





Introduction
介绍
Feature selection is the selection of reliable features from the bundle of large number of features. Having a good understanding of feature selection/ranking can be a great asset for a data scientist or machine learning user. It is an important process before model training as too many or redundant features negatively impacts the learning and accuracy of the model. In the collection of wanted/un-wanted features, it is important to select only those features which positively contributes towards prediction of target and remove the rest.
特征选择是从大量特征中选择可靠的特征。 对于数据科学家或机器学习用户而言,对特征选择/排序有很好的了解可能是一笔巨大的财富。 在模型训练之前,这是一个重要的过程,因为太多或多余的特征会对模型的学习和准确性产生负面影响。 在收集所需/不需要的特征时,重要的是仅选择那些对预测目标有积极贡献的特征,并删除其余特征。
Methods
方法
1. Filter Methods
1. 筛选方法
This feature selection method uses statistical approach which assigns a score to every feature. Further, Features are sorted according to their score and can be kept or removed from the data.
该特征选择方法使用统计方法,该统计方法为每个特征分配分数。 此外,要素会根据其得分进行排序,并且可以保留或从数据中删除。
Filter methods are very fast but might fall short in terms of accuracy when compared with the other methods.
过滤器方法非常快,但与其他方法相比,准确性可能不足。
Some examples of filter methods are as follows:
筛选方法的一些示例如下:
a. Information Gain
一个。 信息增益
Intuition: IG calculates the importance of each feature by measuring the increase in entropy when the feature is given vs. absent.
直觉:当给定特征与不存在特征时,IG通过测量熵的增加来计算每个特征的重要性。
Algorithm:
算法:
IG(S, a) = H(S) — H(S | a)
IG(S,a)= H(S)— H(S | a)
Where IG(S, a) is the information for the dataset S for the variable a for a random variable, H(S) is the entropy for the dataset before any change (described above) and H(S | a) is the conditional entropy for the dataset in the presence of variable a.
其中IG(S,a)是随机变量的变量a的数据集S的信息, H(S)是发生任何更改(如上所述)之前数据集的熵,而H(S | a)是有条件的存在变量a时数据集的熵。
Example code:
示例代码:
b. mRMR (Minimal Redundancy and Maximal Relevance)
b。 mRMR(最小冗余度和最大相关度)
Intuition: It selects the features, based on their relevancy with the target variable, as well as their redundancy with the other features.
直觉:它根据特征与目标变量的相关性以及与其他特征的冗余来选择特征。
Algorithm: It uses mutual information (MI) of two random variables.
算法:它使用两个随机变量的互信息(MI)。
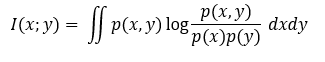
For discrete/categorical variables, the mutual information I of two variables x and y is defined based on their joint probabilistic distribution p(x, y) and respective marginal probabilities p(y) and p(x): This method uses MI between a feature and a class as relevance of the feature for the class, and MI between features as redundancy of each feature.
对于离散/分类变量,基于变量x和y的联合概率分布p(x,y)以及各自的边际概率p(y)和p(x)来定义两个变量x和y的互信息I:该方法在a和a之间使用MI要素和类别作为要素与类别的相关性,要素之间的MI作为每个要素的冗余。
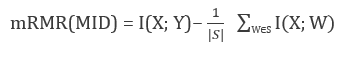
For every X in the table, S is the set of already selected attributes. Y is the target variable.
对于表中的每个X,S是已选择的属性的集合。 Y是目标变量。
Hence, this obtained mRMR score takes both Redundancy and Relevance into account for each feature. IF we take difference of both the factors above, we get MID (Mutual Information Difference) and if we take their ratio, we get MIQ (Mutual Information Quotient).
因此,此获得的mRMR分数将每个功能都考虑了冗余和相关性。 如果我们采用上述两个因素的差异,则得出MID(相互信息差异),如果采用它们的比率,则得出MIQ(相互信息商)。

Considering several examples, it has been observed that MIQ works better for most of the data sets than MID. As the divisive combination of relevance and redundancy appears to lead features with least redundancy.
考虑几个示例,已经发现MIQ对于大多数数据集比MID更好。 由于相关性和冗余的区分性组合似乎导致了具有最少冗余的要素。
Example code:
示例代码:
c. Chi square
C。 卡方
Intuition:
直觉:
It calculates the correlation between the feature and target and selects the best k features according to their chi square score calculated using following chi square test.
