方法惯用法
如果希望在默认的前向迭代器的基础上,添加产生反向迭代器的能力,可以使用适配器方法的惯用法。在之前的IterableClass.java示例中添加两种适配器方法:
import java.util.*;public class MultiIterableClass extends IterableClass { public Iterablereversed() { return new Iterable() { @Override public Iteratoriterator() { return new Iterator() { int current = words.length - 1; @Override public boolean hasNext() { return current > -1; } @Override public String next() { return words[current--]; } }; } }; } public Iterablerandomized() { return new Iterable() { @Override public Iteratoriterator() { List shuffled = new ArrayList(Arrays.asList(words)); Collections.shuffle(shuffled, new Random(20)); return shuffled.iterator(); } }; } public static void main(String[] args) { MultiIterableClass mic = new MultiIterableClass(); for (String s : mic.reversed()) { System.out.print(s + " "); } System.out.println(); for (String s : mic.randomized()) { System.out.print(s + " "); } System.out.println(); for (String s : mic) { System.out.print(s + " "); } }}/* Outputapple red a have Iapple have I a redI have a red apple*/1.16. 散列与散列码
考虑一个天气预报系统,将Groundhog(土拨鼠)对象与Prediction(预报)对象联系起来,预测春天还有多久到来。
public class Groundhog { protected int number; public Groundhog(int number) { this.number = number; } @Override public String toString() { return "Groundhog #" + number; }}每只土拨鼠都有自己的标识号。
public class Prediction { private static Random random = new Random(47); private boolean shadow = random.nextDouble() > 0.5; @Override public String toString() { if (shadow) { return "Six more weeks of Winter!"; } return "Early Spring!"; }}预测类会随机生成字符串。
public static void detectSpring(Class type) throws Exception { Constructor groundhog = type.getConstructor(int.class); Map map = new HashMap<>(); for (int i = 0; i < 4; i++) { map.put(groundhog.newInstance(i), new Prediction()); } System.out.println("map = " + map); Groundhog groundhog2 = groundhog.newInstance(3); System.out.println("Looking up prediction for " + groundhog2); if(map.containsKey(groundhog2)){ System.out.println(map.get(groundhog2)); }else { System.out.println("Key not found: " + groundhog2); } } public static void main(String[] args) throws Exception{ detectSpring(Groundhog.class); }}/* Output:map = {Groundhog #1=Six more weeks of Winter!, Groundhog #2=Early Spring!, Groundhog #3=Early Spring!, Groundhog #0=Six more weeks of Winter!}Looking up prediction for Groundhog #3Key not found: Groundhog #3*/在测试方法中,发现无法通过土拨鼠找到对应的预测值,这是由于没有恰当地重写equals()和hashCode()方法。
修改一下土拨鼠类:
public class Groundhog2 extends Groundhog { public Groundhog2(int number) { super(number); } @Override public int hashCode() { return number; } @Override public boolean equals(Object obj) { return obj instanceof Groundhog2 && (number == ((Groundhog2) obj).number); }}现在再来测试一下:
public class SpringDetector2 { public static void main(String[] args) throws Exception{ SpringDetector.detectSpring(Groundhog2.class); }}/* Output:map = {Groundhog #0=Six more weeks of Winter!, Groundhog #1=Six more weeks of Winter!, Groundhog #2=Early Spring!, Groundhog #3=Early Spring!}Looking up prediction for Groundhog #3Early Spring!*/HashMap使用equals()方法来判断当前的键是否与表中存在的键相同。正确的equals()方法必须满足下列五个条件:
自反性,对任意x,x.equals(x)一定返回true。
对称性,对任意x和y,如果y.equals(x)返回true,则x.equals(y)也返回true。
传递性,对任意x、y、z,如果x.equals(y)返回true,并且y.equals(x)返回true,则x.equals(z)一定返回true。
一致性,对任意x和y,如果对象中用于等价比较的信息没有改变,那么x.equals(y)的结果始终一致。
