





零信任模型
In the world of deep learning, there are certain safety-critical applications where a cold prediction is just not very helpful. If a patient without symptoms is diagnosed with a serious and time-sensitive illness, can the doctor trust the model to administer immediate treatment? We are currently in a phase between solely human doctors being useful and complete AI hegemony in terms of diagnosing illness: deep learning models perform better than human experts independently, but a cooperation between human experts and AI is the optimal strategy.
在深度学习的世界中,在某些对安全性要求很高的应用中,冷预测并不是很有用。 如果没有症状的患者被诊断出患有严重且对时间敏感的疾病,医生可以信任该模型来立即进行治疗吗? 当前,在诊断方面,人类医生正处于有用和完全AI霸权之间的阶段:深度学习模型的性能要比人类专家独立更好,但是人类专家和AI之间的合作是最佳策略。
Human experts must gauge the certainty behind the deep learning model’s predictions if they are to provide an additional layer of judgement to the diagnosis. And to gauge the trust we can put into the model, we must be able to measure the types of uncertainty of the predictions.
人类专家必须为深度学习模型的预测提供依据,才能为诊断提供额外的判断层。 为了衡量我们对模型的信任程度,我们必须能够衡量预测不确定性的类型。
建模不确定性 (Modelling Uncertainty)
A deep learning model trained on an infinite amount of perfect data for an infinite amount of time necessarily reaches 100% certainty. In the real world, however, we don’t have perfect data or an infinite amount of it, and this is what causes the uncertainty of deep learning models.
在无限长的时间内对无限量的完美数据进行训练的深度学习模型必须达到100%的确定性。 但是,在现实世界中,我们没有完美的数据,也没有无限的数据,这就是造成深度学习模型不确定性的原因。
We call it aleatoric uncertainty when we have less-than-perfect data. If we had an infinite amount of it, the model will still not perform perfectly. It is the uncertainty stemming from noisy data.
当我们获得的数据不完美时,我们称其为不确定性 。 如果我们拥有无限量,则该模型仍将无法完美运行。 这是来自嘈杂数据的不确定性。
And when we have high quality data, but we still are not performing perfectly, we are dealing with epistemic uncertainty, the uncertainty due to imperfect parameter values.
而且,当我们拥有高质量的数据,但仍无法完美运行时,我们将处理认知不确定性(由于参数值不完善而导致的不确定性)。
A measure of aleatoric uncertainty becomes more important in large-data tasks, since more data explains away epistemic uncertainty. In small datasets, however, epistemic uncertainty proves to be a greater issue, especially in biomedical settings, where we work with a small amount of well-prepared and high-quality data.
在大数据任务中,测量不确定性变得更加重要,因为更多的数据可以解释认知不确定性。 然而,在小型数据集中,认知不确定性被证明是一个更大的问题,尤其是在生物医学环境中,在该环境中,我们将处理少量准备充分且高质量的数据。
Aleatoric uncertainty can be measured by directly adding a term to the loss function, such that the model predicts the input’s prediction and the prediction’s uncertainty. Epistemic uncertainty is slightly more tricky, since this uncertainty comes from the model itself. If we were to measure epistemic uncertainty as we would aleatoric, the model would have to do the impossible task of predicting the imperfection of its own parameters.
可以通过将一项直接添加到损失函数中来测量运动不确定性,以使模型预测输入的预测和预测的不确定性。 认知不确定性稍微复杂一些,因为这种不确定性来自模型本身。 如果我们要像测量性那样测量认知不确定性,则该模型将不得不完成预测其自身参数不完善的不可能的任务。
For the remainder of this article, I will focus more on epistemic uncertainty rather than aleatoric uncertainty. Both aleatoric and epistemic uncertainty can be measured in a single model, but I find epistemic uncertainty is far more significant in most biomedical and other safety-critical applications.
在本文的其余部分中,我将更多地关注认知不确定性而不是偶然不确定性。 可以在单个模型中测量无意识不确定性和认知不确定性,但是我发现认知不确定性在大多数生物医学和其他对安全至关重要的应用中更为重要。
测量认知不确定性 (Measuring Epistemic Uncertainty)
Let’s make a toy example and create some training data. Suppose we have 10 points of data. The x-value of each point is evenly spaced, and the y value is determined by adding some random noise to x.