它计算特征与目标之间的相关性,并根据使用以下卡方检验得出的卡方得分,选择最佳的k个特征。
Algorithm:
算法:
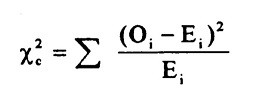
Where:
哪里:
c = degrees of freedom
c =自由度
O = observed value(s)
O =观测值
E = expected value(s)
E =期望值
Let’s consider a scenario where we need to determine the relationship between the Independent category feature (predictors) and dependent category feature (target or label). In feature selection, we aim to select the features which are highly dependent on the target.
让我们考虑一个需要确定独立类别功能(预测变量)和从属类别功能(目标或标签)之间的关系的方案。 在特征选择中,我们旨在选择高度依赖于目标的特征。
For Higher Chi-Square value, the target variable is more dependent on the feature and it can be selected for model training.
对于较高的卡方值,目标变量更多地取决于特征,可以选择它进行模型训练。
Example code:
示例代码:
d. Anova
d。 阿诺娃
Intuition:
直觉:
We perform Anova between features and target to check if they belong to same population.
我们在要素和目标之间执行Anova,以检查它们是否属于同一种群。
Algorithm:
算法:
If the value ‘variance_between / variance_within’ is less than the critical value (evaluated using log table). The library returns score and p value, for p<0.05 we mean that the confidence>95% for them to belong to the same population and hence are co-related. We select top k co-related features according to the score returned by Anova.
如果值'variance_between / variance_within'小于临界值(使用日志表进行评估)。 该库返回得分和p值,对于p <0.05,我们意味着它们属于同一总体的置信度> 95%,因此是相关的。 我们根据Anova返回的得分选择前k个相关的特征。
Example code:
示例代码:
2. Wrapper Methods
2. 包装方法
In wrapper methods, we select a subset of features from the data and train a model using them. Then we add/remove a feature and again train the model, the difference in score in both the condition decides the importance of that feature, that if the presence of it is either increasing or decreasing the score.
在包装方法中,我们从数据中选择特征子集,并使用它们训练模型。 然后,我们添加/删除特征并再次训练模型,两种情况下分数的差异决定了该特征的重要性,即如果该特征的存在会增加或降低分数。
Wrapper methods performs very well in terms of accuracy but falls short in speed when compared to other methods.
包装器方法在准确性方面表现很好,但与其他方法相比,速度较慢。
Some examples of wrapper methods are as follows:
包装方法的一些示例如下:
a. Forward Selection: It is an iterative method in which we start with zero features at the beginning and in each iteration, we keep adding the feature which best improves our model till an addition of a new variable does not improve the performance of the model.
一个。 正向选择:这是一种迭代方法,在这种方法中,我们从零要素开始,并且在每次迭代中,我们都会不断添加最能改善模型的要素,直到添加新变量不会改善模型的性能为止。
b. Backward Elimination: In this method, we start with the all the features, and remove features one by one if their absence increases the score of the model. We do this until no improvement is observed on removing any feature.
b。 向后消除:在这种方法中,我们从所有特征开始,如果特征缺失会增加模型的得分,则将它们逐一删除。 我们会这样做,直到在删除任何功能方面未发现任何改进为止。
c. Recursive Feature elimination: It is a greedy optimization algorithm which aims to find the best performing feature subset. It repeatedly creates models and keeps aside the best or the worst performing feature at each iteration. It constructs the next model with the left features until all the features are exhausted. It then ranks the features based on the order of their elimination.
C。 递归特征消除:这是一种贪婪的优化算法,旨在找到性能最佳的特征子集。 它反复创建模型,并在每次迭代时保留性能最佳或最差的功能。 它将使用剩余的特征构造下一个模型,直到所有特征都用尽。 然后,根据特征消除的顺序对特征进行排序。
Example code:
示例代码:
3. Embedded Methods
3.嵌入式方法
Embedded methods are implemented by algorithms that can learn which features best contribute to the accuracy of the model during the creation of model itself.
嵌入式方法是通过算法实现的,算法可以了解在创建模型本身期间哪些特征最有助于模型的准确性。
It combines the qualities of both filter and wrapper methods.
它结合了filter和wrapper方法的质量。
The most commonly used embedded feature selection methods are regularization methods. Regularization methods are also called penalization methods, as it introduces penalty to the objective function which decreases the number of features and hence the complexity of the model.
最常用的嵌入式特征选择方法是正则化方法。 正则化方法也称为惩罚方法,因为它给目标函数带来了惩罚,从而减少了特征数量,从而减少了模型的复杂性。
Examples of regularization algorithms are LASSO, Elastic Net and Ridge Regression.
正则化算法的示例是LASSO,弹性网和Ridge回归 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









