






SACK介绍:
SACK:Selective Acknowledgment (SACK)(参看),这种方式需要在TCP头里加一个SACK的东西,ACK还是Fast
Retransmit的ACK,SACK则是汇报收到的数据碎版。参看下图:
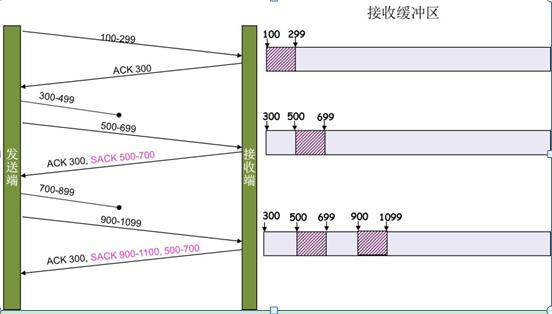
即使包2(假设从0到9的序列)是在传送过程中惟一丢失的包,接收方也只能对包1发出一个普通的ACK,因为这是连续接收到的包中的最后一个。另一方面,SACK接收方可以发出包1的ACK和包3到包9的SACK选项。这种附加信息可以帮助发送方确定丢失的包最少,只需重新传送很少的数据。如果没有这种附加信息,它需要重新传送大量的数据,这样会降低传送速率,从而适应高丢包率的网络。
在高延迟的连接中,SACK对于有效利用所有可用带宽尤其重要。高延迟会导致在任何给定时刻都有大量正在传送的包在等待应答。在Linux中,除非得到应答或不再需要,这些包将一直存放在重传队列中。这些包按照序列编号排队,但不存在任何形式的索引。当需要处理一个收到的SACK选项时,TCP协议栈必须在重传队列中找到应用了SACK的包。重传队列越长,找到所需的数据就越困难。
每个包中的最多包含4个SACK选项。
SACK会消耗发送方的资源,假设,如果一个攻击者给数据发送方发一堆SACK的选项,这会导致发送方开始要重传甚至遍历已经发出的数据,这会消耗很多发送端的资源。
在正常的网络传输中,在TCP报文的选项中没有SACK,当发送方和接收方都支持SACK选项时,当在传输过程中有数据包丢失,重传发送时,就可以在TCP报文选项中包含SACK选项,用于表明我接收到的数据包,用来提示发送端,接收端没有接收到的数据包。
(1) tcp_sack参数,
该参数标识是否启用选择性确认SACKS选项。默认值为1(true)。TCP
SACK(Selective
Acknowledgment)
这个可以在/proc/sys/net/ipv4#目录下的tcp_sack文件中查看参数
cat tcp_sack
1
可见Linux内核是默认打开该选项信息的。使用的Linux内核版本为: uname -a
Linux 2.6.32-21-generic-pae #32-Ubuntu SMP Fri Apr 16 09:39:35
UTC 2010 i686 GNU/Linux
SACK可以用来查找特定丢失的段,因此有助于快速恢复状态,同时,启用SACK,接收方可以用选择地应答乱序接收到的段,可帮助发送方确定丢失的段,进而发送方只需要发送丢失的段,以提高性能。对于广域网通信来说应该启用该选项,但是这会增加CPU负荷。
这篇文章主要是分析内核中对该选项信息的处理。该选项信息的宏定义在nf_conntrack_tcp.h文件中:
/* SACK is permitted by the sender */
#define IP_CT_TCP_FLAG_SACK_PERM 0x02
在建立tcp的会话时,会设置该值,在tcp_new函数中。
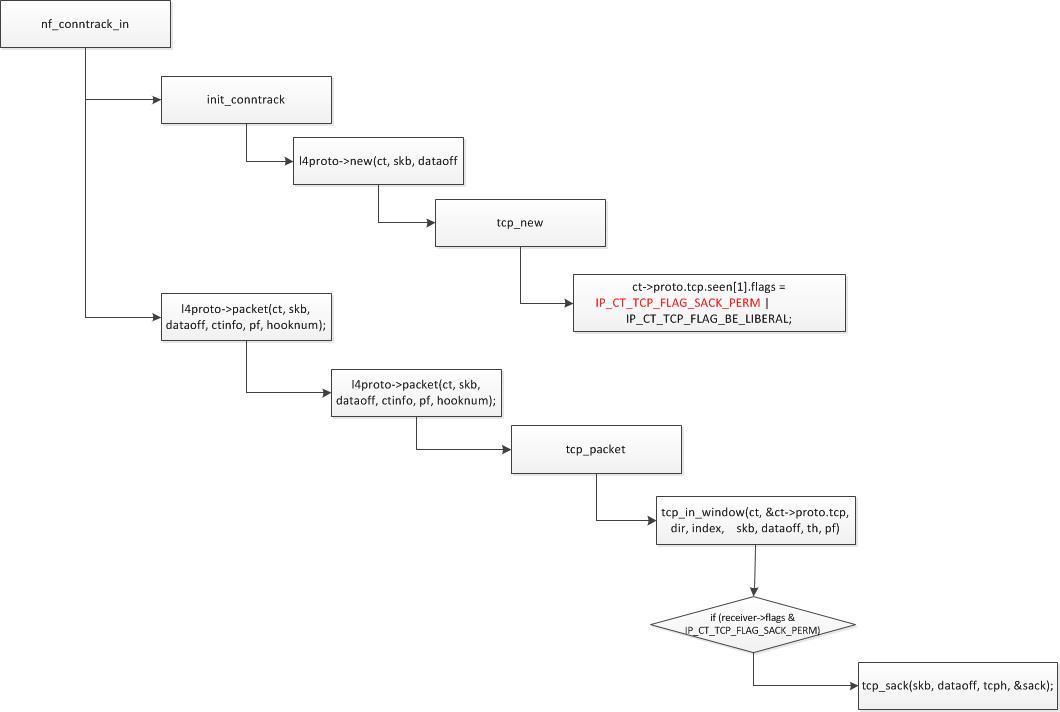