让我们做一个玩具示例并创建一些训练数据。 假设我们有10点数据。 每个点的x值均匀分布,并且y值是通过向x添加一些随机噪声来确定的。
This is our training data; let’s fit three models (10-degree polynomials) to it:
这是我们的训练数据; 让我们拟合三个模型(10次多项式):
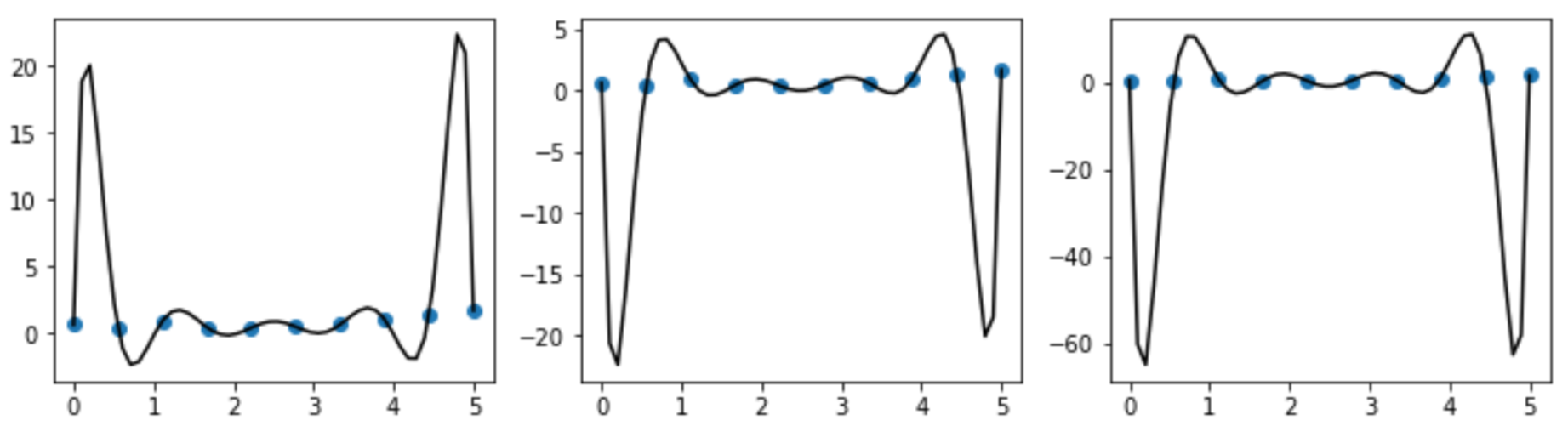
In this toy example, each model fits perfectly on the data. This means that for any input that is identical to one of the points of the training data, the model perfectly predicts its y-value. However, the if we take any x-value other than that of the training set, the predictions will be wildly off, depending on which model we use.
在这个玩具示例中,每个模型都完全适合数据。 这意味着对于任何与训练数据的一个点相同的输入,模型可以完美地预测其y值。 但是,如果我们采用除训练集以外的任何x值,则根据我们使用的模型,预测将大相径庭。
This is the intuition behind measuring epistemic uncertainty: we trained three different models on the training data, and we got three different models. If we give each model an input, .25 for example, then the first model will give us 20 for its prediction, about -20 for the second model, and around -60 for the third. There is a high standard deviation between these predictions, meaning each model does not accurately represent that data point.
这就是测量认知不确定性的直觉:我们在训练数据上训练了三种不同的模型,并且得到了三种不同的模型。 如果我们给每个模型一个输入,例如.25,那么第一个模型将为我们提供20的预测,第二个模型约-20,第三个模型约-60。 这些预测之间存在很高的标准偏差,这意味着每个模型都无法准确表示该数据点。
The epistemic uncertainty can thus be defined as the standard deviation of these three predictions, since wildly different predictions on otherwise similar models suggests that each model is guessing for that data point.
因此,可以将认知不确定性定义为这三个预测的标准偏差,因为在其他方面相似的模型上的预测差异很大,这表明每个模型都在猜测该数据点。
We can execute this procedure in practice by training several (usually 10) different models on the same training data, and during inference, take the standard deviation of each model’s prediction to estimate the epistemic uncertainty.
在实践中,我们可以通过在同一训练数据上训练几个(通常为10个)不同模型来执行此过程,并在推断过程中采用每个模型预测的标准差来估计认知不确定性。
However, training 10 different models is computationally expensive and sometimes infeasible for deep learning models training on giant datasets. Fortunately, there is a simple alternative that uses a single model to estimate epistemic uncertainty, that is, by using dropout on inference time.
