





深度学习 , 计算机视觉 , 编程 (Deep Learning, Computer Vision, Programming)
With the training of deep learning models, how can we deploy the trained model as a web application? Enters Flask — the most popular web application framework for Python. By leveraging on the functionality of Flask, we can establish a strong foundation for a full-stack application, explore new frontiers for a more extensive and feature-rich website. It enables the user to exercise full control over serving the web pages and internal data flow.
瓦特 i个深度学习模型的训练,我们如何可以部署训练的模型为Web应用程序? 进入Flask -Python最流行的Web应用程序框架。 通过利用Flask的功能,我们可以为全栈应用程序奠定坚实的基础,为更广泛和功能更丰富的网站探索新领域。 它使用户可以完全控制服务网页和内部数据流。
We shall approach the following problem statements and explore the use of transfer learning and flask web application for deep learning projects.
我们将处理以下问题陈述,并探讨将转移学习和flask Web应用程序用于深度学习项目。
问题陈述: (Problem Statements:)
(i)使用转移学习为鸟类分类建立卷积神经网络(“ CNN”)模型。 ((i) Develop a Convolutional Neural Network (“CNN”) model for birds classification using transfer learning.)
(ii)部署经过训练的模型以使用用户界面获取图像进行分类。 ((ii) Deploy the trained model to take in an image for classification using a user interface.)
Instead of building a CNN model from scratch, let’s address the problem statements by building upon the transfer learning idea as discussed in my earlier post:
与其从头开始构建CNN模型,不如通过我之前的文章中讨论的转移学习思想来解决问题陈述:
Computer vision tasks are computationally intensive and repetitive, and they often exceed the real-time capabilities of the CPU, leaving little time for higher-level tasks. Compared to the CPU, a GPU is designed to quickly render high-resolution images and video concurrently.
计算机视觉任务是计算密集型和重复性的,并且它们通常超过CPU的实时功能,从而几乎没有时间执行更高级别的任务。 与CPU相比,GPU旨在快速并发渲染高分辨率的图像和视频。
The biggest advantage of GPUs would be the ability to perform parallel operations on multiple sets of data. Designed with thousands of processor cores running simultaneously, GPUs enable massive parallelism where each core is focused on making efficient calculations.
GPU的最大优势是能够对多组数据执行并行操作。 GPU设计有数千个同时运行的处理器内核,因此可实现大规模并行处理,其中每个内核都专注于进行高效的计算。
For free access to a ready-to-use GPU, you can utilize Colab, a Python development environment that runs in the browser using Google Cloud. However, do bear in mind its resource limits. An alternative option would be to install the CUDA Toolkit on your laptop. Do check the compute capability for your NVIDIA GPU before proceeding further.
要免费访问即用型GPU,您可以利用Colab (一种Python开发环境),该环境可以在使用Google Cloud的浏览器中运行。 但是,请记住它的资源限制 。 另一种选择是在笔记本电脑上安装CUDA Toolkit。 在继续之前,请检查NVIDIA GPU的计算能力。
Here are some resources to help you get started:
以下是一些可帮助您入门的资源:
Installing Tensorflow with CUDA, cuDNN and GPU support on Windows 10
Once you have installed the CUDA Toolkit, input nvidia-smi at the command line to report the installed GPU statistics. If the installation is successful, you should be able to see a similar output with the GPU statistics as follows.
安装CUDA工具包后,在命令行中输入nvidia-smi以报告已安装的GPU统计信息。 如果安装成功,您应该能够看到类似的带有GPU统计信息的输出,如下所示。

现在可以使用GPU了,让我们编写代码! (Now that the GPU is good to go, let’s code!)
资料准备 (Data Preparation)
Read the CSV file containing the labels for the dataset and display the first 5 rows.
读取包含数据集标签的CSV文件,并显示前5行。

Plot a bar chart to have a feel of the distribution of images within the dataset.
绘制条形图,以感觉图像在数据集中的分布。