在tcp_new()函数中有下面的赋值:
static bool tcp_new(struct nf_conn *ct, const struct sk_buff *skb,
unsigned int dataoff)
{
enum tcp_conntrack new_state;
const struct tcphdr *th;
struct tcphdr _tcph;
const struct ip_ct_tcp_state *sender = &ct->proto.tcp.seen[0];
const struct ip_ct_tcp_state *receiver = &ct->proto.tcp.seen[1];
th = skb_header_pointer(skb, dataoff, sizeof(_tcph), &_tcph);
BUG_ON(th == NULL);
/* Don't need lock here: this conntrack not in circulation yet */
new_state
= tcp_conntracks[0][get_conntrack_index(th)]
[TCP_CONNTRACK_NONE];
/* Invalid: delete conntrack */
if (new_state >= TCP_CONNTRACK_MAX) {
pr_debug("nf_ct_tcp: invalid new deleting.\n");
return false;
}
if (new_state == TCP_CONNTRACK_SYN_SENT) {
/* SYN packet */
ct->proto.tcp.seen[0].td_end =
segment_seq_plus_len(ntohl(th->seq), skb->len,
dataoff, th);
ct->proto.tcp.seen[0].td_maxwin = ntohs(th->window);
if (ct->proto.tcp.seen[0].td_maxwin == 0)
ct->proto.tcp.seen[0].td_maxwin = 1;
ct->proto.tcp.seen[0].td_maxend =
ct->proto.tcp.seen[0].td_end;
tcp_options(skb, dataoff, th, &ct->proto.tcp.seen[0]);
ct->proto.tcp.seen[1].flags = 0;
} else if (nf_ct_tcp_loose == 0) {
/* Don't try to pick up connections. */
return false;
} else {
/*
* We are in the middle of a connection,
* its history is lost for us.
* Let's try to use the data from the packet.
