





Understanding Data Structures is helpful in all aspects of programming, you don’t need to have a particular use case where you’ll use a Tree or a Graph to have to consider learning about them. In fact, I don’t think I’ve ever implemented a proper Tree structure in my 15 years of software development, however, understanding how they work has helped me several times in the past.
理解数据结构在编程的所有方面都是有帮助的,您不需要具有使用树或图来考虑学习它们的特定用例。 实际上,我认为我在15年的软件开发中从未实现过适当的Tree结构,但是,了解它们的工作原理在过去曾对我有所帮助。
The knowledge about them and about their structure and behavior can be extrapolated to other areas within our field. Say you have a Graph, and now think about how a microservice-base architecture can be described. Now look at the following image:
有关它们以及它们的结构和行为的知识可以推断到我们领域内的其他领域。 假设您有一个Graph,现在考虑如何描述基于微服务的体系结构。 现在看下面的图片:
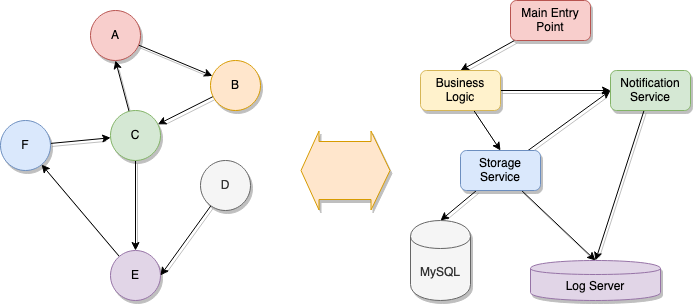
See where I’m going with this? Even a weighted graph can still be considered as the representation of architecture, considering the weight of those edges as if it were the time it takes data to travel from one service to the other.
看到我要去哪里了吗? 即使将加权图视为体系结构的表示形式,也要考虑这些边缘的权重,就好像是将数据从一种服务传输到另一种服务所花费的时间一样。
And the same could be said about the other structures we’ll be covering here, so even if you don’t feel like you’ll ever implement one of these in your day-to-day tasks, take the time to understand them, that knowledge might come in handy in the future.
对于我们将在这里介绍的其他结构也可以这么说,因此即使您不觉得自己会在日常任务中实现其中之一,也要花一些时间来理解它们,将来可能会派上用场。
And finally, a note about implementation: some of these structures can easily be represented by Arrays at its most basics, but you need to look a bit further in order to understand it’s full potential. A data structure is not just the way you structure your data, but also the logic associated with it. The way you insert data, what happens to it inside of it, and even the way you take data out of your structure. That, is where the real magic of data structures resides and the whole point for their existence. Otherwise, we would all be using Arrays for everything.
最后,关于实现的注意事项:Arrays可以很容易地从最基本的方面来表示其中的某些结构,但是您需要进一步研究才能了解其全部潜力。 数据结构不仅是构造数据的方式,而且还是与其关联的逻辑。 插入数据的方式,内部数据的处理方式,甚至是从结构中取出数据的方式。 那就是数据结构真正的魔力所在,以及它们存在的全部要点。 否则,我们所有人都会对所有内容使用数组。
Tip: Use Bit (Github) to share, document, and manage reusable JS components from different projects. It’s a great way to increase code reuse, speed up development, and build apps that scale.
提示:使用Bit ( Github )可以共享,记录和管理来自不同项目的可重用JS组件。 这是增加代码重用,加速开发并构建可扩展应用程序的好方法。
Bit supports NodeJS, TypeScript, React, Vue, Angular, and many others.
Bit支持NodeJS,TypeScript,React,Vue,Angular等。
Queue列 (Queues)
If you need to handle a list of tasks that need to be executed in order of creation, you can take advantage of the inner workings of Queues. These are very basic structures in which you can insert elements into and take them out following the FIFO approach: First In First Out.
