





Playwright is a browser automation library very similar to Puppeteer. Both allow you to control a web browser with only a few lines of code. The possibilities are endless. From automating mundane tasks and testing web applications to data mining.
Playwright是一个非常类似于Puppeteer的浏览器自动化库。 两者都允许您仅用几行代码来控制Web浏览器。 可能性是无止境。 从自动化普通任务和测试Web应用程序到数据挖掘。
With Playwright you can run Firefox and Safari (WebKit), not only Chromium based browsers. It will also save you time, because Playwright automates away repetitive code, such as waiting for buttons to appear in the page.
使用Playwright,您不仅可以运行基于Chromium的浏览器,还可以运行Firefox和Safari(WebKit)。 这也可以节省您的时间,因为Playwright会自动删除重复代码,例如等待按钮出现在页面中。
You don’t need to be familiar with Playwright, Puppeteer or web scraping to enjoy this tutorial, but knowledge of HTML, CSS and JavaScript is expected.
您无需熟悉Playwright,Puppeteer或Web抓取即可享受本教程的知识,但是需要具备HTML,CSS和JavaScript的知识。
In this tutorial you’ll learn how to:
在本教程中,您将学习如何:
Start a browser with Playwright
使用Playwright启动浏览器
Click buttons and wait for actions
单击按钮并等待操作
Extract data from a website
从网站提取数据
该项目 (The Project)
To showcase the basics of Playwright, we will create a simple scraper that extracts data about GitHub Topics. You’ll be able to select a topic and the scraper will return information about repositories tagged with this topic.
为了展示Playwright的基础知识,我们将创建一个简单的刮板,以提取有关GitHub Topics的数据。 您将能够选择一个主题,刮板将返回有关带有该主题标记的存储库的信息。
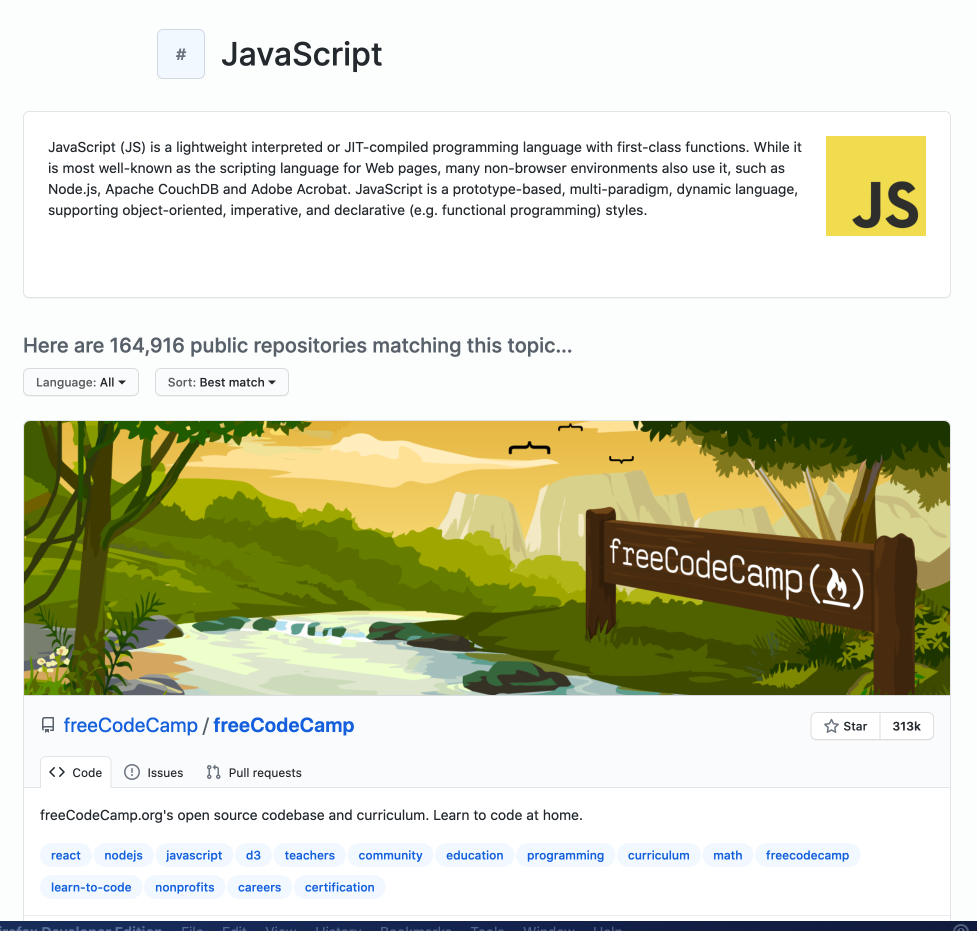
We will use Playwright to start a browser, open the GitHub topic page, click the Load more button to display more repositories, and then extract the following information:
我们将使用Playwright启动浏览器,打开GitHub主题页面,单击“ 加载更多”按钮以显示更多存储库,然后提取以下信息:
- Owner 所有者
- Name 名称
- URL 网址
- Number of stars 星数
- Description 描述
- List of repository topics 存储库主题列表
安装 (Installation)
To use Playwright you’ll need Node.js version higher than 10 and a package manager. We’ll use npm, which comes preinstalled with Node.js. You can confirm their existence on your machine by running:
要使用Playwright,您需要高于10的Node.js版本和一个程序包管理器。 我们将使用npm ,它预装了Node.js。 您可以通过运行以下命令确认它们在计算机上的存在:
node -v && npm -vIf you’re missing either Node.js or NPM, visit the installation tutorial to get started.
