






近年来,基于神经网络的偏微分方程求解器在各领域均得到了广泛关注。其中,量子变分蒙特卡洛方法(NNVMC)在量子化学领域异军突起,对于一系列问题的解决展现出超越传统方法的精确度 [1, 2, 3, 4]。北京大学与字节跳动研究部门 ByteDance Research 联合开发的计算框架 Forward Laplacian 创新地利用 Laplace 算子前向传播计算,为 NNVMC 领域提供了十倍的加速,从而大幅降低计算成本,达成该领域多项 State of the Art,同时也助力该领域向更多的科学难题发起冲击。该工作以《A computational framework for neural network-based variational Monte Carlo with Forward Laplacian》为题的论文已发表于国际顶级期刊《Nature Machine Intelligence》
- 论文链接:https://www.nature.com/articles/s42256-024-00794-x
- 代码地址:
- https://github.com/bytedance/LapNet
- https://github.com/YWolfeee/lapjax
该项工作一提出即受到相关研究人员的密切关注,围绕该工作已有多个开源项目实现,编程框架 JAX 也计划将该项工作吸收其中。
该项工作由北京大学智能学院王立威课题组、物理学院陈基课题组联合字节跳动研究部门 ByteDance Research 一同开发完成,作者中有多位北京大学博士生在 ByteDance Research 实习。
