





 本文深入探讨了Bagging方法,一种机器学习集成技术,用于提高回归和分类算法的准确性和稳定性。Bagging通过自举和聚合过程减少模型方差,防止过拟合,尤其适用于高自由度模型。本文还对比了Bagging与Boosting的区别,以及各自的适用场景。
本文深入探讨了Bagging方法,一种机器学习集成技术,用于提高回归和分类算法的准确性和稳定性。Bagging通过自举和聚合过程减少模型方差,防止过拟合,尤其适用于高自由度模型。本文还对比了Bagging与Boosting的区别,以及各自的适用场景。
bagging方法 套袋
A machine learning ensemble used to improve the accuracy and stability of algorithms in regression and statistical classification.
一种机器学习集合,用于提高回归和统计分类中算法的准确性和稳定性。
Ensemble machine learning can be mainly categorized into bagging and boosting. The bagging technique is useful for both regression and statistical classification. Bagging is used with decision trees, where it significantly raises the stability of models in the reduction of variance and improving accuracy, which eliminates the challenge of overfitting.
集成机器学习主要可以分为装袋和提升。 套袋技术可用于回归和统计分类。 套袋与决策树一起使用,可以显着提高模型在减少方差和提高准确性方面的稳定性,从而消除了过拟合的挑战。
介绍 (Introduction)
As mentioned before , two possibilities for making majority votes were bagging and boosting.The principle of bagging is rather simple and does not present any major difficulty for the implementation.The challenge lies in selecting the optimal parameters to build the voters, because we have a wide range of possibilities.
如前所述,袋装和提高票数是获得多数选票的两种可能性。袋装的原理很简单,在实施过程中不会遇到任何主要困难。挑战在于选择最佳参数来构建选民,因为我们有一个广泛的可能性。
The term introduced, bagging, is shorthand for the combination of bootstrapping and aggregating. It aims at producing an ensemble model that is more robust than the individual models composing it.
引入的术语“装袋”是自举和聚集的组合的简写。 它旨在产生一个整体模型,该模型比构成它的单个模型更健壮 。
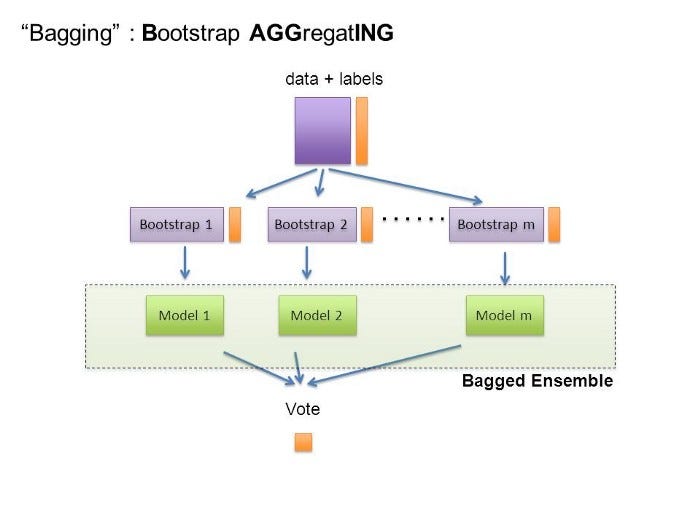
1.自举 (1. Bootstrapping)
Bootstrapping is a method to help decrease the variance of the classifier and reduce overfitting, because even if more training data is provided, the model may still perform poorly. And, may not even reduce the variance of our model. And,that’s why we use Bootstrapping.
自举是一种有助于减少分类器差异并减少过度拟合的方法,因为即使提供了更多的训练数据,该模型的性能仍然可能很差。 并且,甚至可能无法减少我们模型的方差。 并且,这就是为什么我们使用Bootstrapping。
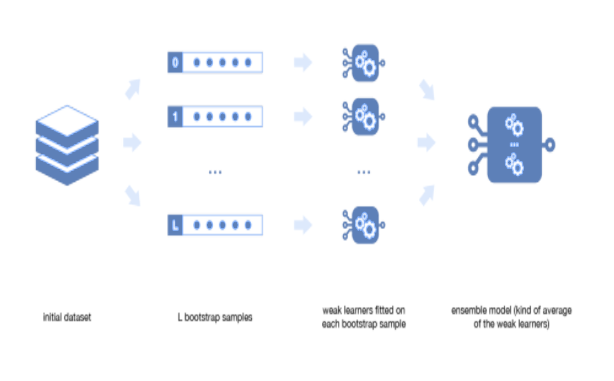
This statistical technique consists in sampling (generating samples) of size B called bootstrap samples from an initial dataset D of size n by randomly drawing with replacement B observations.By sampling with replacement, some observations may be repeated in each Di. If n′=n, then for large n the set Di is expected to have the fraction (1–1/e) (≈63.2%) of the unique examples of D, the rest being duplicates.