如果缺少Node.js或NPM,请访问安装教程以开始使用。
Now that we know our environment checks out, let’s create a new project and install Playwright.
现在我们知道我们的环境已经签出,让我们创建一个新项目并安装Playwright。
mkdir playwright-scraper && cd playwright-scraper
npm init -y
npm i playwrightThe first time you install Playwright, it will download browser binaries, so the installation may take a bit longer.
首次安装Playwright时,它将下载浏览器二进制文件,因此安装可能需要更长的时间。
建造刮板 (Building a scraper)
Creating a scraper with Playwright is surprisingly easy, even if you have no previous scraping experience. If you understand JavaScript and CSS, it will be a piece of cake.
使用Playwright创建刮板非常容易,即使您以前没有刮板经验也是如此。 如果您了解JavaScript和CSS,那将是小菜一碟。
In your project folder, create a file called scraper.js (or choose any other name) and open it in your favorite code editor. First, we will confirm that Playwright is correctly installed and working by running a simple script.
在项目文件夹中,创建一个名为scraper.js的文件(或选择其他名称),然后在您喜欢的代码编辑器中将其打开。 首先,我们将通过运行一个简单的脚本来确认Playwright已正确安装并正常工作。
Now run it using your code editor or by executing the following command in your project folder.
现在,使用代码编辑器或在项目文件夹中执行以下命令来运行它。
node scraper.jsIf you saw a Chromium window open and the GitHub Topics page successfully loaded, congratulations, you just robotized your web browser with Playwright!
如果您看到打开了Chromium窗口并且成功加载了GitHub Topics页面,那么恭喜,您只是使用Playwright对您的Web浏览器进行了自动化!
加载更多存储库 (Loading more repositories)
When you first open the topic page, the number of displayed repositories is limited to 30. You can load more by clicking the Load more… button at the bottom of the page.
首次打开主题页面时,显示的存储库数限制为30。您可以通过单击页面底部的“ 加载更多…”按钮来加载更多存储库。
There are two things we need to tell Playwright to load more repositories:
我们需要告诉Playwright加载更多存储库的两件事:
Click the Load more… button.
点击 加载更多...按钮。
Wait for the repositories to load.
等待存储库加载。
Clicking buttons is extremely easy with Playwright. By prefixing text= to a string you’re looking for, Playwright will find the element that includes this string and click it. It will also wait for the element to appear if it’s not rendered on the page yet.
使用Playwright,单击按钮非常容易。 通过在要查找的字符串前添加text=前缀,Playwright会找到包含该字符串的元素,然后单击它。 如果该元素尚未在页面上呈现,它还将等待该元素出现。

This is a huge improvement over Puppeteer and it makes Playwright lovely to work with.
与Puppeteer相比,这是一个巨大的进步,它使Playwright变得很可爱。
After clicking, we need to wait for the repositories to load. If we didn’t, the scraper could finish before the new repositories show up on the page and we would miss that data. page.waitForFunction() allows you to execute a function inside the browser and wait until the function returns true .