*/
ct->proto.tcp.seen[0].td_end =
segment_seq_plus_len(ntohl(th->seq), skb->len,
dataoff, th);
ct->proto.tcp.seen[0].td_maxwin = ntohs(th->window);
if (ct->proto.tcp.seen[0].td_maxwin == 0)
ct->proto.tcp.seen[0].td_maxwin = 1;
ct->proto.tcp.seen[0].td_maxend =
ct->proto.tcp.seen[0].td_end +
ct->proto.tcp.seen[0].td_maxwin;
ct->proto.tcp.seen[0].td_scale = 0;
/* We assume SACK and liberal window checking to handle
* window scaling */
ct->proto.tcp.seen[0].flags =
ct->proto.tcp.seen[1].flags = IP_CT_TCP_FLAG_SACK_PERM |
IP_CT_TCP_FLAG_BE_LIBERAL;
}
在tcp_in_window函数中有下面的配置
static bool tcp_in_window(const struct nf_conn *ct,
struct ip_ct_tcp *state,
enum ip_conntrack_dir dir,
unsigned int index,
const struct sk_buff *skb,
unsigned int dataoff,
const struct tcphdr *tcph,
u_int8_t pf)
{
struct net *net = nf_ct_net(ct);
struct ip_ct_tcp_state *sender = &state->seen[dir];
struct ip_ct_tcp_state *receiver = &state->seen[!dir];
const struct nf_conntrack_tuple *tuple = &ct->tuplehash[dir].tuple;
__u32 seq, ack, sack, end, win, swin;
s16 receiver_offset;
bool res;
/*
* Get the required data from the packet.
*/
seq = ntohl(tcph->seq);
ack = sack = ntohl(tcph->ack_seq);
win = ntohs(tcph->window);
end = segment_seq_plus_len(seq, skb->len, dataoff, tcph);
if (receiver->flags & IP_CT_TCP_FLAG_SACK_PERM)//根据是否设置了该标志位进行相应的处理
tcp_sack(skb, dataoff, tcph, &sack);
……………..
}
下面RFC2018中关于TCP SACK Option的结构描述。
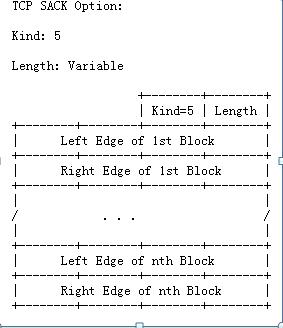
下面是通过Wireshark抓包工具,抓取到的含有TCP SACK的报文格式。
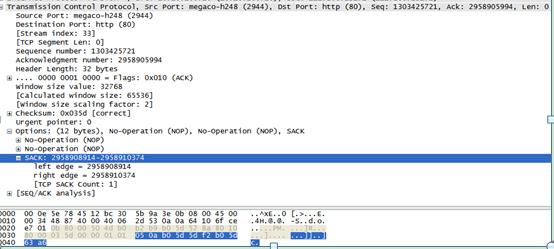
通过上面的报文格式可以看到,其表现形式符合RFC描述的结构。我们看到上面的报文中含有NOP,该选项表示的是填充值,为了32bit对齐。
我们看一下Linux内核怎么处理有该选项的数据包的,下面是Linux2.6.32内核版中处理SACK的函数tcp_sack.