背景简介
基于神经网络的量子变分蒙特卡洛方法(NNVMC)已成为量子化学 - 从头计算领域中一项前沿技术。它具备精度高、适用范围广等优点。但它的阿克琉斯之踵在于过高的计算成本,这也限制了该方法在实际化学问题中的应用。
作者提出了一套全新的计算框架 "Forward Laplacian",利用 Laplace 算子的前向传播,显著提升了 NNVMC 方法的计算效率,为人工智能在微观量子问题中的应用打开了新的大门。
方法介绍
Forward Laplacian 框架
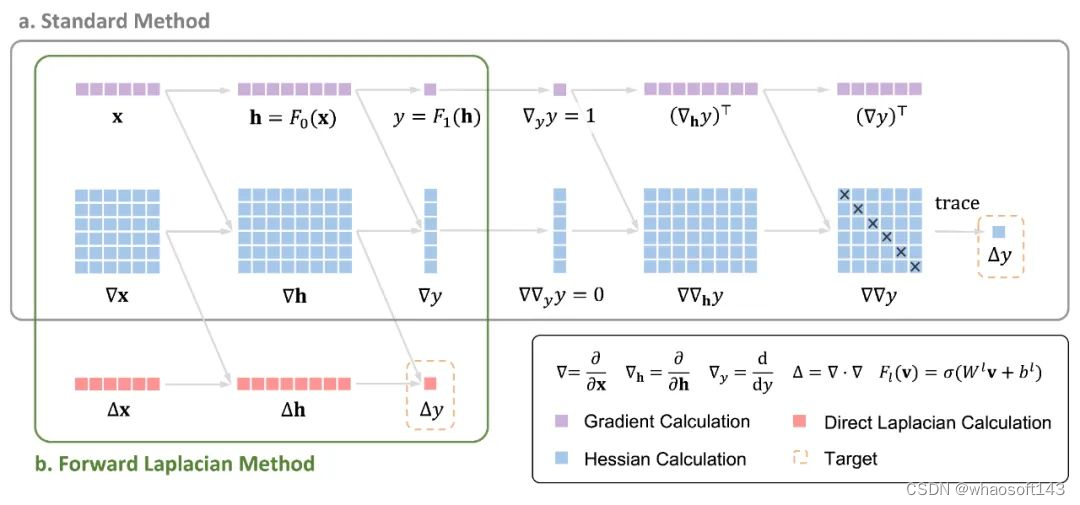
在 NNVMC 方法中,神经网络的目标函数是微观体系的能量,包括动能与势能两项。其中动能项涉及对神经网络的拉普拉斯算子的计算,这也是 NNVMC 中耗时最长的计算瓶颈。现有的自动微分框架在计算拉普拉斯算子时,需要先计算黑塞矩阵,再求得拉普拉斯项(即黑塞矩阵的迹)。而作者所提出的计算框架 "Forward Laplacian" 则通过一次前向传播直接求得拉普拉斯项,避免了黑塞矩阵的计算,从而削减了整体计算的规模,实现了显著加速。
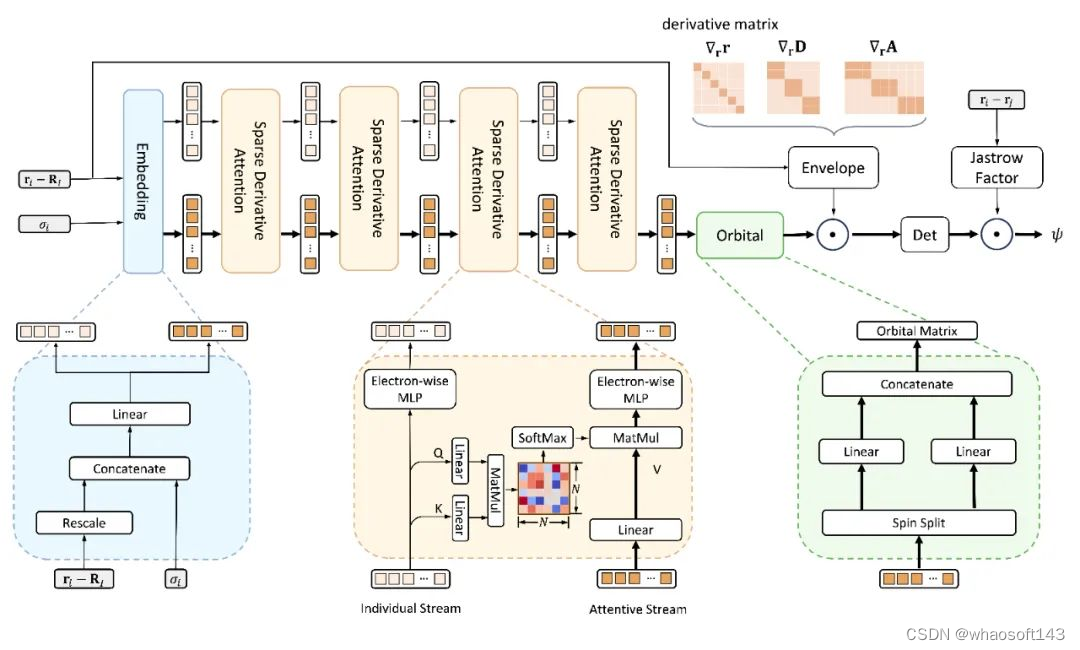
LapNet 网络
除了有效削减计算图规模之外,Forward Laplacian 框架的另一大特点是能有效利用神经网络梯度计算中的稀疏性,提出神经网络结构 LapNet。LapNet 通过增加神经网络中的稀疏性,在精度无损的同时,显著提升了网络计算的效率。