单击后,我们需要等待存储库加载。 如果我们不这样做,那么刮板可能会在新存储库出现在页面上之前完成,否则我们将丢失该数据。 page.waitForFunction()允许您在浏览器中执行一个函数,并等待该函数返回true 。
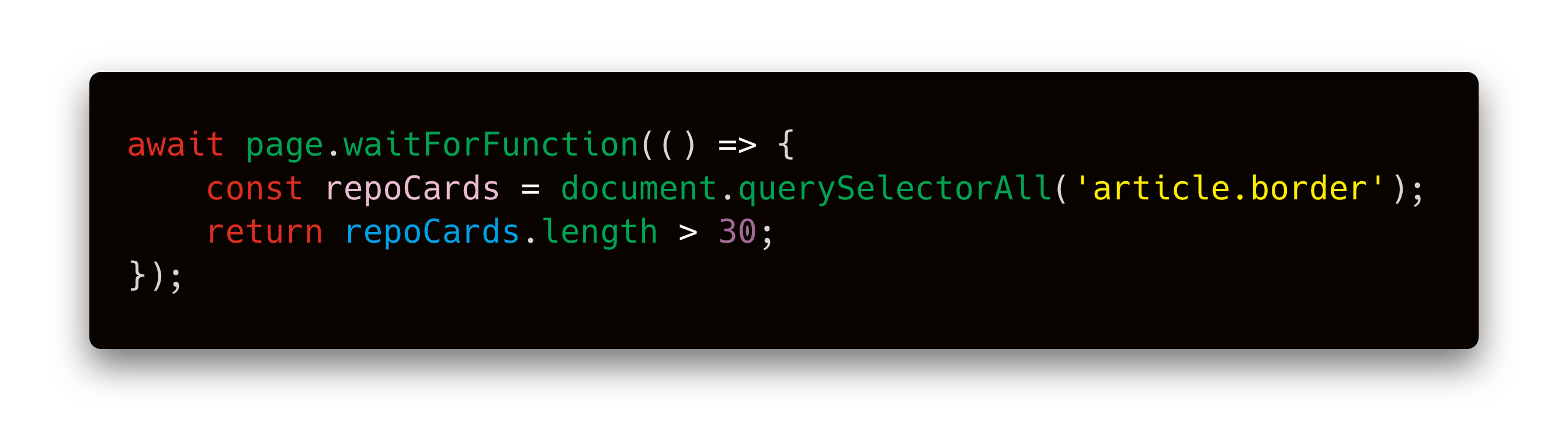
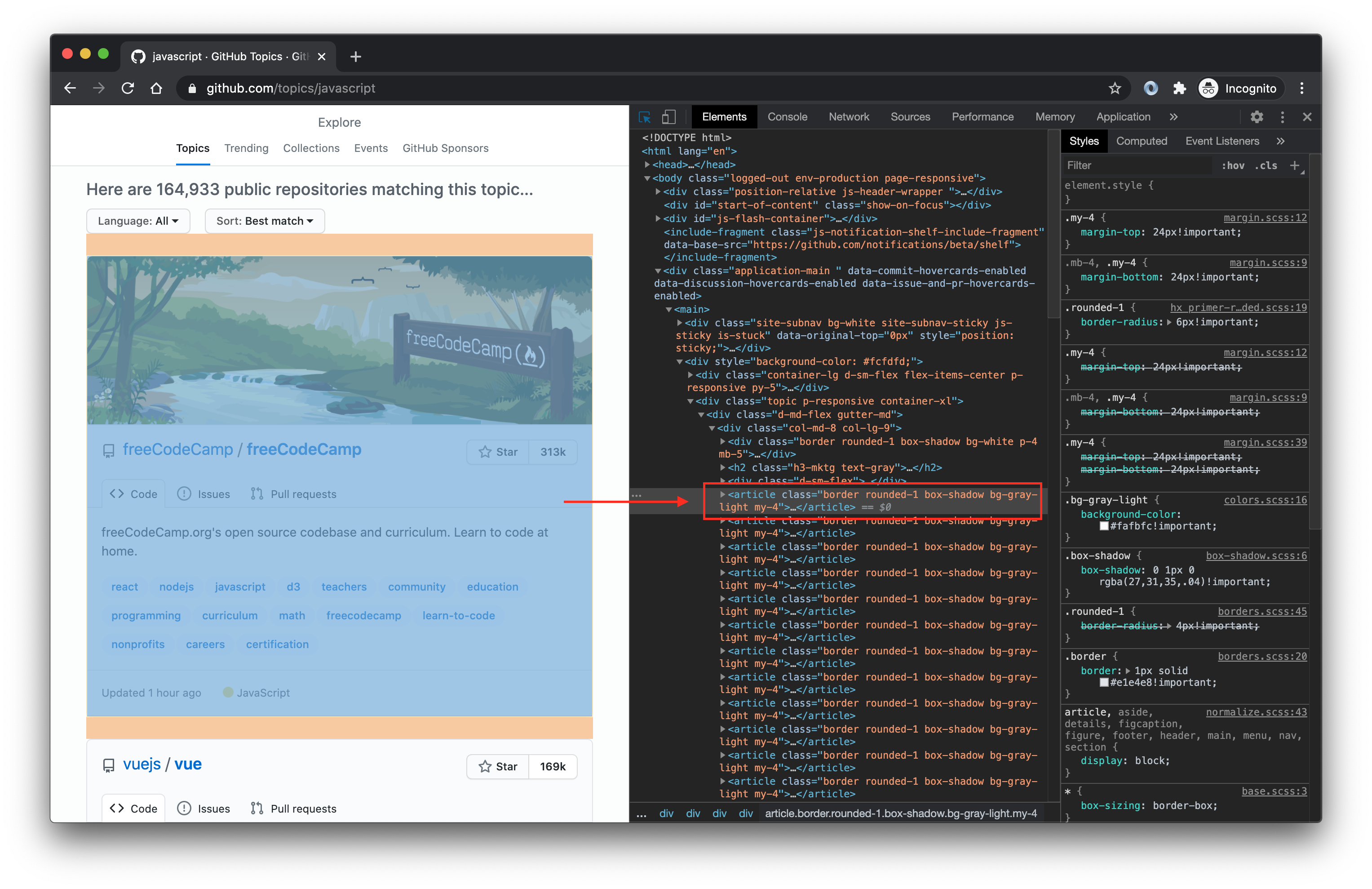
To find that article.border selector, we used browser Dev Tools, which you can open in most browsers by right-clicking anywhere on the page and selecting Inspect. It means: Select the <article> tag with the border class.
为了找到article.border选择器,我们使用了浏览器开发工具,您可以在大多数浏览器中打开该工具,方法是右键单击页面上的任意位置,然后选择检查 。 这意味着:选择带有border类的<article>标签。
Let’s plug this into our code and do a test run.
让我们将其插入我们的代码中并进行测试运行。
If you watch the run, you’ll see that the browser first scrolls down and clicks the Load more… button, which changes the text into Loading more. After a second or two, you’ll see the next batch of 30 repositories appear. Great job!
如果观看了运行,您会看到浏览器首先向下滚动并单击Load more…按钮,该按钮将文本更改为Loading more 。 一两秒钟后,您将看到下一批的30个存储库。 很好!
提取数据 (Extracting data)
Now that we know how to load more repositories, we will extract the data we want. To do this, we’ll use the page.$$eval function. It tells the browser to find certain elements and then execute a JavaScript function with those elements.