An imbalanced dataset was observed where there was insufficient data to train the network. Some classes had even less than 10 images, to begin with.
观察到不平衡的数据集,其中没有足够的数据来训练网络。 首先,有些课程的图像甚至少于10张。
数据扩充 (Data Augmentation)
Data Augmentation can address the issue of an imbalanced dataset by artificially creating more images from the existing images by changing the size, orientation, etc of the image. This can be done in Keras by using the ImageDataGenerator instance. It includes rotation of the image, shifting the image left/ right/ top/ bottom by some amount, flip the image horizontally or vertically, shear or zoom the image, etc.
数据增强可以通过更改图像的大小,方向等,从现有图像中人为地创建更多图像,从而解决数据集不平衡的问题。 这可以通过使用ImageDataGenerator实例在Keras中完成。 它包括旋转图像,向左/右/上/下移动图像一定量,水平或垂直翻转图像,剪切或缩放图像等。
Load images into the respective folders for each bird classification in accordance with labels as per the CSV file.
根据CSV文件的标签,将图像加载到每个鸟类分类的相应文件夹中。
Using the console terminal, run generate_images.py at the command line to perform data augmentation for each bird classification.
使用控制台终端,在命令行上运行generate_images.py ,以对每种鸟类分类执行数据扩充。
The objective is to ensure that each class contains a total of 100 images each. Hence, the number of images selected to perform data augmentation is dependent on the requirement of each class.
目的是确保每个类别总共包含100张图像。 因此,选择用于执行数据增强的图像数量取决于每个类别的要求。
使用增强加载数据集 (Load Dataset with Augmentation)

I’m clearly feeling fancy with the graph plotting, but who said graph plots have to be boring when Seaborn is in the picture? We have now achieved an equal number of 100 images per class to kick start the model training.
我显然对图形绘制感到很花哨,但是当Seaborn在照片中时,谁说图形绘制一定很无聊? 现在,我们已经获得了每个班级100张图像的相等数量,以开始进行模型训练。

Due to hardware constraints, we would work with an input image dimension of 128 X 128 instead of the original 224 X 224 used in the VGG16 model. We shall proceed to read, resize, and scale these images for training.
由于硬件限制,我们将使用128 X 128的输入图像尺寸,而不是VGG16模型中使用的原始224 X 224。 我们将继续阅读,调整大小和缩放这些图像以进行培训。