如果您需要处理按创建顺序需要执行的任务列表,则可以利用Queue的内部工作原理。 这些是非常基本的结构,您可以按照FIFO方法将元素插入或取出元素:先进先出。
In other words, just like you would handle a normal queue waiting at the supermarket, the first person getting in the queue will be the first to be served.
换句话说,就像您要处理在超市里等待的普通队列一样,第一个进入队列的人将是第一个被送达的人。
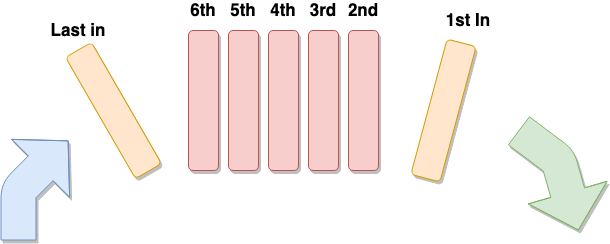
As you can see from the diagram above, the structure itself is very simple, and the implementation itself is also quite straightforward, especially if you go with Arrays as a basic data structure.
从上图可以看到,结构本身非常简单,实现本身也非常简单,特别是如果将Arrays作为基本数据结构使用的话。
The two main methods from this implementation are the enqueue and dequeue methods. With the first one, you can add elements to the queue while with the latter you remove them.
此实现中的两个主要方法是入enqueue和dequeue方法。 使用第一个,您可以将元素添加到队列中,而使用后者,则可以删除它们。
As you can see I went with an array for the basic data structure, because it greatly simplifies both methods. Enqueuing is just the same as pushing an element into the array and dequeuing is resolved with a simple call to shift, which removes the first element and it also returns it.
如您所见,我将数组用于基本数据结构,因为它极大地简化了这两种方法。 入队与将元素推入数组中相同,通过简单的shift调用即可解决出队问题,该调用删除了第一个元素,并且还返回了它。
The generator function was added as an extra cherry on top to allow for operations such as the one shown below:
生成器功能被添加为顶部的额外功能,以允许进行如下所示的操作:
Other than the simple queue I’m showing you here, you can also find:
除了我在这里向您展示的简单队列之外,您还可以找到:
- Priority queues, which have their elements internally sorted by a priority value. 优先级队列,其元素在内部按优先级值排序。
- Circular queues, which have their last element pointing to the first one. 循环队列,其最后一个元素指向第一个。
- And a Double Ended Queue, which allows you to add and remove elements both from the front and the back (something that, if you ask me, sounds like cheating!). 还有一个双头队列,它允许您从正面和背面添加和删除元素(如果您问我的话,这听起来像作弊!)。
叠放 (Stack)
I’m adding stacks as second on the list because honestly, they look a lot like queues, so much so that sometimes they get confused with each other.
我将堆栈排在第二位,因为老实说,它们看上去很像队列,以至于有时它们彼此混淆。
You can think of this data structure as a stack of books if you start putting one on top of the other, once you want to get one, you’ll have to remove all the books on top of it. This way of handling data is known as FILO, or First In, Last Out.
如果您开始将一本书籍放在另一本书籍上,则可以将此数据结构视为一堆书籍,一旦想要获得一本书籍,就必须删除所有书籍。 这种处理数据的方式称为FILO(先进先出)。
In other words, the first book you put on your table, will be the last one you’ll retrieve, considering you have to get all the ones on top of it first.
换句话说,考虑到必须首先将所有书籍放在桌子上,您放到桌上的第一本书将是您将检索的最后一本书。
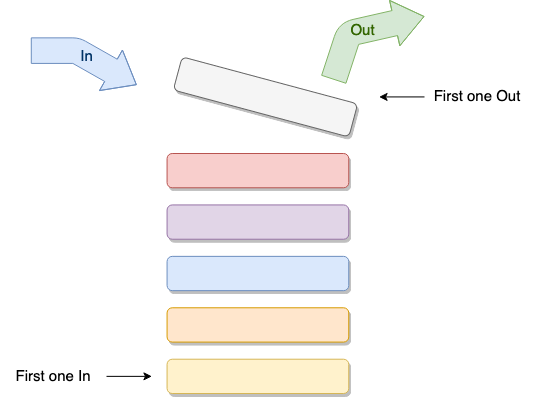
Stacks are useful for thing such as reversing the order of a list, since you can traverse your list from first to last and store each element into a stack, then you’ll start popping them out (taking the out following the FILO pattern) and the last one out will the original list’s first element.
