






flag:
泛型是什么?
使用泛型的好处是什么?
java中的泛型是如何工作的?关于类型擦除的原理?
泛型中的通配符有哪些?有什么区别和作用?
自定义泛型类、泛型方法、泛型参数
编写一段泛型程序来实现LRU缓存?
1. 什么是泛型
泛型 指的是可以将类型作为参数进行传递,其本质上就是类型参数化。比如:我们平时定义一个方法的时候,常会指定要传入一个具体类对象作为参数。而如果使用泛型,那么这个具体传入类的对象,就可以指定为某个类型,而不必指定具体的类。也就是我们将某个类型作为参数进行传递了。
//普通方法
public void testValue(String s) {}
//泛型方法
public void testValue(T t) {}
2.为什么要有泛型
关于使用泛型与使用 Object 有什么区别?
如果我们使用Object,就要将传入的类型强制转换成我们需要的类型,如果 传入的类型不匹配 将会导致程序包 ClassCastException 异常。
泛型在集合中的使用为例:
public class genericity {
public static void main(String[] args) {
List list = new ArrayList();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
// 不使用泛型可能会存在数据安全问题
list.add(111);
list.add(new Object());
}
}
List list2 = new ArrayList();
list2.add(111); // 声明为 String 类型时,赋值为 111 会报错
为什么要有泛型(Generic)?
解决元素存储的安全性问题
解决获取数据元素时,需要类型强转的问题
图解上述代码:
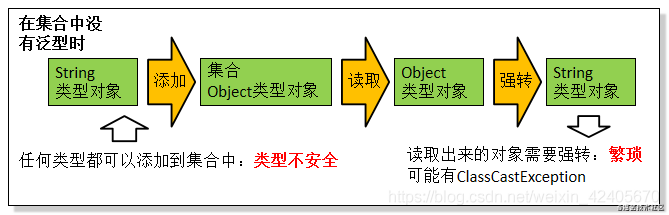
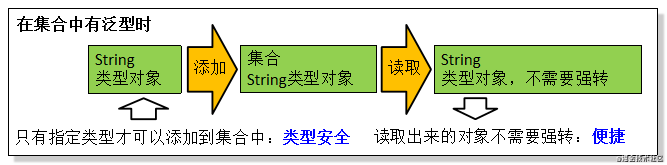
在以上例子中,我们可以总结出,使用泛型的一些好处:
它可以避免类型强制转换,而引起的程序异常。
可以使代码更加简洁规范。
是代码更加灵活,可定制型强。
最重要的一点: 解决了传参类型的安全性问题 。 在声明了 List 后只有指定类型才可以 进行传参,实现类型安全**,并且相对的,如果取值也使用该泛型方式,则可以实现 读取出来的对象不需要强转 ,达到快速便捷的目的。**
3. Java的泛型是如何工作的?
泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。
当泛型被擦除后,他有两种转换方式,第一种是如果泛型没有设置类型上限,那么将泛型转化成Object类型,第二种是如果设置了类型上限,那么将泛型转化成他的类型上限。
例如 List 在运行时仅用一个List来表示。这样做的目的,是确保能和Java 5之前的版本开发二进制类库进行兼容。你无法在运行时访问到类型参数,因为编译器已经把泛型类型转换成了原始类型。
//未指定上限
public class Test1 {
T t;
public T getValue() {
return t;
}
public void setVale(T t) {
this.t = t;
}
}
//指定上限
public class Test2 {
T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
//通过反射调用获取他们的属性类型
@Test
public void testType1() {
Test1 test1 = new Test1<>();
test1.setVale("11111");
Class extends Test1> aClass = test1.getClass();
for (Field field : aClass.getDeclaredFields()) {
System.out.println("Test1属性:" + field.getName() + "的类型为:" + field.getType().getName());
}
Test2 test2 = new Test2();
test2.setT(new ArrayList());
Class extends Test2> aClass2 = test2.getClass();
for (Field field : aClass2.getDeclaredFields()) {
System.out.println("test2属性:" + field.getName() + "的类型为:" + field.getType().getName());
}
}
上面方法打印的结果:
Test1属性:t的类型为:java.lang.Object
Test1属性:this$0的类型为:com.company.genericity
test2属性:t的类型为:java.util.List
test2属性:this$0的类型为:com.company.genericity
4.泛型晋级使用(泛型与继承的关系)
继承关系
即设置泛型上限,传入的泛型必须是Parent类型或者是他的子类
public void testType(T t) {}
依赖关系的使用
泛型间可以存在依赖关系,比如下面的C是继承自E。即传入的类型是E类型或者是E类型的子类
public void testDependys(E e, C c) {}
5. 泛型中的通配符有哪些?有什么区别和作用?