现在我们知道了如何加载更多存储库,我们将提取所需的数据。 为此,我们将使用page.$$eval函数。 它告诉浏览器找到某些元素,然后使用这些元素执行JavaScript函数。
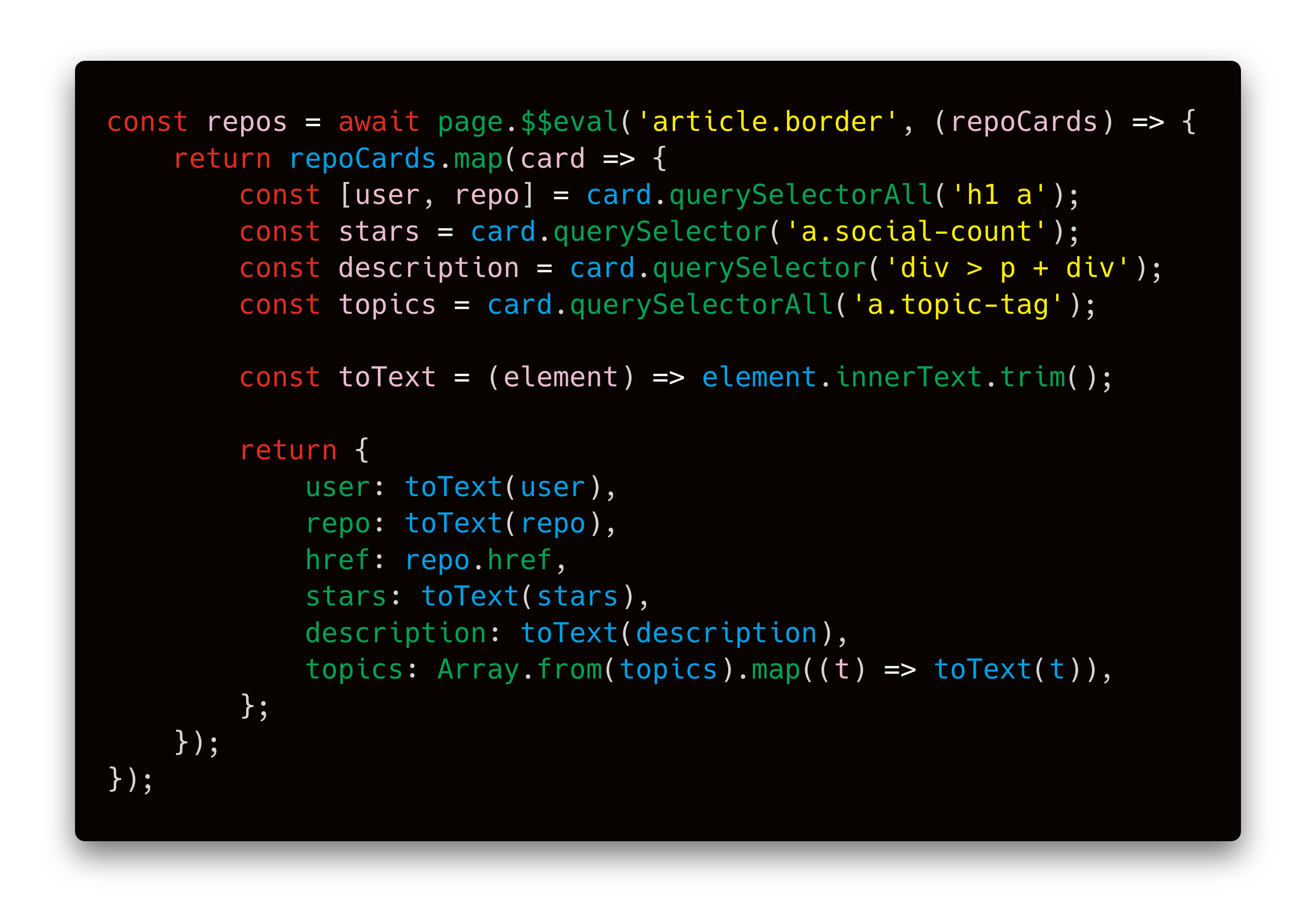
It works like this: page.$$evalfinds our repositories and executes the provided function in the browser. We get repoCards which is an Array of all the repo elements. The return value of the function becomes the return value of the page.$$eval call. Thanks to Playwright, you can pull data out of the browser and save them to a variable in Node.js. Magic!
它的工作方式如下: page.$$eval查找我们的存储库并在浏览器中执行提供的功能。 我们得到repoCards ,它是所有repo元素的Array 。 函数的返回值成为page.$$eval调用的返回值。 感谢Playwright,您可以将数据从浏览器中拉出并将其保存到Node.js中的变量中。 魔法!
If you’re struggling to understand the extraction code itself, be sure to check out this guide on working with CSS selectors and this tutorial on using those selectors to find HTML elements.
如果您在努力理解提取代码本身,请务必查看有关使用CSS选择器的 指南以及使用这些选择器查找HTML元素的本教程 。
And here’s the code with extraction included. When you run it, you’ll see 60 repositories with their information printed to the console.
这是包含提取的代码。 运行它时,您将看到60个存储库,并将其信息打印到控制台。
结论 (Conclusion)
