







第二章 语句和文件
2.1 运算符
2.1.1 算术运算符
+、-、*、/、%、**、//(取整除。不进行四舍五入)
2.1.2 比较运算符
>、>=、<、<=、==、!=
2.1.3 逻辑运算符
and、or、not
2.2 简单语句
(1)循环语句
(2)条件语句
(3)无条件分支语句
2.2.1 print
在print语句中,字符串后面会自动跟一个n,但是如果我们在要打印的字符串后面加一个逗号,那么换行就会别取消
2.2.2 import
import module_name
from module1 import module2(or function_name)
from moudle1 import function_name1 as function_name2:引入的同时给函数改名
from module import function1,function2,...,function n:从一个库中引入多个函数
from module import *:引入该库的所有方法
2.2.3 赋值
一一对应赋值:x, y, z = 1, "python", [name, "python"]
---->x : 1, y : "python", z : [name, "python"]
同时将多个值赋给一个变量:a = 1,2,3,4
---->a : (1, 2, 3, 4) #将a变成一个元组
变量值对调:x, y = y, x
链式赋值:m = n = "python"
----> m : "python" , n : "python" #用id()方法查看后发现两个标签指向的是同一对象,或者用 m is n 语句来查看是否指向同一对象,返回结果是布尔值
增量赋值:x +=1,注意字符串也可以进行增量赋值
"py" += "th"---->"pyth"
2.3 条件语句
2.3.1 if语句
此语句最后要加冒号,而且下面一行执行的语句块要缩排四个空格。用制表符和其他数目的空格虽然也行,但是不建议
2.3.2 if ...elif ...else
if 条件1: 语句块1 elif 条件2:语句块2 ... else : 语句块3
注意py文件第一句话要加上#!usr/bin/env python #coding:utf-8
2.3.3 三元操作符
X = a if T else b:如果T为真,则X=a,如果T为假,则X=b
2.4 for循环
for 循环条件:操作内容
2.4.1 简单的for循环
2.4.2 range(start, stop[, step])
1、此函数返回一个列表,且其中参数只能是整数
2、start默认为0,step(步长)默认为1,且step不能为负数
3、返回列表为[start, start + 1 * step, start + 2 * step,..., start + n * step] 返回的列表中只包括sart,并不包括stop
2.4.3 for的对象
所有的序列类型都能用for循环
2.4.4 zip()
zip()返回的是一个元组组成的列表

zip()函数的参数必须是序列类型,如果是字典的话,会将字典的值当成序列并返回,而不是返回字典的键
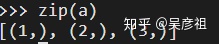
如果只有一个参数,会将参数中的元素单个拿出并返回元组列表
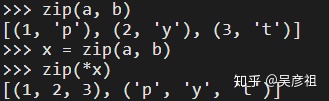
zip(*x)类似将拉链拉在一起的元组分开,不过返回的依然是一个元组列表
2.4.5 enumerate()
Return an enumerate object. sequence must be a sequence, an iterator, or some other object which supports iteration. The next() method of the iterator returned by enumerate() returns a tuple containing a count (from start which defaults to 0) and the values obtained from iterating over sequence

以上说明enumerate()内容可迭代,该函数返回的是一个元组(x, y) 其中第一个是元素的索引,第二个是元素

enumerate(iterable [, start = 0]) start默认为0
若想将字符串用enumerate()会将一个字符一个字符的打印出来,若想将字符串整个打印,需要先将字符串转换成列表
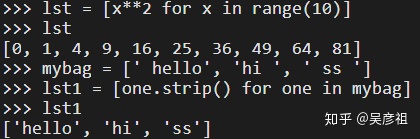
2.4.6 列表解析
2.5 while循环
2.5.1 猜数字游戏
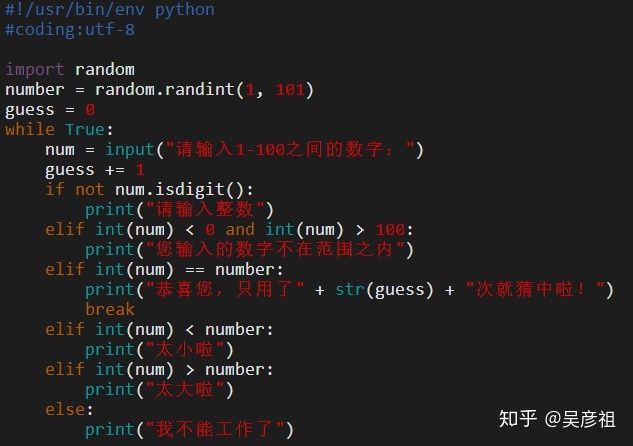
str.isdigit()用来判断字符串是否有纯粹的数字组成
2.5.2 break和continue
break就是跳出最内层循环体
continue是结束本次循环,直接跳到下一次循环的开始
2.5.3 while...else
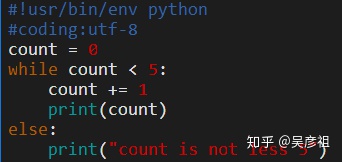