对任何不是null的x,x.equals(null)一定返回false
1.16.1. 为速度而生的散列
在使用对象做为键时,如果不为键重写equals()和hashCode()方法,那么使用散列的数据结构就无法正确处理这个键。使用散列的目的在于,想要使用一个对象来查找另一个对象。
散列的价值在于速度,它将键保存在起来以便可以很快的找到。存储一组元素最快的数据结构是数组,所以可以使用数组来表示键的信息。通过键对象生成一个数字,将其作为数组的下标,这个数字就是散列码。但是数组的容量是固定的,为了解决这个问题,不同的键是可以产生相同的数组下标,也就是hash冲突。通常冲突由外部链接处理:数组并不直接保存值,而是保存值的list,然后对list中的值使用equals()方法进行线性查询。因此,通过快速跳到数组的某个位置,只对很少的元素进行比较,提高了查询数据的速度。
于是查询一个值的过程首先是计算散列码,然后使用散列码查询数组。理解了散列的原理,现在就可以来实现一个简单的散列Map了:
public class SimpleHashMap<K, V> extends AbstractMap<K, V> { private static final int SIZE = 233; @SuppressWarnings("unchecked") private LinkedList>[] buckets = new LinkedList[SIZE]; @Override public V put(K key, V value) { V oldValue = null; // 先计算出索引位置 int index = Math.abs(key.hashCode() % SIZE); // 每个数组位置都是一个链表 if (buckets[index] == null) { buckets[index] = new LinkedList<>(); } LinkedList> bucket = buckets[index]; MapEntry pair = new MapEntry<>(key, value); // 如果链表上已经有相同的key,就替换对应的值,返回旧值 boolean found = false; ListIterator> it = bucket.listIterator(); while (it.hasNext()) { MapEntry iPair = it.next(); if (iPair.getKey().equals(key)) { oldValue = iPair.getValue(); it.set(pair); found = true; break; } } if (!found) { buckets[index].add(pair); } return oldValue; } @Override public V get(Object key) { int index = Math.abs(key.hashCode()) % SIZE; if (buckets[index] == null) { return null; } for (MapEntry iPair : buckets[index]) { if (iPair.getKey().equals(key)) { return iPair.getValue(); } } return null; } public Set> entrySet() { Set> set = new HashSet<>(); for (LinkedList> bucket : buckets) { if (bucket == null) { continue; } set.addAll(bucket); } return set; } public static void main(String[] args) { SimpleHashMap map = new SimpleHashMap<>(); map.put("sky","blue"); map.put("grass","green"); map.put("sun","warm"); System.out.println(map); }}由于散列表中的槽位(slot)通常称为桶位(bucket),所以这里就将表示实际散列表的数组命名为bucket。为了使散列分布均匀,桶的数量通常使用质数,不过近来经过广泛的测试,Java的散列函数都使用2的整数次方。对现代处理器来说,除法与求余数是最慢的操作。使用2的整数次方长度的散列表,可用掩码代替除法。
1.16.2. 覆盖hashCode()
想要使hashCode实用,它必须速度快,并且必须有意义。也就是说,它必须基于对象的内容生成散列码。虽然散列码不必是独一无二的,但是通过hashCode()和equals()必须能够完全确定对象的身份。
下面是一个编写hashCode()的指导:
给int类型的变量result赋予某个非零值常量,例如17。
为对象内每个有意义的域f(每个可以做equals()操作的域)计算出一个int散列码
合并计算得到的散列码: result = 37 * result + c
返回result
检查hashCode()最后生成的结果,确保相同的对象有相同的散列码
| 域类型 | 计算 |
| boolean | c = (f ? 0 : 1) |
| byte、char、short或int | c = (int)f |
| long | c = (int)(f ^ (f >>> 32)) |
| float | c = Float.floatToIntBits(f); |
| double | long I = Double.doubleToLongBits(f); c = (int)(I ^ (I >>> 32)) |
| Object | c = f.hashCode() |
| 数组 | 对每个元素应用上述规则 |
遵循这个指导的例子来自定义hashCode()方法:
public class CountedString { private static List created = new ArrayList<>(); private String s; private int id = 0; public CountedString(String s) { this.s = s; created.add(s); for (String s2 : created) { if (s2.equals(s)) { id++; } } } @Override public String toString() { return "String: " + s + " id: " + id + " hashCode(): " + hashCode(); } @Override public int hashCode() { int result = 17; result = 37 * result + s.hashCode(); result = 37 * result + id; return result; } @Override public boolean equals(Object obj) { return obj instanceof CountedString && s.equals(((CountedString) obj).s) && id == ((CountedString) obj).id; } public static void main(String[] args) { Map map = new HashMap<>(); CountedString[] countedStrings = new CountedString[5]; for (int i = 0; i < countedStrings.length; i++) { countedStrings[i] = new CountedString("hi"); map.put(countedStrings[i], i); } System.out.println(map); for (CountedString countedString : countedStrings) { System.out.println("Looking up " + countedString); System.out.println(map.get(countedString)); } }}/* Output:{String: hi id: 4 hashCode(): 146450=3, String: hi id: 5 hashCode(): 146451=4, String: hi id: 2 hashCode(): 146448=1, String: hi id: 3 hashCode(): 146449=2, String: hi id: 1 hashCode(): 146447=0}Looking up String: hi id: 1 hashCode(): 1464470Looking up String: hi id: 2 hashCode(): 1464481Looking up String: hi id: 3 hashCode(): 1464492Looking up String: hi id: 4 hashCode(): 1464503Looking up String: hi id: 5 hashCode(): 1464514*/1.17. 选择接口的不同实现
1.17.1. 对List的选择
随机访问数据时,有数组支撑的List和ArrayList访问速度不受列表大小影响,而LinkedList会随着列表变大而增加访问时间。所以对于需要大量随机访问时,建议不要选择LinkedList。
随机插入数据时,ArrayList需要创建空间并把它的所有引用向前移动,导致列表变大时开销也会变大;而LinkedList只需要链接新的元素,不会挪动己有元素,所以随机插入的开销不会受列表大小影响。
建议把ArrayList作为默认首选,只有需要使用额外的功能,例如经常要随机插入数据时,才选用LinkedList。
1.17.2. 对Set的选择
HashSet的性能基本上总是比TreeSet好,尤其是在添加和查询元素
TreeSet可以维持元素的排序状态,所以只有需要一个排好序的Set时,才应该使用TreeSet
对于插入操作,LinkedHashSet因为要维护链表,所以开销会比HashSet更高
1.17.3. 对Map的选择
除了IdentityHashMap,所有的Map实现的插入操作都会随着Map变大而明显变慢,不过查找的代价通常比插入要小的多。
TreeMap通常比HashMap要慢。TreeMap适合于创建有序列表。
LinkedHashMap在插入时比HashMap慢,因为它要维护散我数据结构的同时还要维护链表,不过也正是由于这个列表,使其迭代速度更快。
1.17.3.1. HashMap的性能因子
可以通过手工调整HashMap来提高其性能。有几个相关的术语:
1.容量:表中的桶位数2.初始容量:表在创建时所拥有的桶位数3.尺寸:表中当前存储的项数4.负载因子:尺寸/容量。空表的负载因子是0,而半满表的负载因子是0.5。负载小的表产生冲突的可能性更小,对插入和查找都是更理想的。HashMap和HashSet都有指定负载因子的构造器,表示当负载情况达到了该负载因子的水平时,容器将自动增加其容量(桶位数),并重新将现有对象分布到新的桶位中,也就是再散列。
1.18. 容器的快速报错
Java容器有一种保护机制,能够防止多个进程同时修改同一个容器的内容。这种机制就是快速报错(fail-fast)机制,一旦发现了有其他进程修改了容器,就会抛出ConcurrentModificationException异常。
只需要创建一个迭代器,然后修改迭代器指向的Collection就能触发这个机制:
public class FailFast { public static void main(String[] args) { Collection collection = new ArrayList<>(); Iterator iterator = collection.iterator(); collection.add("An object"); try { String s = iterator.next(); } catch (ConcurrentModificationException e) { System.out.println(e); } }}/* Output:java.util.ConcurrentModificationException*/1.19. 持有引用
java.lang.ref类库包含了一组方便垃圾回收的类,当存在可能会耗尽内存的大对象时,这些类显得特别有用。有三个继承自抽象类Reference的类:SoftReference、WeakReference和PhantomReference。
如果想继续持有某个对象的引用,又希望能够允许垃圾回收器释放它,就可以使用Reference对象。SoftReference、WeakReference和PhantomReference由强到弱排序,对应不同级别的可获得性。三者的区别还在于:
SoftReference:一个对象只有软引用,垃圾回收器会在内存不足时才会回收它。SoftReference常用以实现内存敏感的高速缓存。
WeakReference:一个对象只有弱引用,无论内存是否充足,垃圾回收器在扫描到它的时候都会回收。WeakReference是为实现“规范映射”(canonicalizing mappings)而设计的,规范映射中对象的实例可以在程序的多处被同时使用,以节省存储空间。
PhantomReference:一个对象只有虚引用,则生命周期等同于没有任何引用,垃圾回收器在任何时候都可能回收它,虚引用往往是用来跟踪垃圾回收器的回收活动的。PhantomReference用以调度回收前的清理工作,它比Java终止机制更灵活。
这三类引用都可以在构造器中传入一个ReferenceQueue(用作回收清理工作的工具)。使用SoftReference和WeakReference时,所引用的对象被释放后才会被放入ReferenceQueue。而PhantomReference只能依赖于ReferenceQueue,它引用的对象在被释放之前就放入了ReferenceQueue中。所以我们可以监控这个ReferenceQueue,在对象被释入前做一些操作。
下面是一个简单的示例:
