





Once a place for posting pretty websites to promote your business, the internet has now evolved to be a forum where consumers evaluate different products and services based on impressions and feedback from other like-minded consumers. In recent times, online reviews have created a new field in marketing and communication that bridges the gap between traditional word-of-mouth and a viral form of feedback that can influence consumer’s opinions. However, in the field of medicine, reviews made for particular drugs play an even more vital role as they can help in monitoring its adverse reactions and identify an overall impression of the drug among its users.
互联网曾经是发布漂亮的网站来促进您的业务的地方,如今已发展成为一个论坛,在此论坛上,消费者可以根据印象和其他志趣相投的消费者的反馈来评估不同的产品和服务。 近年来,在线评论在营销和传播领域开辟了一个新领域,弥合了传统口碑与病毒式反馈之间的鸿沟,后者可以影响消费者的意见。 但是,在医学领域,对特定药物的审查起着更为重要的作用,因为它们可以帮助监测其不良React并确定使用者对药物的总体印象。
Since many drugs treat multiple conditions, while reviewing a medicine in most of the patient forums, it is compulsory to provide the medical condition for which the medicine is being used for.
由于许多药物治疗多种疾病,因此在大多数患者论坛中对药物进行审查时,必须提供要使用该药物的医学疾病。
A Medical Condition is a broad term that includes all diseases, lesions, disorders, or nonpathologic conditions that normally receive medical treatment, such as pregnancy or childbirth.
医学状况是一个广义术语,包括通常接受医学治疗的所有疾病,病变,病症或非病理状况,例如怀孕或分娩。
In this series of articles, we will analyze reviews made by various patients for specific drugs on different pharmaceutical review sites and predict Medical Condition, the medicine is being used to treat.
在本系列文章中,我们将分析不同患者在不同药物评论网站上针对特定药物所作的评论,并预测正在使用的药物的医疗状况 。
挑战 (Challenge)
Predicting medical condition from reviews is a very challenging task. For example, consider the following review:
从评论中预测医疗状况是一项非常艰巨的任务。 例如,考虑以下审查:
The medicine worked wonders for me. I would definitely recommend it
这种药为我创造了奇迹。 我肯定会推荐它
The medicine, for which the review is made, was used to treat Acne. However, solely based on the review, it is very difficult to identify that the patient is talking about treating Acne as there is no mention of it in the post. Since most of the patient forums ask for the name of the medical condition in a separate field in the review form, patients often do not mention it in their review.
经过审查的药物用于治疗痤疮。 但是,仅根据检查结果,很难确定患者正在谈论治疗痤疮,因为后期没有提及痤疮 。 由于大多数患者论坛都在审阅表的单独字段中询问病情的名称,因此患者通常不会在审阅中提及病情。
方法 (Approach)
To solve this problem, in this part, we will analyze reviews and use Statistical Machine Learning Classifiers to make predictions. We will use the UCI ML Drug Review dataset from Kaggle. The dataset provides patient reviews on specific drugs along with related conditions and a 10-star patient rating system reflecting overall patient satisfaction. The data was obtained by crawling online pharmaceutical review sites. The dataset consists of over 200k medicine reviews made for over 700 different medical conditions and the data is split into a train (75%) and test (25%) partition.
为了解决这个问题, 在这一部分中 ,我们将分析评论并使用统计机器学习分类器进行预测。 我们将使用Kaggle的UCI ML药物评论数据集。 该数据集提供了对特定药物的患者评论以及相关条件,以及一个反映整体患者满意度的10星级患者评分系统。 该数据是通过检索在线药品评论网站获得的。 该数据集包含针对700多种不同医疗状况进行的200,000多种医学评论,数据分为火车(75%)和测试(25%)分区。
分析数据集 (Analyzing the Dataset)
To begin, we will first import all necessary modules for our analysis and predictions.