堆栈对于反转列表的顺序很有用,因为您可以从头到尾遍历列表并将每个元素存储到堆栈中,然后开始弹出它们(按照FILO模式取出)最后一个将是原始列表的第一个元素。
Another interesting use case is one we’ve seen countless times without actually realizing it: undo. If you want to undo something, you’re either trying to undo your last action or you’re trying to undo several actions in order to undo one that happened a while ago. In either case, you’re literally popping elements off of a stack of actions.
另一个有趣的用例是我们无数次未实际意识到的用例:撤消。 如果要撤消某些操作,则要撤消上一个操作,或者要撤消几个操作以撤消前一段时间发生的操作。 无论哪种情况,您实际上都是从一系列操作中弹出元素。
Let’s first look at an undo stack example:
我们首先来看一个撤消堆栈示例:
You can see how we’re using a custom stack, one that makes use of a traditional one but also keeps track of a parallel value. The operations are represented as classes, all of them having two methods: apply which makes the operation effective and undo which represents the opposite operation. Our custom stack also has the undo method, which takes advantage of the stack structure where all operations are stored and is capable of undoing their effects, one by one. The result of executing the above code is:
您可以看到我们如何使用自定义堆栈,该堆栈使用了传统堆栈,但也跟踪了并行值。 这些操作以类表示,它们全部具有两种方法: apply使操作有效,而undo则代表相反的操作。 我们的自定义堆栈还具有undo方法,该方法利用存储所有操作的堆栈结构的优势,并且能够逐一取消其作用。 执行以上代码的结果是:
Current value: 4
Final value: 1And as you’ve probably guessed, the implementation of the stack is almost identical to the queue class from before:
正如您可能已经猜到的,堆栈的实现与之前的队列类几乎相同:
Can you spot the only difference? Check outline 27, luckily for us, the Array class from JavaScript also provides us with the pop method, which does what we’d expect: it removes the last added item on the array and returns it.
您能发现唯一的区别吗? 幸运的是,请检查大纲27,JavaScript的Array类还为我们提供了pop方法,该方法可以实现我们所期望的:删除数组上最后添加的项并返回它。
Stacks and Queues are cool, but let’s look at something a bit more complex, yet a lot more powerful and versatile as well, shall we?
堆栈和队列很酷,但是让我们看一下更复杂的东西,但是它也更强大,更通用。
树木 (Trees)
There is a lot of theory behind Trees to define what they are, how they’re formed and for what they can be used. I’m not going to get into that, because honestly, if you want theory, just hit Wikipedia or one of the many books that cover them in detail.
树背后有很多理论来定义它们是什么,它们的形成方式以及它们的用途。 我不打算讨论这个问题,因为说实话,如果您想要理论,请访问Wikipedia或详细介绍它们的众多书籍之一。
Instead, I’m going to give you the abbreviated version so you get a taste of what these bad boys can do, and if you end up liking them, you can digg as deep as you’d like.
相反,我将为您提供缩写版本,以便您了解这些坏男孩的所作所为,如果最终喜欢上这些坏男孩,则可以根据需要进行深入挖掘。
A tree is basically a recursively defined structure formed by a parent node and a number of child nodes connected to one parent. Like I said, this is a recursive definition in the sense that each of those child nodes can at the same time, be parent nodes to other children.
