









23年9月份来自博世AI中心(德国和以色列两地)和德国Tubingen大学的论文“Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving“。
在自动驾驶任务中,场景理解是预测周围交通参与者未来行为的第一步。然而,如何表示给定的场景并提取其特征仍然是悬而未决的研究问题。这项研究提出了一种基于文本的交通场景表示,并用预训练的语言编码器对其进行处理。首先,展示基于文本的表示与经典的光栅化图像表示相结合,得到描述性场景嵌入。其次,对 nuScenes 数据集的预测进行基准测试,并与基线相比显示出明显改进。第三,在一项消融研究中表明,文本和光栅化图像的联合编码器优于单个编码器,确认了两种表示具有互补的优势。
这里传统的轨迹预测模型采用CoverNet[19],其基于一个编码器-解码器架构,该架构提供场景的图像表示,用视觉编码器主干对其进行处理,最后从学习的表示中解码任务的目标(targets)。
与以前基于视觉的工作类似,例如[3],[4],CoverNet将场景编码为光栅化图像,随后将其输入ResNet-50 [12]架构,一个广泛使用的卷积神经网络(CNN)变型。提取中间层的特征图并全局池化后,生成的嵌入与智体状态向量连接并通过一系列致密层进行传播,生成最终的预测。
解码器将轨迹预测任务视为分类问题。定义一组轨迹候选 K,从中选取预测轨迹。这样的集合必须涵盖广泛的可能轨迹,以便包含接近基本事实的假设。同时,希望使集合尽可能小,以避免使分类问题变得不必要地困难。先定义公差参数 ε > 0,然后搜索涵盖预定义轨迹集 K′ 中的所有轨迹中最小轨迹集 K:∀k∈K, l∈K′ :δ(k,l)<ε,可以找到最佳覆盖集,其中δ是量化两个轨迹之间距离的测度。虽然这个问题通常是NP-hard,但简单、贪婪的解决方案在实践中效果很好[19]。
下面就是集成语言编码器之后的系统架构图:用每种模态特定的预训练模型对表征栅格化场景的图像和文本提示进行编码。如果同时使用两个输入源,随后会把两个嵌入合并。结果被馈送到解码器中,解码器的最后一层从预生成的轨迹集中选择目标轨迹。
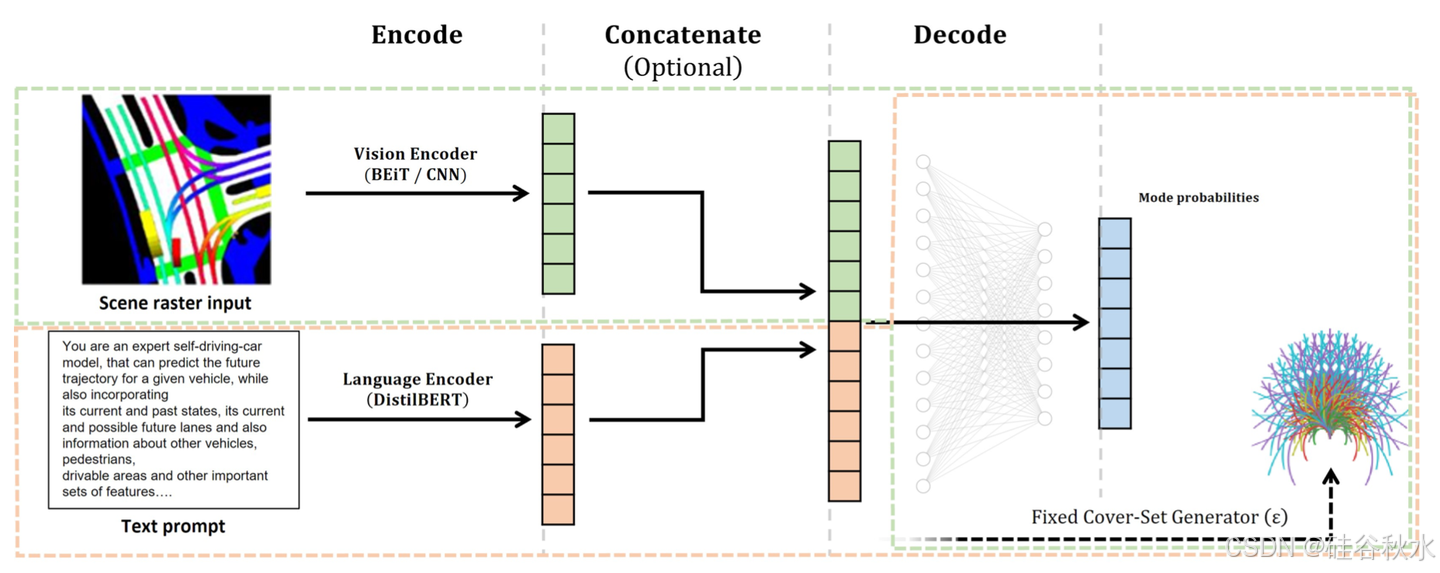
双向编码器图像Transformer (BEiT) [1] 是实验中选择的最先进 ViT。它是在 ImageNet [20] 上进行预训练的,其预训练目标涉及重建随机掩码的图像补丁。文本编码器摄取场景基于文本的表示形式,并输出场景嵌入,随后将其解码为轨迹预测。为了实现这一点,可以使用高性能大语言模型。然而,由于最先进的大语言模型不适合内存,因此需要微调。实验中选择DistilBERT [21]进行实验,这是BERT [7]的瘦身变型。
鉴于图像和文本编码器具有互补的优势,假设将两个编码器组合在一起的模型会产生更高的性能。这项工作中堆叠各个编码器的嵌入来构建一个联合编码器。今后更复杂的做法是,开放一个同时处理两个输入源的联合编码器。
特别强调一下,提示包含有关智体状态、其历史记录和车道等信息。在Bezier曲线的帮助下采用一个紧凑的车道编码方法,如图是一个提示例子。

车道用Bezier曲线编码,那么则依赖于一组离散控制点,生成平滑和连续曲线的参数表示[18]。在实验中,用cubic Bezier曲线,其由四个控制点定义,其中第一个和最后一个与车道的起点和终点重合。其余两个控制点确定曲率和方向,并以最小化Bezier曲线和离散化车道之间的均方误差进行拟合。虽然不像折线表示那样广泛使用,但这种表示允许明显更短的提示(平均长度:352),对于所有示例,这些提示都适合语言模型的上下文长度而不会造成被迫的截断。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









