





I have heard many people say we should scale applications horizontally rather than vertically, but is this actually the best way to scale? In this article, we will explore how Node.js scales with CPU and see if there is anything else we need to take into account if we do so.
我听过很多人说我们应该水平而不是垂直扩展应用程序,但这实际上是扩展的最佳方法吗? 在本文中,我们将探讨Node.js如何随CPU扩展,并查看是否还有其他需要考虑的因素。
测试基础架构 (Test Infrastructure)
To test Node.js, a demo application was created with endpoints that could be used to simulate a load. The application is Dockerised and can be found on the Docker Hub. The source code can be found on GitHub.
为了测试Node.js,创建了一个演示应用程序,其中包含可用于模拟负载的端点。 该应用程序是Dockerized的,可以在Docker Hub上找到。 可以在GitHub上找到源代码。
The application was deployed on AWS ECS with different CPU limits and a load balancer was put in front to make it publicly accessible. The code used to deploy this infrastructure can be found on GitHub. If you would like to spin it up yourself, check out the repository and run yarn build to build the CloudFormation stack. Then run yarn cdk deploy. The different instances are deployed at <loadbalancer DNS>/<CPU>, where CPU is one of 256, 512, 1024, or 2048. Once you have finished, you can delete everything with yarn cdk delete.
该应用程序已部署在具有不同CPU限制的AWS ECS上,并且负载均衡器位于前面,以使其可公开访问。 可以在GitHub上找到用于部署此基础架构的代码。 如果您想自己旋转它,请签出存储库并运行yarn build来构建CloudFormation堆栈。 然后运行yarn cdk deploy 。 的不同实例在部署<loadbalancer DNS>/<CPU>其中CPU是一个256 , 512 , 1024 ,或2048 。 完成后,您可以使用yarn cdk delete删除所有内容。
负载测试 (Load Test)
Artillery was used to load test the application starting at one request per second (RPS) and ramping up to 40 RPS over four minutes. By slowly ramping up over four minutes, we can more accurately see at which point the application starts to fail. This was repeated four times — once for each CPU size. The Artillery file and the results for all the tests can be found on GitHub. You will find .html files that can be downloaded to see the graphs. If you want the raw output, have a look at the .json files in the same directory. The endpoint that was tested was computing the 30th Fibonacci number. This is a computationally expensive task to complete, simulating a real-world application doing work.