树基本上是由父节点和连接到一个父节点的多个子节点形成的递归定义的结构。 就像我说的那样,从每个子节点可以同时成为其他子节点的父节点的意义上来说,这是一个递归定义。
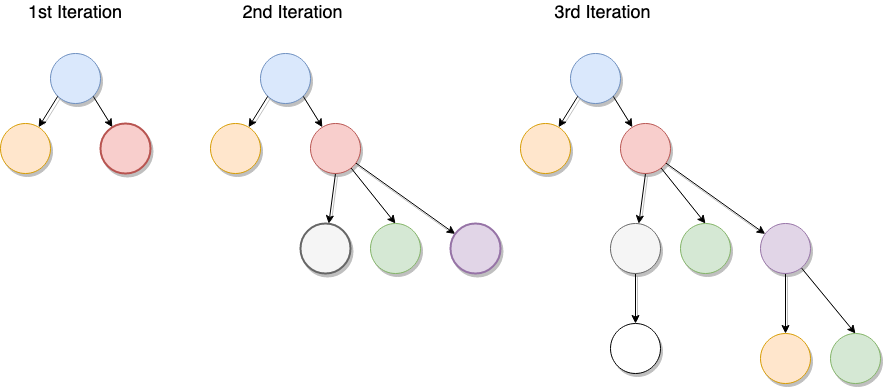
Take the above diagram shows how the tree grows, there are a few interesting things to note:
拿上面的图显示树是如何生长的,有一些有趣的事情要注意:
- Sibling nodes (i.e nodes with the same parent) don’t connect with each other. 兄弟节点(即具有相同父节点的节点)不会相互连接。
- The tree is normally represented growing downwards (as opposed to a normal tree growing up). 通常将树表示为向下生长(与正常树相反)。
- Nodes can’t be connected to themselves (I know, it sounds weird but wait until we get to graphs). 节点无法连接到自身(我知道,这听起来很奇怪,但要等到获得图表之后再说)。
Just to clarify the nomenclature for the future, the different sections of the Tree are known as:
为了澄清未来的术语,树的不同部分被称为:
Root node / Parent Node: A node with children under it.
根节点/父节点:在其下有子节点的节点。
Leaf node: A node with no children nodes associated with it.
叶节点 :没有与其关联的子节点的节点。
Edge: The link between two nodes.
边缘 :两个节点之间的链接。
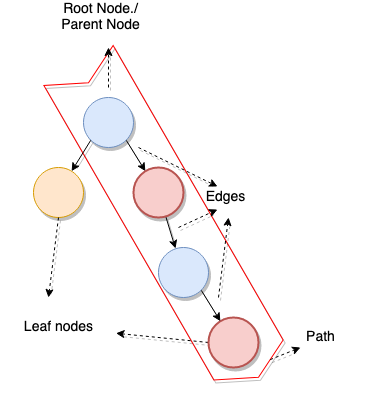
And from the diagram below, we can also define a few more things:
从下面的图表中,我们还可以定义一些其他内容:
Path: A list of nodes required to go from the root node to a destination node.
路径 :从根节点到目标节点所需的节点列表。
Height of a tree: The amount of nodes forming the largest path between the root node and the furthest leaf node.
树的高度 :在根节点和最远的叶节点之间形成最大路径的节点数。
That being said, there are several different types of trees depending on the logic associated with the data insertion and extraction from the structure:
就是说,根据与数据插入和从结构中提取数据相关的逻辑,有几种不同类型的树:
Binary Trees: these are trees in which parent nodes can only have up to two children (hence the binary). One potential use case for this type of tree is compression algorithms. They’re also used to create Binary Search Trees.
二进制树 :这些树中的父节点最多只能有两个子节点(因此为二进制)。 这种树的一种潜在用例是压缩算法。 它们还用于创建二进制搜索树。
Binary Search Trees: a special kind of BT, when inserting an element into the tree, the logic will compare it with the root node’s value and if its less than, it’ll go check on the left child, otherwise it’ll check on the right one. This logic is repeated until you either find a leaf node and link the new value to it as a child, or find an empty spot for a child of a parent. The classic use case for these is to keep a sorted structure of elements with very little effort.