首先,我们将首先导入所有必要的模块以进行分析和预测。
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict, StratifiedKFold
import plotly.express as px
import numpy as np
import pandas as pd
from mlxtend.plotting import plot_learning_curves
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, TfidfTransformer
from sklearn.multiclass import OneVsRestClassifier
from nltk.corpus import stopwords
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import MultinomialNB, GaussianNB
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.neighbors import KNeighborsClassifier
from nltk.stem import WordNetLemmatizer, SnowballStemmerWe will then download the data and, drop null values from it and then have a look at the training and testing dataframes. I have already downloaded the dataset from the aforementioned link and loaded it in pandas dataframes.
然后,我们将下载数据,并从中删除空值,然后查看训练和测试数据框。 我已经从上述链接下载了数据集,并将其加载到了熊猫数据框中。
# train data
df_train = pd.read_csv("/content/drive/My Drive/data/drugsComTest_raw.csv")
# test data
df_test = pd.read_csv("/content/drive/My Drive/data/drugsComTest_raw.csv")
# Removing nan values
df_train = df_train.dropna()
df_test = df_test.dropna()
df_train.head()
We see that there are 7 columns in the dataset:
我们看到数据集中有7列:
uniqueID: An identifier for each post.uniqueID:每个帖子的标识符。drugName: The name of the drug for which review is made.drugName:要进行审查的药物的名称。condition: The name of the medical condition for which the medicine is used.condition:使用该药物的医疗状况名称。review: The review made by patients for a particular medicine.review:患者对特定药物的评论。rating: Ratings, given by the patients to each medicine on a scale of 10 where 10 represents the maximum efficacy.rating:患者对每种药物给予的等级,等级为10,其中10表示最大功效。date: Date of review entry.date:评论输入的日期。usefulCount: The number of users who found the review useful.usefulCount:发现该评论有用的用户数。
Since we are interested in predicting the Medical Condition, condition will be our target variable. Let us first analyze the distribution of classes of the condition variable.
由于我们对预测医疗状况感兴趣,因此condition将是我们的目标变量。 让我们首先分析condition变量的类的分布。
We will define the following functions:
我们将定义以下功能:
def plot_bar_chart(df):
# analyze the condition labels
counts_series = df.condition.value_counts()
counts_df = pd.DataFrame(counts_series)
counts_df.reset_index(level=0, inplace=True)
number_of_classes(df)
fig = px.bar(counts_df, x="index", y="condition", orientation='v',
height=400,
title='xc')
fig.show()
def number_of_classes(df):
print("Number of classes: ", len(df["condition"].unique()))
plot_bar_chart(df_train)The plot_bar_chart first extracts the number of reviews against each class from the condition column and plot them using the functions provided by plotly. number_of_classes just prints the number of unique classes in the condition column of the dataframe.
plot_bar_chart首先从condition列中提取针对每个类的评论数量,然后使用plotly提供的功能对其进行绘制 。 number_of_classes仅在数据框的condition列中打印唯一类的数量。

There are 708 classes in the dataset (see the above snapshot) with reviews highly skewed towards the class of Birth Control indicating that the dataset is highly imbalanced. On closer inspection, it is also observed that there are some classes (highlighted in red) which are not exactly medical conditions but rather some noise which got added during the creation of the dataset. All this noise has to be removed.
数据集中有708个类别(请参见上面的快照),其评论高度偏向生育控制的类别,表明该数据集高度不平衡。 通过仔细检查,还可以观察到某些类别(以红色突出显示)并非完全属于医疗状况 ,而是一些在创建数据集期间添加的噪声。 所有这些噪音都必须消除。
标签(类)预处理 (Labels (Classes) Preprocessing)
The preprocessing of the labels consists of three steps. We will perform all the preprocessing on our training dataframe and later apply it on the test dataframe.
标签的预处理包括三个步骤。 我们将在训练数据帧上执行所有预处理,然后将其应用于测试数据帧。
步骤1:删除低频类别 (Step 1: Removing low-frequency classes)
We have already observed that the dataset is highly imbalanced. We will start the preprocessing by first removing the classes with less than 20 samples in them and then check the number of classes again in the training set.