Load and split the dataset for training and testing of the CNN model. A test size of 0.2 was used, meaning 80% of the dataset would be used for training purposes while the remaining 20% serves as the testing component. We then split the dataset in a stratified fashion, using the labels, y, as the class labels. The dataset is also shuffled before splitting, to enhance the randomness of probability sampling. The random state controls the shuffling applied to the data before applying the split. An integer is passed in this parameter for reproducible output across multiple function calls.
加载和拆分数据集以进行CNN模型的训练和测试。 使用的测试大小为0.2 ,这意味着数据集的80%将用于训练目的,而其余的20%将用作测试组件。 然后,我们在一个分层的方式分割数据集,使用标签,Y,作为类的标签。 数据集在拆分之前也要进行混洗 ,以增强概率采样的随机性。 随机状态控制在应用拆分之前应用于数据的改组。 在此参数中传递整数,以便在多个函数调用之间可重现输出。
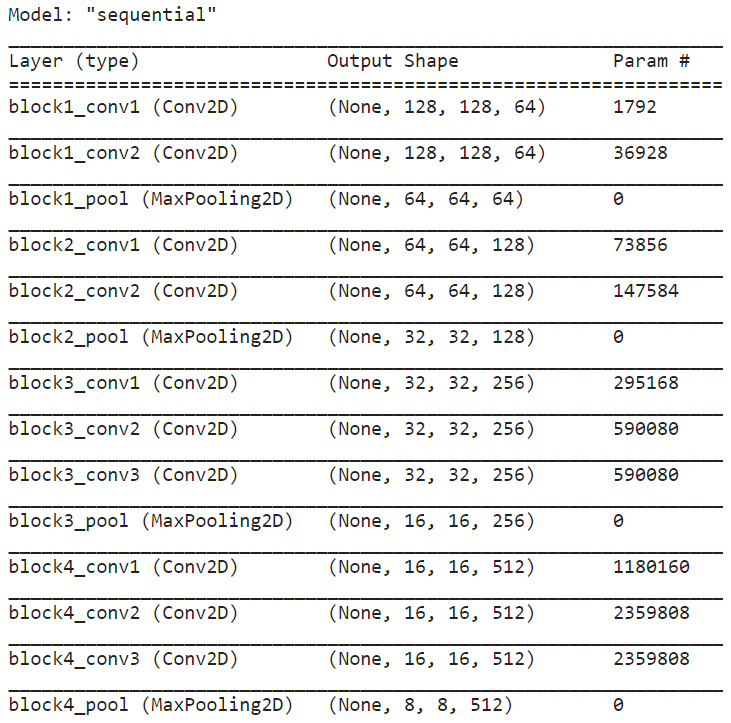
使用转移学习创建CNN模型 (Creation of CNN Model using Transfer Learning)
Transfer learning is applied by freezing the “deep layers” of the model and only re-training the classification layers.
通过冻结模型的“深层”并仅重新训练分类层来应用转移学习。
We have selected to use the Adam optimization, which is a stochastic gradient descent method that is based on an adaptive estimation of first-order and second-order moments.
我们选择使用Adam优化 ,它是一种基于一阶和二阶矩的自适应估计的随机梯度下降方法。
According to Kingma et al., 2014, this method is
根据Kingma等人(2014年) ,此方法是
“computationally efficient, has little memory requirement, invariant to diagonal re-scaling of gradients, and is well suited for problems that are large in terms of data/ parameters.”
“计算效率高,几乎没有存储需求,不影响梯度的对角线重新缩放,并且非常适合处理数据/参数较大的问题。”

模型训练 (Model Training)

学习曲线 (Learning Curves)
A learning curve is a plot of model learning performance over experience or time. Learning curves are a widely used diagnostic tool in machine learning for algorithms that learn from a training dataset incrementally. The model can be evaluated on the training dataset and validation dataset after each update during training, and plots of the measured performance are created to reflect the learning curves.
学习曲线是模型学习绩效随经验或时间变化的图 。 学习曲线是机器学习中广泛使用的诊断工具,用于从训练数据集中逐步学习的算法。 在训练期间的每次更新之后,可以在训练数据集和验证数据集上评估模型,并创建测量的性能图以反映学习曲线。
Reviewing learning curves of models during training can be used to diagnose problems with learning, such as an underfit or overfit model, as well as whether the training and validation datasets are suitably representative.
在训练期间查看模型的学习曲线可用于诊断学习问题,例如欠拟合或过拟合模型,以及训练和验证数据集是否具有代表性。
Train Learning Curve: Learning curve calculated from the training dataset that gives an idea of how well the model is learning.
训练学习曲线 :根据训练数据集计算出的学习曲线,可以了解模型的学习程度。
Validation Learning Curve: Learning curve calculated from a validation dataset that gives an idea of how well the model is generalizing.
验证学习曲线 :从验证数据集计算得出的学习曲线,可以了解模型的概括程度。
Let’s plot the learning curves for the training and validation accuracy/ loss.
让我们绘制学习曲线,以训练和验证准确性/损失。