这种统计技术包括通过随机绘制替换B的观测值从大小为n的初始数据集D采样(生成样本)(称为自举样本),通过替换B观察随机抽样。在每个D i中可以重复一些观测。 如果n'= n,则对于较大的n,集合D i期望具有D的唯一示例的分数(1-1 / e)(≈63.2%),其余部分重复。
2.培训 (2. Training)
Say we generate L samples each of size n′, with replacement, from the original data set of size N. Then we train L homogeneous base models on each of these L samples that are generated by bootstrapping.
假设我们从大小为N的原始数据集中生成了大小为n'的L个样本,并进行了替换。然后,我们在通过自举生成的这L个样本中的每个样本上训练了L个同质基础模型。

3.汇总 (3. Aggregating)
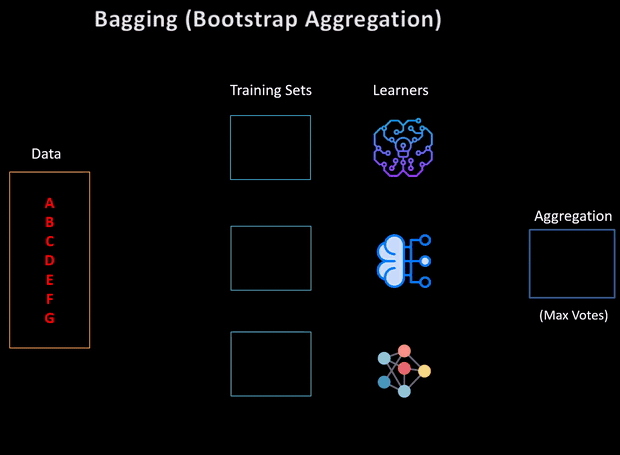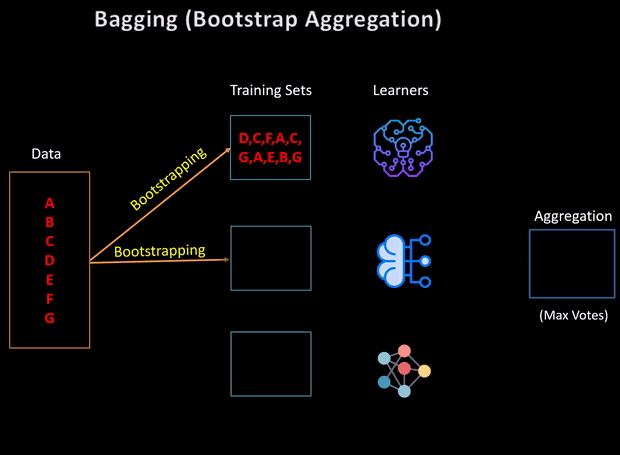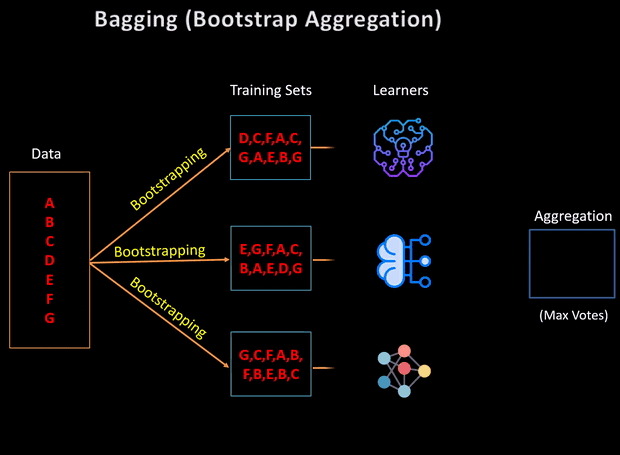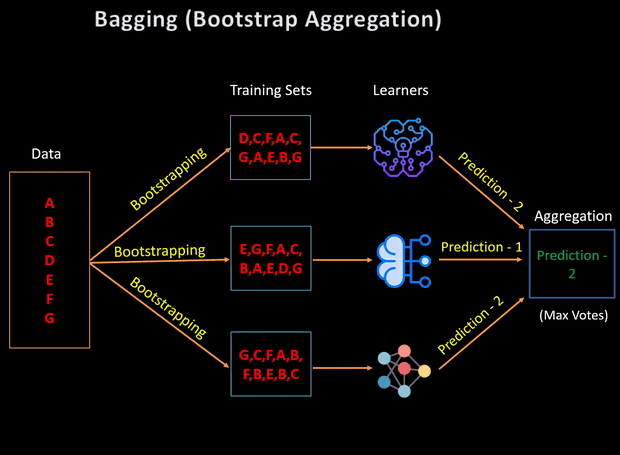
We have Model predictions from L base models that we need to aggregate using some averaging methods to combine them for the final prediction to consider all the outcomes possible. The aggregation can be done based on the total number of outcomes or on the probability of predictions derived from the bootstrapping of every model in the procedure.