但是,训练10个不同的模型在计算上很昂贵,有时对于在巨型数据集上进行深度学习模型训练有时是不可行的。 幸运的是,有一个简单的替代方法,即使用单个模型来估计认知不确定性,即通过使用推断时间的下降。
Dropout regularization, for those who are unfamiliar, is a technique that literally drops out random neurons of the network when training each batch during training. It is usually turned off at inference time, but, if we turn it on, and predict the test example 10 times, we can effectively simulate the approach of using 10 different models for epistemic uncertainty, since random dropout essentially results in a different model.
对于不熟悉的人,辍学正则化是一种在训练过程中训练每批时从字面上去除网络随机神经元的技术。 通常在推理时将其关闭,但是,如果我们将其打开并预测10次测试示例,则可以有效地模拟使用10个不同模型进行认知不确定性的方法,因为随机丢弃实际上会导致一个不同的模型。
This approach is called Monte Carlo dropout, and it is currently the standard in estimating epistemic uncertainty. There are some issues with the approach, namely that it requires nearly ten times more computation during inference time relative to a standard prediction without an uncertainty measurement. Monte Carlo dropout is therefore impractical for many real-time applications, leading to the alternative usage of often less effective but quicker methods to measure uncertainty.
这种方法称为“ 蒙特卡洛辍学” ,目前是估计认知不确定性的标准。 该方法存在一些问题,即与没有不确定性度量的标准预测相比,在推理时间内它需要的计算量增加了近十倍。 因此,对于许多实时应用而言,蒙特卡洛辍学是不切实际的,从而导致通常使用效率较低但较快的方法来测量不确定性的替代方法 。
警告 (Caveat)
We have measured the epistemic uncertainty, but in reality, we must remain uncertain about that very uncertainty measure. Indeed, we can measure the uncertainty of our measurement by graphing the standard deviation against absolute error. If the aleatoric uncertainty remains negligible, then there should be a linear relation between our epistemic uncertainty measurement and the absolute error between the predictions and the labels of a test set on a regression task.
我们已经测量了认知的不确定性,但是实际上,我们必须对该不确定性测量保持不确定性。 实际上,我们可以通过将标准偏差与绝对误差作图来测量测量的不确定性。 如果误差不确定性仍然可以忽略不计,那么我们的认知不确定性度量与预测和回归任务的测试集标签之间的绝对误差之间应该存在线性关系。
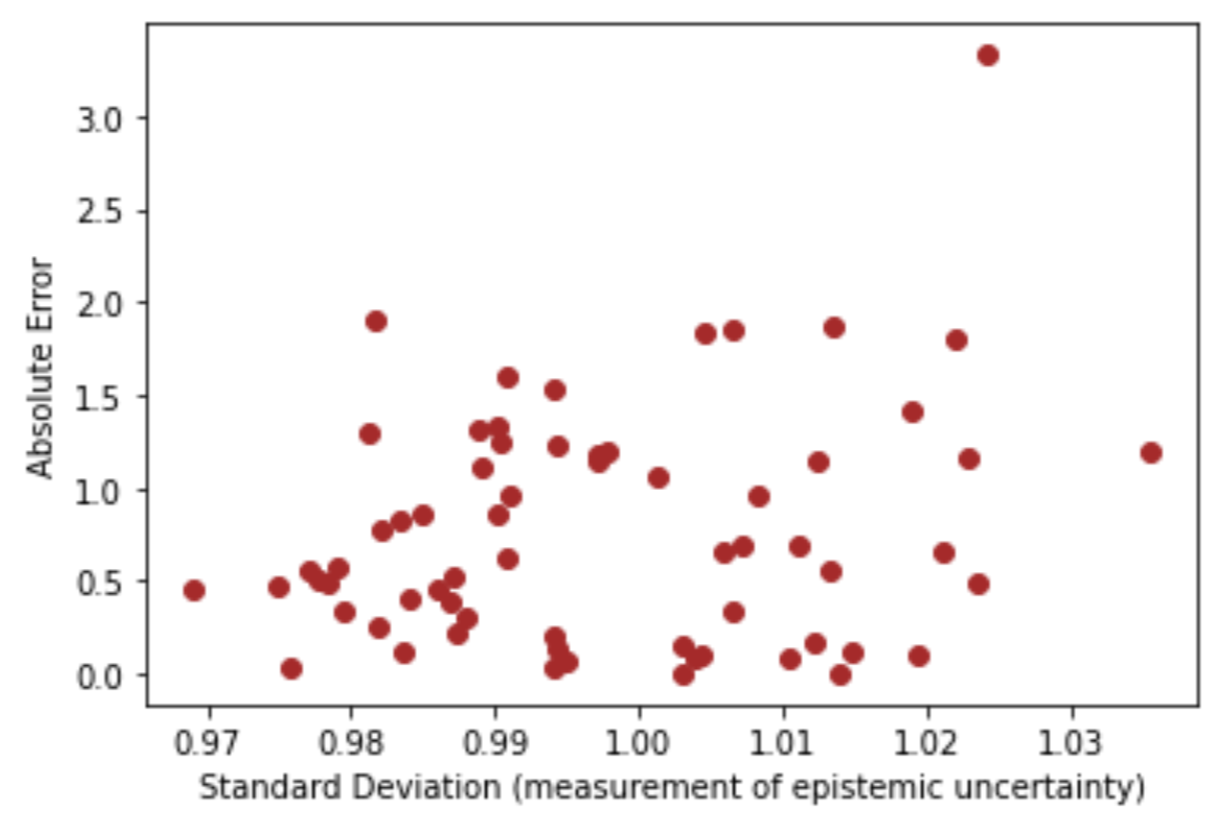
A perfect uncertainty measurement should be a straight, positive-sloping line, so although the uncertainty measurement evidently correlates with absolute error (which is what we want), the measurement is imperfect.
理想的不确定度测量应该是一条直线,正斜线,因此尽管不确定度测量显然与绝对误差(这是我们想要的)相关,但该测量并不完美。