当我们不知道或者不关心实际操作类型的时候我们可以使用 无限通配符 ,当我们不指定或者不关心操作类型,但是又想进行一定范围限制的时候,我们可以通过添加 上限 或 下限 来起到限制作用。
无限通配符
无限通配符表示的是未知类型,表示不关心或者不能确定实际操作的类型,一般配合容器类使用。
public void testV(List> list) {}
需要注意的是: 无限通配符只能读的能力,没有写的能力。
public void testV(List> list) { Object o = list.get(0); //编译器不允许该操作 // list.add("jaljal");}
上面的List>为无限通配符,他只能使用get()获取元素,但不能使用add()方法添加元素。(即使修改元素也不被允许)
定义了上限,其只有读的能力。此方式表示参数化的类型可能是所 指定的类型 ,或者是 此类型的子类 。
//t1要么是Test2,要么是Test2的子类public void testC(Test1 extends Test2> t1) { Test2 value = t1.getValue(); System.out.println("testC中的:" + value.getT());}
定义了下限,有读的能力以及部分写的能力,子类可以写入父类。此方式表示参数化的类型可能是 指定的类型 ,或者是 此类型的父类
//t1要么是Test5,要么是Test5的父类public void testB(Test1 super Test5> t1) { //子类代替父类 Test2 value = (Test2) t1.getValue(); System.out.println(value.getT());}
通配符不能用作返回值
如果返回值依赖类型参数,不能使用通配符作为返回值。可以使用类型参数返回方式:
public T testA(T t, Test1 test1) { System.out.println("这是传入的T:" + t); t = test1.t; System.out.println("这是赋值后的T:" + t); return t;}
要从泛型类取数据时,用extends;
要往泛型类写数据时,用super;
既要取又要写,就不用通配符(即extends与super都不用)。
泛型中只有通配符可以使用super关键字,类型参数不支持 这种写法
6. 什么时候使用通配符
什么时候使用通配符
通配符形式和类型参数经常 配合使用
类型参数 的形式都可以 替代 通配符的形式
能用通配符的就用通配符 ,因为通配符形式上往往更为 简单 、 可读性也更好 。
类型参数之间有 依赖关系 、 返回值 依赖类型参数或者需要 写操作 ,则只能用 类型参数 。
源码中对泛型的使用可以参考 Collections 类的一些方法:
public static > void sort(List list)public static void sort(List list, Comparator super T> c)public static void copy(List super T> dest, List extends T> src)public static T max(Collection extends T> coll, Comparator super T> comp)
7. 编写一段泛型程序来实现LRU缓存?
这里使用 LinkedHashMap 来实现。
LinkedHashMap可以用来实现固定大小的LRU缓存,当LRU缓存已经满 了的时候,它会把最老的键值对移出缓存。LinkedHashMap提供了一个称为removeEldestEntry()的方法,该方法会被put() 和putAll()调用来删除最老的键值对。
class LRUCacheLinkedHashMap extends LinkedHashMap{ private int cacheSize; public LRUCacheLinkedHashMap(int cacheSize) { // true 表示让 linkedHashMap按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部。 super(16, 0.75F, true); this.cacheSize = cacheSize; } @Override protected boolean removeEldestEntry(Map.Entry eldest) { // 当map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。 return size()> cacheSize; }}















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