我们有来自L个基础模型的模型预测,我们需要使用一些平均方法进行汇总以将其组合起来以进行最终预测,以考虑所有可能的结果。 可以根据结果总数或过程中每个模型的自举得出的预测概率来进行汇总。
- In the case of a regression problem, we could find the literal average (averaging) of the predictions from base models to make for the prediction from the ensemble model. 在回归问题的情况下,我们可以从基本模型中找到预测的字面平均值(取平均值),从而从整体模型中获得预测值。
Y =(y1 + y2 + y3 +…+ yL)/ L (Y = ( y1+y2+y3+…+yL ) / L)
For a classification problem, if we have the base models return the class labels, then one way of aggregating is by considering the class returned by each weak classifier as a vote and the class with the highest number of votes is returned by the ensemble model — Hard Voting.
对于分类问题,如果我们有基本模型返回类标签,则一种汇总方法是将每个弱分类器返回的类视为一票,而集成模型返回具有最高票数的类— 硬投票 。
Y =最大值(y1,y2,y3,…,yL) (Y = max ( y1, y2, y3,…, yL ))
On the other hand, if we have base models returning the probabilities of each class, then one way is to find the average of each of the class predictions from all the base models and the class with the highest mean probability is returned by the ensemble model — Soft Voting.
另一方面,如果我们有基础模型返回每个类别的概率,那么一种方法是从所有基础模型中找到每个类别预测的平均值,并且集成模型返回具有最高平均概率的类别— 软投票 。
Y = max [P(y1),P(y2),P(y3),…,P(yL)] (Y = max [ P(y1), P(y2), P(y3),…, P(yL) ])
4.套袋的优势 (4. Advantage of Bagging)
Random forest is one of the most popular bagging algorithms. Bagging offers the advantage of allowing many weak learners to combine efforts to outdo a single strong learner.
随机森林是最流行的套袋算法之一。 套袋提供的优势是允许许多弱学习者共同努力,胜过单个强学习者。
Bagging methods mainly focus on reducing the variance. If the base models trained on different samples have high variance (overfitting), then the aggregated result would even it out thereby reducing the variance. Therefore, this technique is chosen when the base models have high variance and low bias which is generally the case with models having high degrees of freedom for complex data (Ex: Deep Decision Trees).
套袋方法主要集中在减少方差上 。 如果在不同样本上训练的基本模型具有较高的方差(过度拟合),则合计结果将使结果均匀,从而减小方差。 因此,在基本模型具有高方差和低偏差的情况下选择此技术,通常对于复杂数据具有高自由度的模型(例如:深度决策树)就是这种情况。
The big advantage of bagging is that it can be parallelised (trained in parallel). As the different models are fitted independently from each other, intensive parallelisation techniques can be used if required.
套袋的最大优点是可以并行化 ( 并行训练)。 由于不同的模型彼此独立安装,因此如果需要,可以使用密集的并行化技术。
Models with complex architecture or large data require more training time. bagging is parallelised , the time taken to train each of the base models is equivalent to training any one of them, making bagging a good choice of ensemble method.
具有复杂架构或大数据的模型需要更多的训练时间。 套袋是并行的 ,训练每个基本模型所需的时间等于训练它们中的任何一个,因此使套袋成为集成方法的不错选择。
5.套袋与助推 (5. Bagging vs. Boosting)
The best technique to use between bagging and boosting depends on the data available, simulation, and any existing circumstances at the time. An estimate’s variance is significantly reduced by bagging and boosting techniques during the combination procedure, thereby increasing the accuracy. Therefore, the results obtained demonstrate higher stability than the individual results.
在装袋和增强之间使用的最佳技术取决于可用的数据, 模拟以及当时的任何现有情况。 在组合过程中,通过套袋和增强技术可以大大减少估计的方差,从而提高准确性。 因此,获得的结果显示出比单个结果更高的稳定性。
When an event presents the challenge of low performance, the bagging technique will not result in a better bias. However, the boosting technique generates a unified model with lower errors since it concentrates on the optimization of the advantages and reduction of shortcomings in a single model.
当事件带来性能低下的挑战时,套袋技术将不会导致更好的偏差。 然而,由于增压技术集中于单个模型的优点的优化和缺点的减少,因此产生了具有较低误差的统一模型。
When the challenge in a single model is overfitting, the bagging method performs better than the boosting technique. Boosting faces the challenge of handling over-fitting since it comes with over-fitting in itself.
当单个模型中的挑战过拟合时,装袋方法的性能优于增强方法。 Boosting自身面临过度拟合,因此面临处理过度拟合的挑战。
翻译自: https://medium.com/@raaaaouf/bagging-bootstrap-aggregating-overview-b73ca019e0e9
bagging方法 套袋

















 305
305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