我们已经观察到数据集高度不平衡。 我们将首先删除样本中少于20个样本的类,然后再在训练集中再次检查类数,从而开始进行预处理。
# Keeping classes which have more than 20 values in them
index_counts = df_train["condition"].value_counts()[df_train.condition.value_counts() >= 20].index
df_train = df_train[df_train["condition"].isin(index_counts)]
number_of_classes(df_train)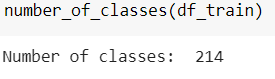
We observe a significant reduction in the number from 708 to 214 (snapshot above).
我们发现人数从708人大幅减少到214人(上面的快照)。
第2步:欠采样类别,包含200多个样本 (Step 2: Undersampling classes with more than 200 samples)
To solve the class imbalance problem, we will undersample classes with more than 200 samples. We do this by iterating through each class, extracting all its samples from the training dataframe, shuffling it, and then slicing the array to 200 elements.
为了解决类不平衡问题,我们将用超过200个样本对样本进行欠采样。 我们通过遍历每个类,从训练数据帧中提取所有样本,对其进行混洗,然后将数组切成200个元素来实现。
# undersampling all classes with samples greater than 200 to 200
condition_over200 = df_train["condition"].value_counts()[df_train.condition.value_counts() >= 200].index
for condition in condition_over200:
# randomly shuffle the samples
condition_samples = df_train[df_train["condition"]==condition]
condition_samples = condition_samples.sample(frac=1).reset_index(drop=True)
# extract only 200
condition_samples = condition_samples[:200]
df_train = df_train[df_train["condition"]!=condition]
# put it back
df_train = pd.concat([df_train, condition_samples], ignore_index=True)步骤3:从资料集中移除嘈杂的类别 (Step 3: Removing Noisy classes from the dataset)
As we have seen in the previous section that the dataset consists of classes which are just noise. The typical format of these classes are numbers followed by some text, for example, one of the noisy class in the dataset is “41 users found”. We know that Medical Conditions don’t involve numbers in them so we can easily look for alphanumeric classes in our dataset and can directly remove them to get rid of the noise.
正如我们在上一节中看到的那样,数据集由只是噪声的类组成。 这些类的典型格式是数字后跟一些文本,例如,数据集中的一个嘈杂类是“ 找到41个用户 ”。 我们知道医疗状况中不包含数字,因此我们可以轻松地在数据集中查找字母数字类,并可以直接删除它们以消除噪音。
We do this by writing a method named filter_labels which iterates through all the labels, checks whether the label is alphanumeric or not and returns a truth value based on the check. We then apply it to the training dataframe and check the number of classes.
为此,我们编写了一个名为filter_labels的方法,该方法遍历所有标签,检查标签是否为字母数字,并根据检查结果返回真值。 然后,我们将其应用于训练数据框并检查班级数量。
def filter_labels(labels):
labels = labels.tolist()
labels_truth = []
for label in labels:
if label[0].isdigit():
labels_truth.append(False)
else:
labels_truth.append(True)
return labels_truth
df_train = df_train[filter_labels(df_train["condition"])]
print("Train ", number_of_classes(df_train))
We now have only 210 classes left (snapshot above) in the training set on which we need to train our classifiers. Let's have a look at the distribution of the classes now:
现在,在我们需要训练分类器的训练集中,仅剩210个班级(上面的快照)。 现在让我们看一下这些类的分布:

The distribution looks much better than it was before. There is still high class imbalance but undersampling beyond this will result in the loss of information.
该发行版看起来比以前要好得多。 仍然存在较高的阶级失衡,但采样不足会导致信息丢失。
在测试数据集标签上应用预处理 (Applying the preprocessing on Testing Dataset Labels)
df_test = df_test[filter_labels(df_test["condition"])]
print("Test ", number_of_classes(df_test))
As we can see, there are 664 classes in the test set. The testing dataset needs to have exactly the same classes as in training data. Since our testing data is already labelled, we only keep those classes in the test set, that are present in the preprocessed training set and discard the rest.
我们可以看到,测试集中有664个类。 测试数据集必须具有与训练数据完全相同的类。 由于我们的测试数据已被标记,因此我们仅将那些在预处理集中存在的类保留在测试集中,并丢弃其余的类。
df_test = df_test[df_test["condition"].isin(df_train["condition"])]
number_of_classes(df_test)
The testing data now also consist of 210 classes, exactly the same as the training set.