点击(此处)折叠或打开
static void tcp_sack(const struct sk_buff *skb, unsigned int dataoff,
const struct tcphdr *tcph, __u32 *sack)
{
unsigned char buff[(15 * 4) - sizeof(struct tcphdr)];
const unsigned char *ptr;
int length = (tcph->doff*4) - sizeof(struct tcphdr);
__u32 tmp;
if (!length)
return;
ptr = skb_header_pointer(skb, dataoff + sizeof(struct tcphdr),
length, buff);
BUG_ON(ptr == NULL);
/* Fast path for timestamp-only option */
if (length == TCPOLEN_TSTAMP_ALIGNED*4
&& *(__be32 *)ptr == htonl((TCPOPT_NOP << 24)
| (TCPOPT_NOP << 16)
| (TCPOPT_TIMESTAMP << 8)
| TCPOLEN_TIMESTAMP))
return;
while (length > 0) {
int opcode = *ptr++;//获取选项码,
int opsize, i;
switch (opcode) {
case TCPOPT_EOL:
return;
case TCPOPT_NOP: /* Ref: RFC 793 section 3.1 */
length--;
continue;
default:
opsize = *ptr++;
//下面的代码主要判断选项长度的合法性
if (opsize < 2) /* "silly options" */
return;
if (opsize > length)
break; /* don't parse partial options */
/*下面的代码主要判断,如果选项的code为TCPOPT_SACK表示含有SACK选项信息,并且包含的选项大小大于10,因为 Left Edge of Block 和TCPOLEN_SACK_PERBLOCK各占4个字节+长度1个字节+Code 一个字节,选项中可能含有多个 edge of block,通过for循环确定第一个SACK块。
#define TCPOLEN_SACK_BASE 2
#define TCPOLEN_SACK_PERBLOCK 8
*/