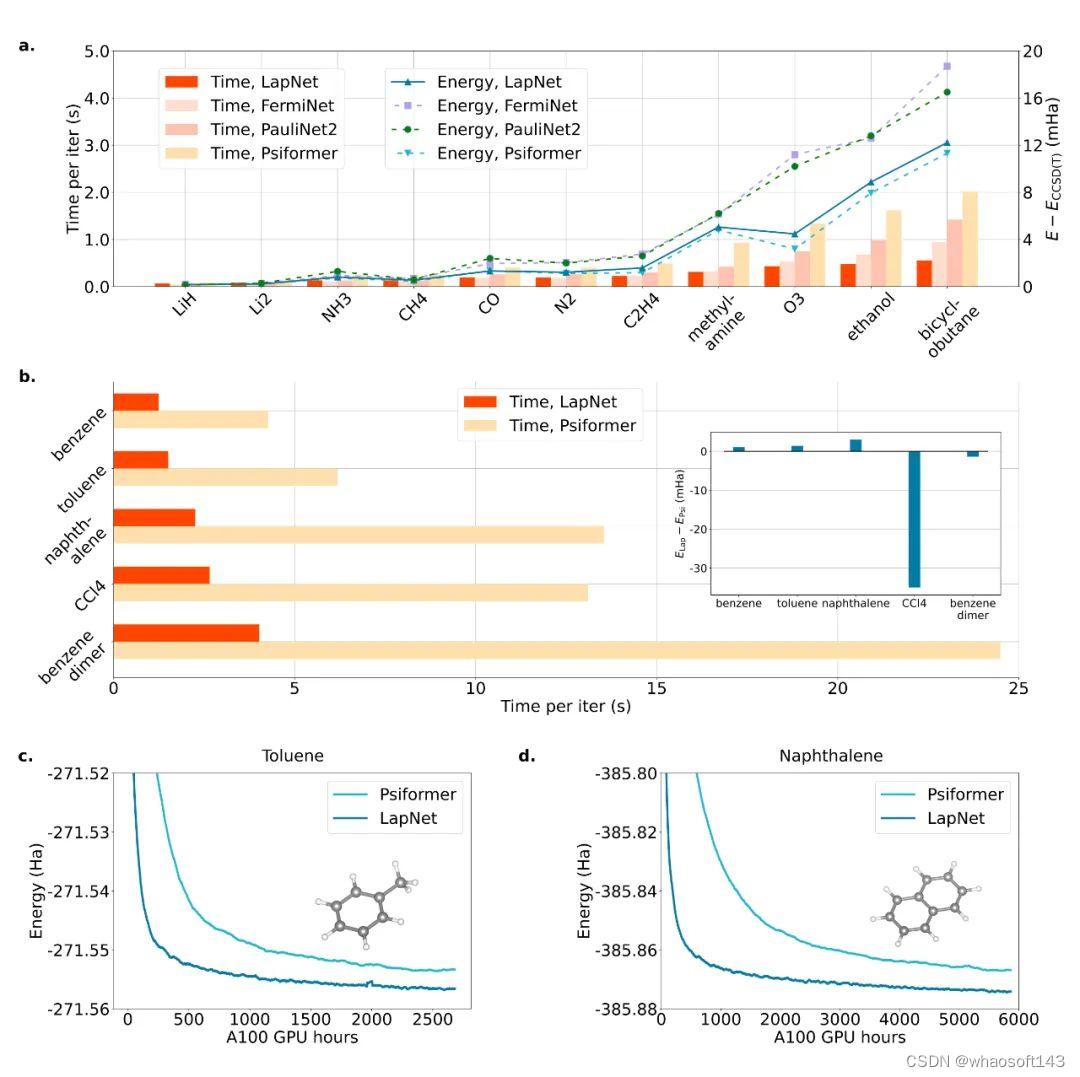
计算结果
绝对能量
作者首先就方法的效率及精度同当前 NNVMC 领域有代表性的几项工作进行了比较。从绝对能量的计算结果而言,作者提出的 LapNet 在 Forward Laplacian 框架下的效率高于参考工作数倍,精度上也与 SOTA 保持一致。此外,如果在相同计算资源(即相同 GPU hour)的情况下比较,LapNet 的计算结果可以显著优于之前的 SOTA。
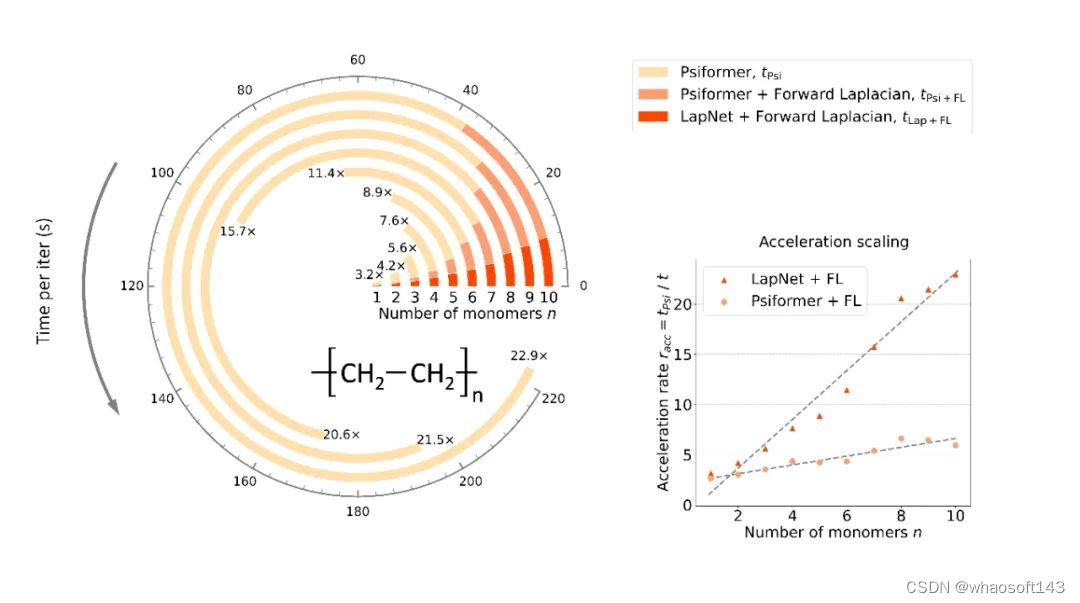
加速标度
为了更明确地研究作者所提出方法相比于之前 SOTA 的加速标度,作者在不同大小的链式聚乙烯体系上进行了测试,结果可以很明显地看到 Forward Laplacian 工作带来的 O (n) 加速。此处 n 为目标分子中的电子数目。
相对能量
在物理、化学研究中,相对能量相较于绝对能量具有更明确的物理意义。作者也在一系列的体系上进行了测试,均取得了理想结果。

总结
为降低基于神经网络的量子变分蒙特卡洛方法(NNVMC)的使用门槛,北京大学与字节跳动研究部门 ByteDance Research 联合开发了计算框架 Forward Laplacian,实现了十倍的加速。该工作已受到相关研究人员的广泛关注,期望能够推动 NNVMC 方法在更多科学问题中发挥重要作用。















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