现在,测试数据还包括210个类,与训练集完全相同。
预处理评论 (Preprocessing Reviews)
So far, we have worked on the labels only by balancing the dataset and removing low-frequency classes. In order to make the reviews ready to be fed into any Machine Learning Model, we have to preprocess them so that the unnecessary information is removed. We will remove stopwords and then perform the stemming of the words in the corpus.
到目前为止,我们仅通过平衡数据集并删除低频类来处理标签。 为了使评论准备好进入任何机器学习模型,我们必须对其进行预处理,以消除不必要的信息。 我们将删除停用词 ,然后对语料库中的单词进行词干处理。
删除停用词并阻止 (Removing Stopwords and Stemming)
import string
def filter_data(reviews):
"""
Filter the corpus of training and testing df.
This function removes stop and stem words from the corpus
:param reviews:
:return:
"""
stop = stopwords.words('english')
stemmer = SnowballStemmer("english")
# remove punctuations
series = reviews.str.replace('[{}]'.format(string.punctuation), '')
# remove stop words
series = series.apply(
lambda x: ' '.join([word for word in x.split() if word not in stop]))
# remove stem words
series = series.apply(lambda x: ' '.join([stemmer.stem(word) for word in x.split()]))
return series
df_train["review"] = filter_data(df_train["review"]).str.lower()
df_test["review"] = filter_data(df_test["review"]).str.lower()We define a function name filter_data which takes in lowercased reviews, iterates over each word in the sentence and then first, removes the punctuations and stopwords and then performs stemming of the words.
我们定义一个函数名称filter_data ,该函数接受小写评论,迭代句子中的每个单词,然后首先删除标点符号和停用词,然后对单词进行词干处理。
降低目标类别 (Lowercasing target classes)
We lower case the target classes labels so that they can directly be used to train our machine learning classifier.
我们小写目标类别标签,以便它们可以直接用于训练我们的机器学习分类器。
df_train["Label"] = df_train["condition"].str.lower()
df_test["Label"] = df_test["condition"].str.lower()创建机器学习模型 (Creating Machine Learning Model)
In order to get the best Machine Learning model, we will perform 4-Fold Cross Validation on the training dataset and then use the best performing model to make predictions on the test dataset. We will use the following Machine Learning Classifiers and then select the best model based on its performance:
为了获得最佳的机器学习模型,我们将对训练数据集执行四重交叉验证,然后使用性能最佳的模型对测试数据集进行预测。 我们将使用以下机器学习分类器,然后根据其性能选择最佳模型:
- Multinomial Naive Bayes 多项式朴素贝叶斯
- Stochastic Gradient Descent Classifier 随机梯度下降分类器
- Random Forest Classifier 随机森林分类器
- K-Nearest Neighbours Classifier 最近邻分类器
We shuffle the training dataset and save relevant columns of the dataset in variable X and Y.
我们将训练数据集改组,并将数据集的相关列保存在变量X和Y中 。
# shuffle the training dataframe and saving the columns in X and Y
df_train = df_train.sample(frac=1)
X = df_train['review']
Y = df_train['Label']Before the text data is fed into any machine learning classifier, it requires special preparation. The text must be parsed to remove words, called tokenization. Then the words need to be encoded as integers or floating-point values for use as input to a machine learning algorithm, called feature extraction (or vectorization).
在将文本数据输入任何机器学习分类器之前,需要进行特殊准备。 必须解析文本以删除单词,称为标记化。 然后,需要将单词编码为整数或浮点值,以用作机器学习算法(称为特征提取(或矢量化))的输入。
We will use sklearn’s CountVectorizer package to transform our reviews into vectors. The CountVectorizer provides a simple way to both tokenize a collection of text documents and build a vocabulary of known words, but also to encode new documents using that vocabulary.
我们将使用sklearn的CountVectorizer包将评论转换为向量。 CountVectorizer提供了一种简单的方法,既可以标记文本文档的集合并建立已知单词的词汇表,又可以使用该词汇表对新文档进行编码。
count_vectorizer = CountVectorizer(ngram_range=(1,2))
X_count_vec = count_vectorizer.fit_transform(X)Next, we define a method cross_val_multiple_classifiers which takes in the data and labels, performs a 4 fold cross-validation with all the classifiers mentioned above, and displays the mean of accuracy and standard deviation of all the folds for each classifier and call this method on the vectorized training data.