大炮用于对应用程序进行负载测试,从每秒一个请求(RPS)开始,并在四分钟内提高到40 RPS。 通过缓慢启动四分钟,我们可以更准确地看到应用程序在哪一点开始失败。 重复了四次-每个CPU大小一次。 大炮文件和所有测试的结果都可以在GitHub上找到 。 您会找到可以下载以查看图表的.html文件。 如果要原始输出,请查看同一目录中的.json文件。 被测试的端点正在计算第30个斐波那契数。 模拟现实世界中正在工作的应用程序,这是一项计算量巨大的任务。
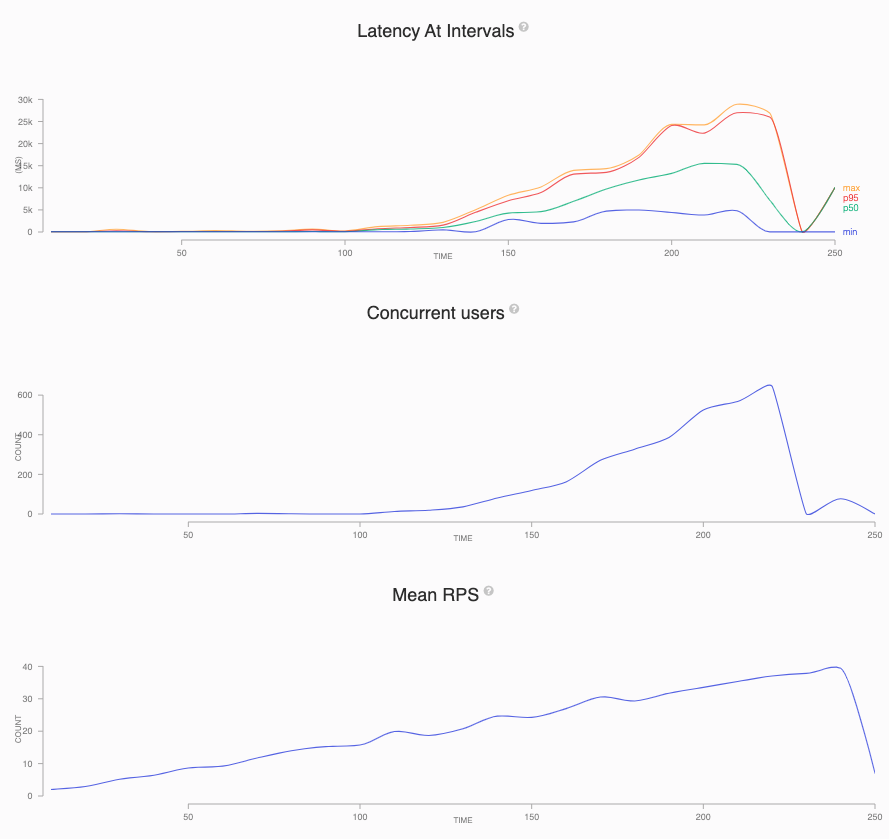
The graphs below are from the 512 CPU test. The latency and concurrent users remain flat for the first part of the test. This shows the application is performing well and handling the load. Once the service becomes overwhelmed, the latency and concurrent users increase. Note how the concurrent user increases look exponential. The latency also increases dramatically from about 50 ms to over five seconds once the service has hit its limit. Once the service is receiving requests faster than it can process, the requests back up, which makes the service slower and causes more requests to back up.
下图来自512 CPU测试。 在测试的第一部分,等待时间和并发用户保持不变。 这表明应用程序运行良好并且正在处理负载。 一旦服务不堪重负,延迟和并发用户就会增加。 注意并发用户如何增加外观。 一旦服务达到极限,延迟也会从大约50毫秒急剧增加到超过五秒。 一旦服务接收到的请求快于其处理速度,就将备份请求,这会使服务变慢并导致更多的请求备份。
结果 (Results)
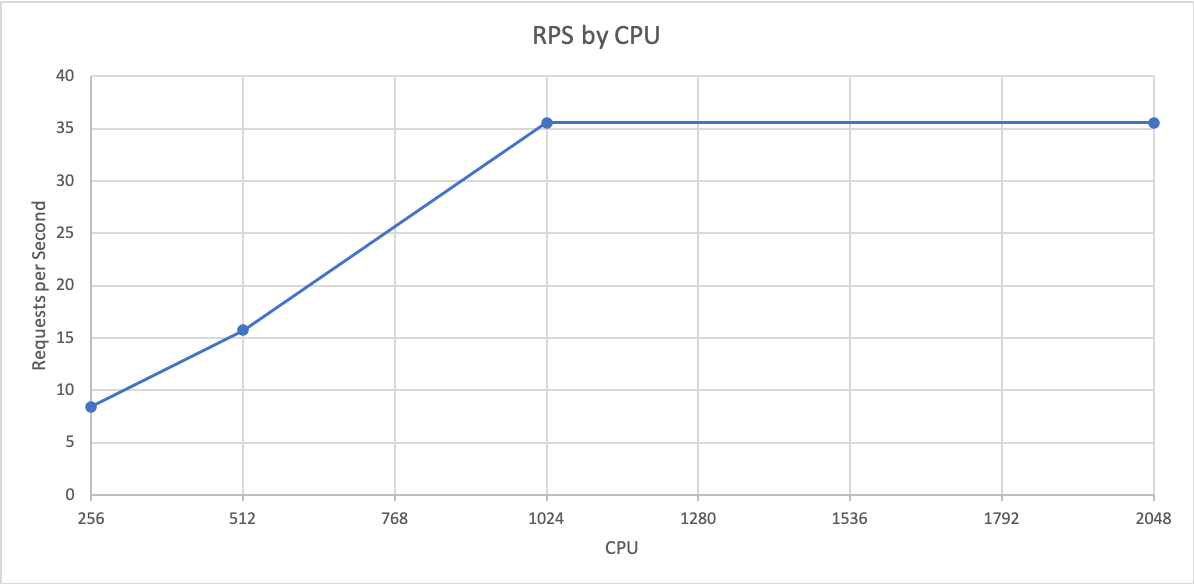
After plotting the point at which each CPU’s test started to fail (when the concurrent users and response time increased), we can see that Node.js scales linearly with CPU. This means that in most cases, there is no benefit in terms of RPS per CPU to increasing the CPU. The graph below plots this. Note that there is no increase between 1024 and 2048. This is due to Node’s single-threaded nature. The extra CPU is sat idle. AWS Fargate charges per partial vCPU, so four 256 pods are the same price as one 1024 pod. As such, there is no financial benefit to creating larger pods.