class VeryBig { private String id; public VeryBig(String id) { this.id = id; } @Override public String toString() { return id; } @Override protected void finalize() { System.out.println("Finalizing " + id); }}public class References { private static ReferenceQueue referenceQueue = new ReferenceQueue<>(); public static void checkQueue() { Reference extends VeryBig> reference = referenceQueue.poll(); if (reference != null) { System.out.println("In queue: " + reference.get()); } } public static void main(String[] args) { int size = 3; LinkedList> softReferenceList = new LinkedList<>(); for (int i = 0; i < size; i++) { softReferenceList.add(new SoftReference<>(new VeryBig("Soft " + i), referenceQueue)); System.out.println("Just created: " + softReferenceList.getLast()); checkQueue(); } LinkedList> weakReferenceList = new LinkedList<>(); for (int i = 0; i < size; i++) { weakReferenceList.add(new WeakReference<>(new VeryBig("Weak " + i), referenceQueue)); System.out.println("Just created: " + weakReferenceList.getLast()); checkQueue(); } System.out.println("\n--- 开始垃圾回收 ---\n"); System.gc(); LinkedList phantomReferenceList = new LinkedList<>(); for (int i = 0; i < size; i++) { phantomReferenceList.add(new PhantomReference<>(new VeryBig("Phantom " + i), referenceQueue)); System.out.println("Just created: " + phantomReferenceList.getLast()); checkQueue(); } }}/* Output:Just created: java.lang.ref.SoftReference@2b193f2dJust created: java.lang.ref.SoftReference@355da254Just created: java.lang.ref.SoftReference@4dc63996Just created: java.lang.ref.WeakReference@d716361Just created: java.lang.ref.WeakReference@6ff3c5b5Just created: java.lang.ref.WeakReference@3764951d--- 开始垃圾回收 ---Finalizing Weak 1Finalizing Weak 2Finalizing Weak 0Just created: java.lang.ref.PhantomReference@4b1210eeIn queue: nullJust created: java.lang.ref.PhantomReference@4d7e1886In queue: nullJust created: java.lang.ref.PhantomReference@3cd1a2f1In queue: null*/1.19.1. WeakHashMap
WeakHashMap是容器类中有一种特殊的Map,它用来保存WeakReference。在这种映射中,每个值只保存一份实例以节省存储空间。当程序需要值时,可以在映射中查询现有的对象,而不是重新再创建。
下面的示例可以看到垃圾回收器每隔三个键就跳过一个,因为指向那个键的普通引用被存入的keys数组,所以那些对象不能被垃圾回收器回收:
class Element { private String id; public Element(String id) { this.id = id; } @Override public String toString() { return id; } @Override public int hashCode() { return id.hashCode(); } @Override public boolean equals(Object obj) { return obj instanceof Element && id.equals(((Element) obj).id); } @Override protected void finalize() { System.out.println("Finalizing " + getClass().getSimpleName() + " " + id); }}class Key extends Element { public Key(String id) { super(id); }}class Value extends Element { public Value(String id) { super(id); }}public class CanonicalMapping { public static void main(String[] args) { int size = 30; Key[] keys = new Key[size]; WeakHashMap map = new WeakHashMap<>(); for (int i = 0; i < size; i++) { Key key = new Key(Integer.toString(i)); Value value = new Value(Integer.toString(i)); map.put(key, value); // 把3的倍数放入数组中,形成不不可回收的强引用 if (i % 3 == 0) { keys[i] = key; } } Arrays.stream(keys).forEach(p -> System.out.print(p + " ")); System.gc(); }}/* Output:0 null null 3 null null 6 null null 9 null null 12 null null 15 null null 18 null null 21 null null 24 null null 27 null null Finalizing Key 8Finalizing Key 7Finalizing Key 5Finalizing Key 4Finalizing Key 2Finalizing Key 1Finalizing Key 29Finalizing Key 28Finalizing Key 26Finalizing Key 25Finalizing Key 23Finalizing Key 22Finalizing Key 20Finalizing Key 19Finalizing Key 17Finalizing Key 16Finalizing Key 14Finalizing Key 13Finalizing Key 11Finalizing Key 10*/














 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