接下来,我们定义一个方法cross_val_multiple_classifiers ,该方法cross_val_multiple_classifiers数据和标签,对上述所有分类器执行4折交叉验证,并显示每个分类器的所有折痕的准确性和标准差的平均值,并在此方法上调用向量化的训练数据。
def cross_val_multiple_classifiers(X, Y):
classifiers = [MultinomialNB(), SGDClassifier(loss="modified_huber"),
RandomForestClassifier(n_estimators=100),
KNeighborsClassifier(n_neighbors=5)]
labels = ['Multinomial Naive Bayes', 'SGD Classifier', 'Random Forest', 'KNN']
clf_cv_mean = []
clf_cv_std = []
for clf, label in zip(classifiers, labels):
scores = cross_val_score(clf, X, Y, cv=4, scoring='accuracy')
print ("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))
# calling multiple classifiers on the vectorized features
cross_val_multiple_classifiers(X_count_vec, Y)
We see that the Random Forest Classifier works best with a mean accuracy score of around 54%. Let’s use this model to train it on the complete training dataset and get the predictions on the test set.
我们发现, 随机森林分类器的最佳平均评分约为54% 。 让我们使用此模型在完整的训练数据集上进行训练,并在测试集上获得预测。
# training the Random Forest Classifier on complete training data
fin_clf = RandomForestClassifier(n_estimators=100)
fin_clf.fit(X_count_vec, Y)
# transforming test_data with count vectorizer
X_test_vec = count_vectorizer.transform(df_test['review'])
# getting preds on the test data
preds = fin_clf.predict(X_test_vec)
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
print("Accuracy on test data: ", accuracy_score(df_test["Label"].str.lower(),
preds))
print("Macro F-1 Score on test data: ", f1_score(df_test["Label"].str.lower(),
preds, average="macro"))
print("Micro F-1 Score on test data: ", f1_score(df_test["Label"].str.lower(),
preds, average="micro"))
Even though the cross-validated score for the classifier was only 54%, the overall accuracy of the classifier on the test dataset is 70% with good F1-Scores. This might be because of a bias in the test set. However, since the cross-validated accuracy score was low, we still need to find a better strategy to train the classifier, in order to improve the overall performance.
即使分类器的交叉验证得分仅为54%,但具有良好的F1分数,测试数据集上分类器的总体准确性为70%。 这可能是由于测试集中存在偏差。 然而,由于交叉验证的准确性得分较低,我们仍然需要找到更好的策略来训练分类器,以提高整体性能。
结论 (Conclusion)
In this part of the series, we tried to solve a challenging problem of predicting medical condition using reviews on the drugs made by the consumers using Statistical Machine Learning Classifiers and using Count Vectorizer to convert text to input features. Even though we resolved the high-class imbalance in our dataset, the results were still not impressive enough with the best performing classifier only providing 54% cross-validated accuracy score.
在本系列的这一部分中,我们试图通过使用统计机器学习分类器对消费者生产的药品进行评论,并使用Count Vectorizer将文本转换为输入特征来解决预测医疗状况的难题。 即使我们解决了数据集中的高级不平衡问题,结果仍然不够令人印象深刻,而性能最好的分类器仅提供了54%的交叉验证准确性得分。
In the next part, we will try to improve the performance of our model by adopting a different approach to solve the problem.
在下一部分中,我们将尝试通过采用另一种方法来解决问题来提高模型的性能。
The complete code of the notebook can be obtained from here — https://github.com/hamiz-ahmed/Machine-Learning-Notebooks/blob/master/Classifying_Medical_Condition_using_Statistical_Models_Part_1.ipynb
可以从此处获取笔记本的完整代码-https: //github.com/hamiz-ahmed/Machine-Learning-Notebooks/blob/master/Classifying_Medical_Condition_using_Statistical_Models_Part_1.ipynb
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