This imperfect measurement is better than nothing, but what we really just did is add an uncertain proxy to represent uncertainty. Again, the proxy reduces uncertainty given the positive correlation, but the uncertainty remains.
这种不完美的测量总比没有好,但是我们真正所做的是添加一个不确定的代理来表示不确定性。 同样,在给定正相关的情况下,代理可以减少不确定性,但是不确定性仍然存在。
含义 (Implications)
What does this mean for doctors that might use uncertainty measurements? As of now, take the predictions of a deep learning model, whether it be the actual predictions of the label or its uncertainty measurements, with a grain of salt. The model cannot contextualize circumstances as a human expert might, so if a doctor finds that a model predicts a case which has evidently low aleatoric uncertainty (i.e. the data is high-quality and unequivocal) with high uncertainty, he or she is best to doubt the prediction on grounds of epistemic uncertainty. High epistemic uncertainty means the model was not trained optimally for the context of that particular case, and the model is just not generalizing well.
对于可能使用不确定性测量的医生意味着什么? 到目前为止,采用一粒盐来进行深度学习模型的预测,无论是标签的实际预测还是不确定性测量。 该模型无法像人类专家那样对环境进行上下文描述,因此,如果医生发现模型预测的案例具有明显的低不确定性(即,数据质量高且明确)且不确定性很高,那么最好怀疑他或她基于认知不确定性的预测。 较高的认知不确定性意味着该模型并未针对该特定案例进行最佳训练,并且该模型推广得还不够好。
Indeed, one study directly supports this logic by illustrating that human experts are worse than deep learning algorithms in cases where the algorithm predicts with low uncertainty, but human experts outperform the algorithm on high uncertainty cases.
实际上, 一项研究通过说明人类专家在算法具有较低不确定性的情况下比深度学习算法更糟糕,而人类专家在高不确定性情况下的性能优于该算法,从而直接支持了这种逻辑。
Uncertainty measurements are only metrics for the purpose of human understanding; they do not aid model performance at all. However, the performance of human-AI systems, on the other hand, directly benefit from uncertainty measurements.
不确定性度量只是出于人类理解目的的度量; 它们根本无法提高模型性能。 然而,另一方面,人类AI系统的性能直接受益于不确定性测量。
Thus, measuring model uncertainty is not just a case of keeping humans passively informed; for it directly improves the performance of the broader system.
因此,测量模型的不确定性不仅仅是让人们被动地了解情况的一种情况。 因为它直接改善了整个系统的性能。
引文 (Citations)
And a thank you to DeepChem tutorials for originally introducing many of these concepts.
非常感谢DeepChem教程最初介绍了其中许多概念。
翻译自: https://medium.com/swlh/on-trusting-the-model-e67c94b5d205
零信任模型















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