二进制搜索树 :一种特殊的BT,当在树中插入一个元素时,逻辑将把它与根节点的值进行比较,如果小于,它将去检查左边的孩子,否则去检查正确的那一个。 重复此逻辑,直到您找到叶子节点并将其作为子节点链接到该值,或者找到父节点的子节点的空白点。 这些的经典用例是非常轻松地保持元素的排序结构。
Depth First Search (DFS): This is a way of combing through a tree looking for something. The way it works is you first traverse the entire left side first and then backtrack to the last visited parent and move on to the right sub-tree.
深度优先搜索(DFS):这是梳理一棵树寻找某种东西的一种方式。 它的工作方式是,您首先先遍历整个左侧,然后回溯到最后访问的父级,然后移至右侧的子树。
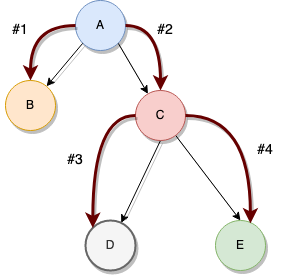
Look at the above diagram, if you were to print the value of each node when you get to it, you’d get: A->B->C->D->E. The order of nodes is determined by the DFS method:
看上图,如果要在到达每个节点时打印每个节点的值,则会得到:A-> B-> C-> D-> E。 节点的顺序由DFS方法确定:
1. Print A
2. Go to the left child
3. Print B
4. No more children, so backtrack to A
5. Go to the right child
6. Print C
7. Go left
8. Print D
9. No children, so back to C
10. Go right
11. Print E
12. EndYou can also traverse it in the reverse order, going right first and then left. This algorithm can be used both with trees and graphs to explore topological representations (amongst other use cases), such as a maze and by trying to find the path between the root node (the entrance) and the one representing the exit.
您也可以按相反的顺序遍历,先右移然后左移。 此算法可与树和图一起使用,以探索拓扑表示(在其他用例中),例如迷宫,并尝试查找根节点(入口)与代表出口的路径之间的路径。
I know this sounds like I lot, but let me show you an example of how you’d implement a Binary Search Tree (one of my favorite kinds of trees) to see how they’re not that complex and are actually very useful.
我知道这听起来很像,但让我向您展示一个示例,说明如何实现二叉搜索树(我最喜欢的树之一),以了解它们并不那么复杂,而且实际上非常有用。
But first, let me show you how you’d use our tree structure so you get a better idea on what we’re implementing:
但是首先,让我向您展示如何使用我们的树形结构,以便您更好地了解我们正在实施的内容:
That’s the benefit of a sort on insertion structure, you’re sorting while adding the numbers, so when you want to print them, it’s just a matter of traversing the structure. Look at the implementation:
这是对插入结构进行排序的好处,即在添加数字的同时进行排序,因此当您要打印它们时,只需遍历结构即可。 看一下实现:
I know it’s a long wall of code, but the longest and most complex method here is the add method. Which is mostly comprised of a do...while loop that traverses the tree looking for an empty space to place the new value. There are other operations that you might want to implement such as a find or a remove method.
我知道这是一长串代码,但是这里最长,最复杂的方法是add方法。 它主要由do...while循环组成,该循环遍历树,以寻找空白空间来放置新值。 您可能还需要执行其他操作,例如find或remove方法。
The inorder method is just a quick recursive implementation of the traversing order (left, then center, then right). You could potentially traverse it in reverse order (or postorder) by switching the left and right children.
该inorder方法仅仅是一个快速递归实现遍历顺序(左,然后中间,然后用鼠标右键)。 您可以通过切换左右两个子元素来以相反的顺序(或后顺序)遍历它。
Let’s now move on to the older brother of trees: graphs.