In this tutorial we learned how to start a browser with Playwright, and control its actions with some of Playwright’s most useful functions: page.click() to emulate mouse clicks, page.waitForFunction() to wait for things to happen and page.$$eval() to extract data from a browser page.
在本教程中,我们学习了如何使用Playwright启动浏览器,以及如何使用Playwright的一些最有用的功能控制浏览器的操作: page.click()以模拟鼠标单击, page.waitForFunction()以等待事件发生和page.$$eval()从浏览器页面提取数据。
But we’ve only scratched the surface of what’s possible with Playwright. You can log into websites, fill forms, intercept network communication, and most importantly, use almost any browser in existence. Where will you take this project next? How about turning it into a command-line interface (CLI) tool that takes a topic and number of repositories on input and outputs a file with the repositories? You can do it now. Happy scraping!
但是,我们仅涉及Playwright可能实现的功能。 您可以登录网站,填写表格,拦截网络通信,最重要的是,可以使用几乎任何现有的浏览器。 接下来您将在哪里进行此项目? 如何将其转换为命令行界面(CLI)工具,该工具在输入中获取主题和存储库数量,并输出包含该存储库的文件? 您现在就可以做到。 刮刮乐!
翻译自: https://blog.apify.com/how-to-scrape-the-web-with-playwright-ece1ced75f73















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