if (opcode == TCPOPT_SACK
&& opsize >= (TCPOLEN_SACK_BASE
+ TCPOLEN_SACK_PERBLOCK)
&& !((opsize - TCPOLEN_SACK_BASE)
% TCPOLEN_SACK_PERBLOCK)) {
for (i = 0;
i < (opsize - TCPOLEN_SACK_BASE);
i += TCPOLEN_SACK_PERBLOCK) {
tmp = get_unaligned_be32((__be32 *)(ptr+i)+1);
if (after(tmp, *sack))//确认Left小于right,sack指向第一个SACK块
*sack = tmp;
}
return;
}
ptr += opsize - 2;
length -= opsize;
}
}
}
我们看到如果系统支持SACK的选项,会在报文中捎带Permitted Option 选项,在Linux内核中该选项信息定义为宏
#define TCPOPT_SACK_PERM 4
/* SACK Permitted */
D-SACK
RFC2883中对SACK进行了扩展,在SACK中描述的是收到的数据段,这些数据段可以是正常的,也可能是重复发送的,SACK字段具有描述重复发送的数据段的能力,在第一块SACK数据中描述重复接收的不连续数据块的序列号参数,其他SACK数据则描述其他正常接收到的不连续数据,因此第一块SACK描述的序列号会比后面的SACK描述的序列号大;而在接收到不完整的数据段的情况下,SACK范围甚至可能小于当前的ACK值。通过这种方法,发送方可以更仔细判断出当前网络的传输情况,可以发现数据段被网络复制、错误重传、ACK丢失引起的重传、重传超时等异常的网络状况。
SeqNum和Ack是以字节数为单位,所以ack的时候,不能跳着确认,只能确认最大的连续收到的包。
Duplicate SACK – 重复收到数据的问题
Duplicate SACK又称D-SACK,其主要使用了SACK来告诉发送方有哪些数据被重复接收了。RFC-2833 里有详细描述和示例。下面举几个例子(来源于RFC-2833)
D-SACK使用了SACK的第一个段来做标志,
如果SACK的第一个段的范围被ACK所覆盖,那么就是D-SACK
如果SACK的第一个段的范围被SACK的第二个段覆盖,那么就是D-SACK
示例一:ACK丢包
下面的示例中,丢了两个ACK,所以,发送端重传了第一个数据包(3000-3499),于是接收端发现重复收到,于是回了一个SACK=3000-3500,因为ACK都到了4000意味着收到了4000之前的所有数据,所以这个SACK就是D-SACK——旨在告诉发送端我收到了重复的数据,而且我们的发送端还知道,数据包没有丢,丢的是ACK包。