2.5.4 for ...else
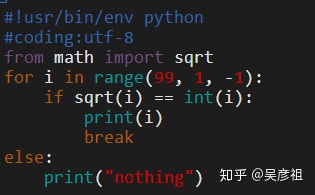
打印结果为:nothing
2.6 文件
2.6.1 打开文件
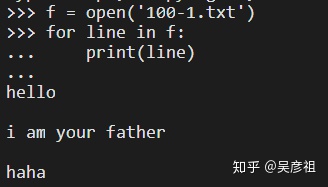
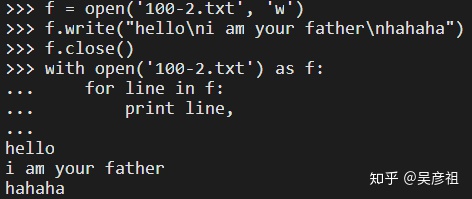
第一种方式:f = open("xx/xx/x/105-6.txt", "r") 此方法要记得用f.close()来关闭文件
第二种方式:with open("xx/xx/x/105-6.txt", "r") as f: 此方法不用f,close()进行关闭。注意此方法要在后面加冒号。
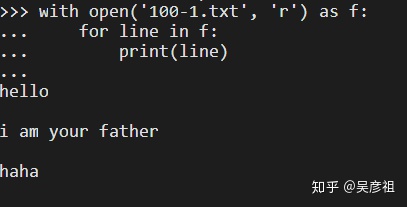
for 循环文件内容是一行一行进行循环,而文件内容的每一行的结束都会有一个换行符n,而print函数打印字符串时会在字符串后面自动加上n,这样每一行的结束就会有nn。所以打印出来的时会有一行空白,解决此问题的方法就是在打印的line后面加上一个逗号。
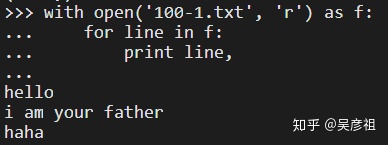
每次for循环遍历结束后,指针会停在文件内容的最后,如果再次用for循环遍历,则不会出现内容。解决此问题的方法是将指针移动到文件内容的开始或者重新打开该文件进行遍历
注意如果文件和python在同一目录的话,再打开文件的时候要加上文件的路径名
2.6.2 创建文件
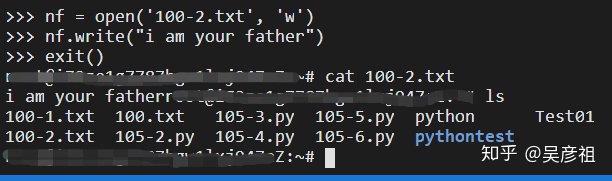
打开模式:
r:以读的方式打开文件,可读取文件信息
w:以写的方式打开文件,可向文件写入信息,若文件存在,则清除文件内容重写入新内容
a:以追加写的模式打开文件,(指针在文末)在文末追加写入内容,文件不存在则创建
r+:以读写的方式打开文件
w+:消除文件内容,以读写方式打开文件
a+:以读写的方式打开文件,将指针移动到文章末尾
b:以二进制方式打开文件
2.6.4 文件的状态
os库中的stat()函数可以查询文件状态

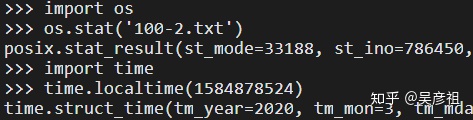
st_ctime是创建时间,os.stat()显示的创建时间是xxxx年到现在的秒数,可以用time库中的locatime()函数来转换
2.6.5 read/readline/readlines
read:如果指定size,就会读size长度,如果不指定长度,就会读全文并塞入到一个字符串中
readline:如果指定size,就会读size长度,且以行为单位返回字符串,如果不指定长度,会以行为单位返回字符串直到末尾,readline一行一行的读取,没读一行便会将指针向下移动一行
readlines:如果指定size,就会读size长度,它是返回以行为单位的字符串列表,即相当于先执行readline(),再将这些行字符串塞到一个列表中
2.6.6 读很大的文件
fileinput模块可以提供我们驱使来读取很大的文件
for line in fileinput,input('100-2.txt')
2.6.7 seek()
这个函数的功能就是移动指针。
f.seek(0):将指针移动到开头
f.tell():告诉现在指针的位置
f.seek(4) #将指针位置移动到从开头起第四个字符的后面---->f.tell():4L
seek(offset[, whence])
whence默认值为0,表示从开头计算指针偏移量,此时offset必须大于0
如果whence的值为1,表示从当前位置开始计算指针偏移量,此时如果offset为负数,表示从当前位置向前偏移,如果为正数,表示向后偏移。
whence如果为2,表示相对文末移动
2.7 迭代
(1)循环
(2)迭代
(3)递归
(4)遍历
2.7.1 迭代工具
iter()是一个内建函数,返回值是一个迭代器对象,而且其参数是一个符合迭代协议的对象或者序列对象,此函数经常和next()函数一起使用
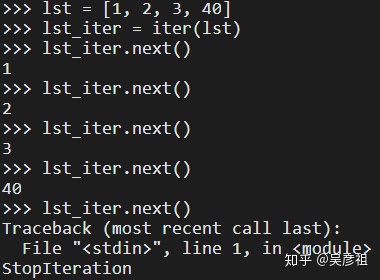
当next()遍历到文末时,继续遍历会报错
当迭代对象lst_iter被迭代结束,即每个元素都读取了一遍之后,指针就移动到了最后一个元素的后面。如果再访问,指针并没有自动返回到首位置,而是仍然停留在末位置,所以报StopIteration,想要再开始,就需要重新载入迭代对象。这种情况在for等类型的迭代工具中是没有的。
2.7.2 文件迭代器
文件是天然可迭代对象,不需要使用iter()转换。我们使用for来实现迭代,本质上就是自动调用next()。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