在绘制了每个CPU的测试开始失败的时间点(并发用户和响应时间增加时)之后,我们可以看到Node.js与CPU呈线性比例关系。 这意味着在大多数情况下,就每个CPU的RPS而言,增加CPU没有任何好处。 下图显示了这一点。 请注意,在1024和2048之间没有增加。 这是由于Node的单线程性质。 额外的CPU处于闲置状态。 AWS Fargate对每个部分vCPU收费,因此四个256 Pod与一个1024 pod的价格相同。 因此,创建更大的吊舱没有经济利益。
As mentioned previously, when the application cannot handle the load, the concurrent requests and response time shoot up. If we use these metrics to autoscale on, by the time the metric has increased and we ask to scale up, the service is already affecting customers. The solution to this is to scale on RPS and set the value before the other metrics are affected. This maintains a good customer experience and allows some breathing room to be added.
如前所述,当应用程序无法处理负载时,并发请求和响应时间会激增。 如果我们使用这些指标进行自动扩展,那么当该指标增加并要求扩展时,该服务已经在影响客户。 解决方案是在其他指标不受影响之前按RPS缩放并设置值。 这样可以保持良好的客户体验,并可以增加一些呼吸空间。
水平扩展的好处 (Benefits of Horizontal Scaling)
The main benefit is cost. We are asking for a more precise amount of resources. This means there is less waste. If we could handle the load with half a CPU but only scale full CPUs, we are wasting the price of half a CPU.
主要好处是成本。 我们正在要求更精确的资源。 这意味着浪费更少。 如果我们可以用一半的CPU来处理负载而只扩展完整的CPU,那我们就是在浪费一半的CPU的价格。
If your service’s traffic changes throughout the day, you may scale down to the minimum amount of pods (usually two for resiliency). By keeping the CPU small, it keeps the price of your minimum cost down.
如果您的服务流量在一整天中都在变化,则可以缩小到最小Pod数量(通常为两个Pod,以实现弹性)。 通过保持较小的CPU,可以降低最低成本的价格。
By having more pods in traffic, we also increase the resiliency. If a pod fails, the load is spread across the still-running pods. If we have ten pods handling 10 RPS each and one fails, the remaining nine pods will only gain 1.1 RPS. If we only have five serving 10 RPS and one fails, the remaining pods would gain 2.5 RPS. This could be enough to overwhelm the service. Having more pods will also spread the load over more availability zones and nodes if they are available.
通过增加通信量,我们还可以提高弹性。 如果Pod发生故障,则负载将分散在仍在运行的Pod中。 如果我们有十个吊舱,每个吊舱处理10 RPS,而一个失败,则其余九个吊舱将仅获得1.1 RPS。 如果我们只有五个提供10 RPS的服务,而其中一个失败,则其余的吊舱将获得2.5 RPS。 这可能足以淹没该服务。 拥有更多的Pod还将把负载分散到更多的可用区域和节点(如果可用)上。
结论 (Conclusion)
Try to resist the urge to increase the CPU of your service. Increase the number of them instead. This will keep the cost of your application under control and also increase its resiliency. You should also autoscale your application, but be careful when using response time or concurrent requests, as this could give your customers a poor experience.
尝试抵制增加服务CPU的冲动。 而是增加它们的数量。 这将使您的应用程序成本得到控制,并提高了其弹性。 您还应该自动缩放应用程序,但是在使用响应时间或并发请求时要小心,因为这可能给您的客户带来糟糕的体验。
I hope this is the evidence you need to build cost-effective and resilient services.
我希望这是您构建具有成本效益和弹性的服务所需的证据。
翻译自: https://medium.com/better-programming/horizontal-vs-vertical-scaling-in-node-js-1b4f3ec8282















 5248
5248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