现在让我们继续介绍树木的哥哥: graphs 。
图表 (Graphs)
A graph is a less restricted version of a tree in the sense that there aren’t parents and children, rather any node can be related to any other (including themselves!).
在没有父母和孩子的意义上,图是树的限制较少的版本,而是任何节点都可以与任何其他节点(包括他们自己!)相关。
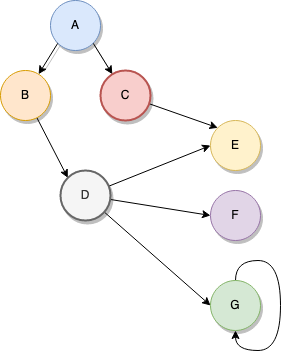
Graphs are very versatile since they can be used to represent almost any scenario in which entities are connected with each other. And I’m talking about use cases that range from network layouts to microservice-based architectures, to real-world maps, to anything you can really imagine.
图的用途非常广泛,因为它们可用于表示实体相互连接的几乎所有场景。 我说的是用例,范围从网络布局到基于微服务的体系结构,再到真实世界的地图,再到您可以想象的任何事物。
This is so much so, that there are whole database engines that are based around the concept of graphs (Neo4J for instance is a very popular one). All concepts from Trees we just covered such as edges, nodes, paths and so on are still valid here.
如此之多,以至于整个数据库引擎都基于图的概念(例如Neo4J是一种非常流行的引擎)。 我们刚刚涵盖的树中的所有概念(例如边,节点,路径等)在这里仍然有效。
Here is a quick and dirty implementation of a Graph in JavaScript, including a method showing how to implement a Depth First Search traversal (check the Trees section to understand what that is).
这是JavaScript中图形的快速而肮脏的实现,包括一种显示如何实现深度优先搜索遍历的方法(请查看“树”部分以了解其含义)。
Essentially, each Node has a list of “links”, which represent the relationship between two nodes. And in fact, as an added bonus, these are weighted links, which mean you can add value to the relationship representing whatever you want (for instance, the ms delay of a network connection, the amount of traffic between two locations, or literally anything you’d like).
本质上,每个节点都有一个“链接”列表,它们表示两个节点之间的关系。 实际上,作为额外的好处,这些是加权链接,这意味着您可以为代表所需关系的关系增加价值(例如,网络连接的ms延迟,两个位置之间的流量或几乎所有内容)你想)。
The dfs the method will take care of traversing our graph making sure we only visit each node once. Here is an example of how to use it:
dfs方法将遍历我们的图,确保我们只访问每个节点一次。 这是一个如何使用它的示例:
The above example represents the graph shown at the start of this section, including G’s relationship with itself! The output should be something like this:
上面的示例代表了本节开头显示的图形,包括G与自身的关系! 输出应该是这样的:
A
B
D
E
F
G
CIn other words, every node visited, only once. You can do more interesting things with Graphs, such as implementing Dijkstra’s algorithm to find the shortest path between two nodes or going the AI route and implement a neural network. Imagination is the limit with Graphs, so don’t right them off just yet, give them a chance.
换句话说,每个节点仅访问一次。 您可以使用Graph做更多有趣的事情,例如实现Dijkstra的算法以找到两个节点之间的最短路径,或者走AI路线并实现神经网络 。 想象力是Graphs的极限,所以不要暂时纠正它们,给它们一个机会。
哈希图 (Hash Map)
The last data structure I’ll be covering in this article is Hash Map, essentially it allows you to store key-value pairs and retrieve them farely quickly (one would say it has an order of complexity of O(1) best case scenario which is amazing).
我将在本文中讨论的最后一个数据结构是Hash Map,从本质上讲,它允许您存储键值对并快速检索它们(有人会说它的复杂度为O(1)最佳情况),是惊人的)。
Consider this: you have 300 key-value pairs you need to store in memory, you can easily resort to an array for that, the problem? If you need a particular one to be retrieved, you’ll need to traverse the entire array looking for it (this would be worst-case scenario considering the element you’re looking for is the last one). Of course, 300 elements is not a big deal, but consider a theoretical use case where you’d need to look for a single element inside a list of 1.000.000 elements. That would take a while, and if the base number keeps growing, arrays are less and less useful in this case.