From the above learning curves, a good fit for the learning algorithm was observed. A good fit is identified by a training and validation accuracy/loss that decreases to a point of stability with a minimal generalization gap between the two final accuracy/loss values. However, any continued training of a good fit will likely lead to an overfit.
从以上学习曲线可以看出,该学习算法非常适合。 训练和验证的准确性/损失降低到稳定点, 并且两个最终准确性/损失值之间的 泛化差距 最小,从而确定了良好的拟合 度。 但是,任何持续的良好健身训练都可能导致过度健身。
使用Flask进行模型部署 (Model Deployment using Flask)
Define a function to predict the image using the trained model, with a list of class names to be predicted by the model.
定义一个功能来使用训练后的模型预测图像,并列出要由模型预测的类名称。
定义烧瓶应用 (Define the Flask Application)
For ideas on the HTML template, do check out HTML5 UP for some beautifully curated user interface templates for your project.
有关HTML模板的想法,请查看HTML5 UP,获取用于您项目的精选精美的用户界面模板。
运行Flask应用程序 (Run the Flask Application)
We shall run the flask application on localhost and input the URL of a random bird image from the internet. For demonstration purpose, we have selected the following bird image:
我们将在本地主机上运行flask应用程序,并从互联网输入随机鸟图像的URL。 为了演示,我们选择了以下鸟类图像:

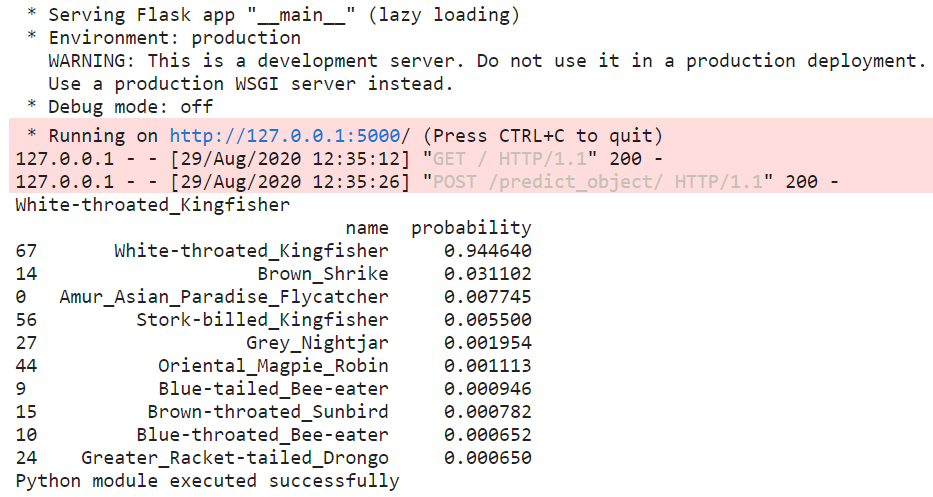
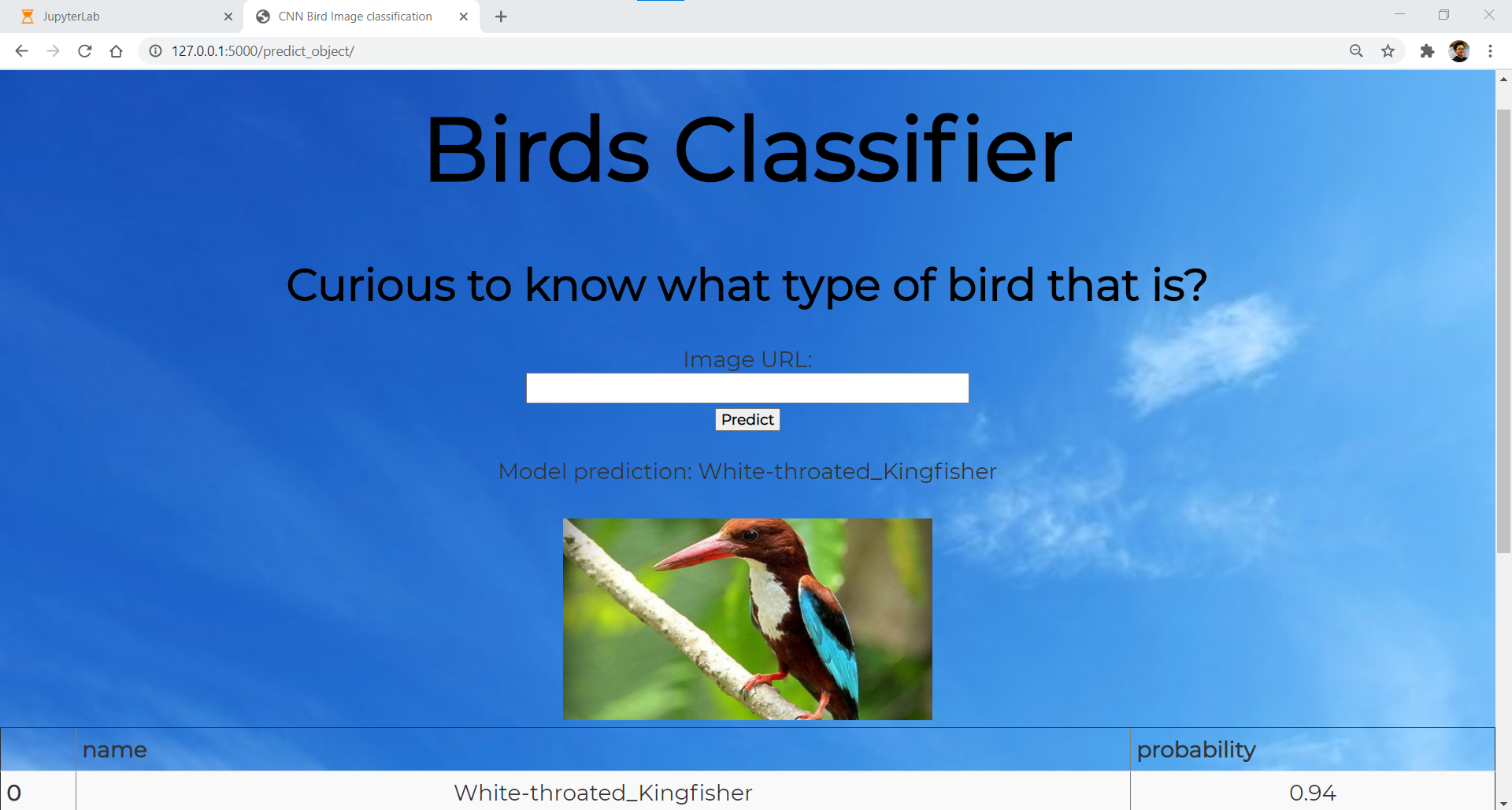
The above results were obtained with a high probability of 0.94 for the White-throated Kingfisher. This indicated a good performance of the trained model in terms of correctly identifying the bird in question to its respective class.
对于白喉翠鸟,获得上述结果的可能性很高,为0.94。 这表明训练过的模型在正确识别相关鸟类方面表现出良好的性能。
结论 (Conclusion)
Overall, a CNN model has been successfully built using transfer learning for birds classification. The flask application is a very useful tool to deploy the trained model to take in an image of a bird for classification.
总体而言,已经使用转移学习成功建立了CNN模型,以进行鸟类分类。 烧瓶应用程序是一个非常有用的工具,用于部署训练有素的模型以拍摄鸟类图像进行分类。
To further enhance the accuracy level of a diversity of bird breeds other than the 77 categories, improvements can be made where the CNN model is trained with a large and general enough dataset. The use of transfer learning enables one to take advantage of the previously learned feature maps without having to start from scratch by training a large model on a large dataset.
为了进一步提高除77个类别以外的其他鸟类品种的准确性水平,可以在使用足够大和足够通用的数据集训练CNN模型的情况下进行改进。 转移学习的使用使人们可以利用先前学习的特征图,而不必通过在大型数据集上训练大型模型而从头开始。
翻译自: https://medium.com/towards-artificial-intelligence/flask-web-application-with-python-4a290c952ba2















 2112
2112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