考虑一下:您需要将300个键值对存储在内存中,您可以轻松地为此求助于数组,这是问题吗? 如果需要检索特定的数组,则需要遍历整个数组以寻找它(考虑到要查找的元素是最后一个元素,这是最坏的情况)。 当然,300个元素并不是什么大问题,但是考虑一个理论用例,您需要在1.000.000个元素的列表中查找单个元素。 这将需要一段时间,并且如果基数保持增长,则在这种情况下,数组的用途将越来越少。
Hash maps on the other hand, allow you to create a structure which you can use where the key can be utilized to quickly access the value in constant time. In JavaScript, implementing a hash map is considerably easy given that we have object literals which we can use to add random properties (i.e our keys). Here is a quick implementation for a hashmap that allows numeric keys to be used.
另一方面,哈希映射允许您创建一个结构,可以在其中使用键来在恒定时间内快速访问该值。 在JavaScript中,实现哈希映射非常容易,因为我们有对象文字可以用来添加随机属性(即键)。 这是一个允许使用数字键的哈希映射的快速实现。
The output from the above script is:
上面脚本的输出是:
HashMap {
map: { '0': [ 'hello' ], '1': [ 'world', 'this is a string' ] }
}Notice how both "world" and "this is a string" are associated to the same key, this is what is known as a hash collision. My hash method is simply doing a mod 10, to make sure we’re keeping up to 10 keys at any given time, no matter what the original key is. This is helpful if you have a limited amount of memory or for some reason need to keep a tight control over the keys. The way you implement your hashing method will determine how effective your hash map ends up being.
注意"world"和"this is a string"如何与同一个键相关联,这就是所谓的哈希冲突。 我的hash方法只是做一个mod 10,以确保无论给定原始密钥是什么,在任何给定时间都最多保留10个密钥。 如果您的内存量有限,或者由于某些原因需要严格控制按键,这将很有帮助。 实现散列方法的方式将确定散列图最终的有效性。
If well implemented this structure is so efficient that it is widely used in scenarios such as database indexing (normally you set fields as indexes when you want a quick lookup operation) and even cache implementations, allowing, again, quick lookup operations in order to retrieve the cached content. As you’ve probably guessed, this is a great structure if you’re looking to have quick and repeated lookups.
如果实施得当,该结构将非常有效,以至于广泛用于数据库索引(通常在需要快速查找操作时将字段设置为索引)等场景,甚至还可以缓存实现,从而允许快速查找操作以进行检索缓存的内容。 正如您可能已经猜到的,如果您希望进行快速且重复的查找,那么这是一个很好的结构。
结论 (Conclusion)
Understanding data structures whether you use them on your day-to-day tasks or not is very important because they open up your eyes at patterns that you’re already working with, even if you don’t know it.
了解数据结构是否在日常任务中使用它们非常重要,因为即使您不知道它们,它们也会让您看到已经在使用的模式。
Have some fun playing around with the implementations above and try to create your own, maybe in the process you’ll come up with solutions to problems you already have and don’t know how to solve!
在上面的实现中玩一些乐趣,并尝试创建自己的实现,也许在此过程中,您将提出解决方案,以解决已经存在的问题并且不知道如何解决!
Which one is your favorite data structure? Leave a comment down below and share it with everyone!
您最喜欢的数据结构是哪一个? 在下方留言,并与大家分享!
Until then, see you at the next one!
在那之前,下一个见!
学到更多 (Learn More)
翻译自: https://blog.bitsrc.io/data-structures-you-should-know-as-a-javascript-developer-9a35eb3b319c















 6206
6206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