Transmitted
Received ACK Sent
Segment
Segment (Including SACK
Blocks)
3000-3499
3000-3499 3500 (ACK dropped)
3500-3999
3500-3999 4000 (ACK dropped)
3000-3499
3000-3499 4000, SACK=3000-3500
---------
示例二,网络延误
下面的示例中,网络包(1000-1499)被网络给延误了,导致发送方没有收到ACK,而后面到达的三个包触发了“Fast Retransmit算法”,所以重传,但重传时,被延误的包又到了,所以,回了一个SACK=1000-1500,因为ACK已到了3000,所以,这个SACK是D-SACK——标识收到了重复的包。
这个案例下,发送端知道之前因为“Fast Retransmit算法”触发的重传不是因为发出去的包丢了,也不是因为回应的ACK包丢了,而是因为网络延时了。
Transmitted
Received ACK Sent
Segment
Segment (Including SACK
Blocks)
500-999
500-999 1000
1000-1499
(delayed)
1500-1999
1500-1999 1000, SACK=1500-2000
2000-2499
2000-2499 1000, SACK=1500-2500
2500-2999
2500-2999 1000, SACK=1500-3000
1000-1499
1000-1499 3000
1000-1499 3000, SACK=1000-1500
---------
可见,引入了D-SACK,有这么几个好处:
1)可以让发送方知道,是发出去的包丢了,还是回来的ACK包丢了。
2)是不是自己的timeout太小了,导致重传。
3)网络上出现了先发的包后到的情况(又称reordering)
4)网络上是不是把我的数据包给复制了。
PS:下面通过wireshark抓包工具看看SACK的选项中的block。
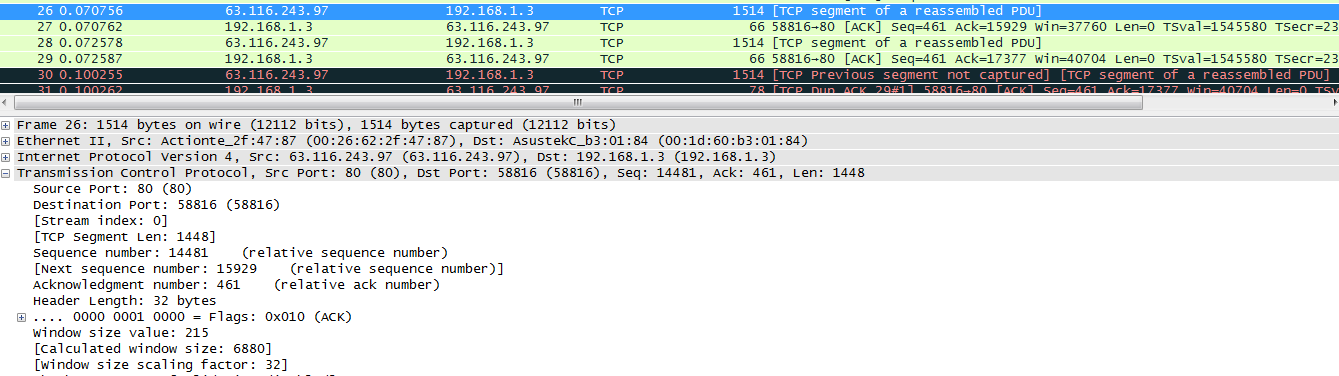
PACK#26
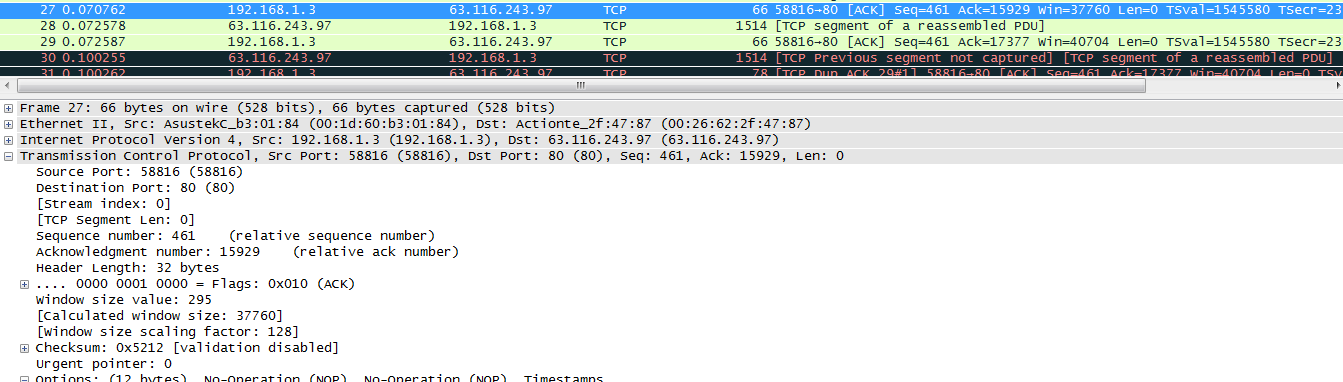
PACK#27
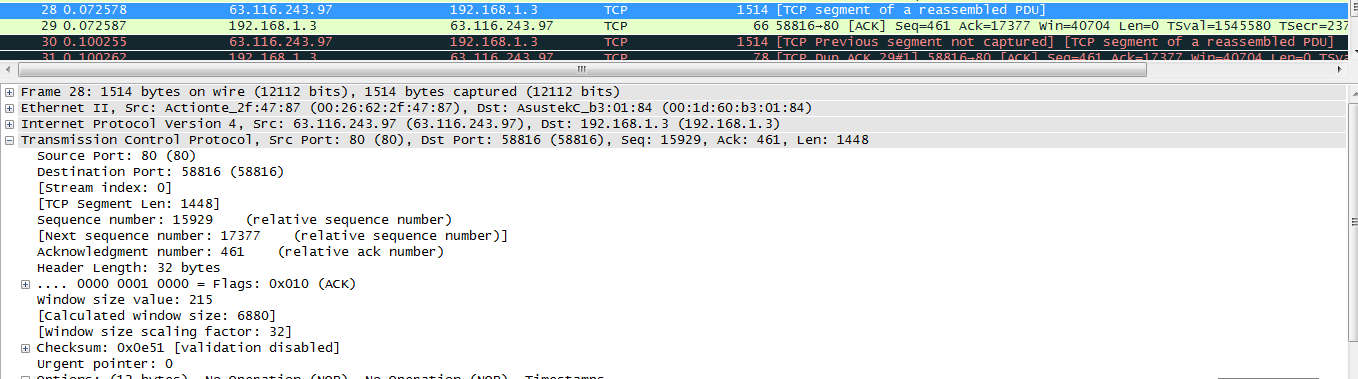
PACK#28
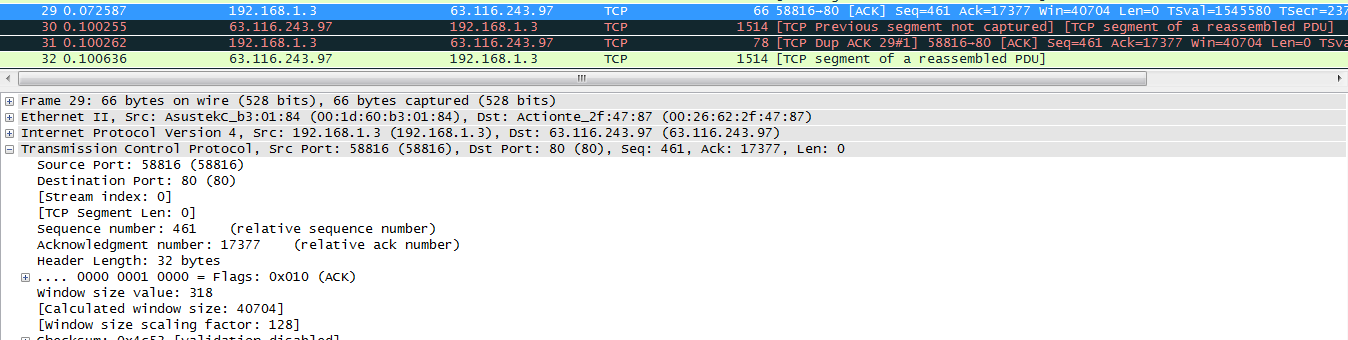
PACK#29
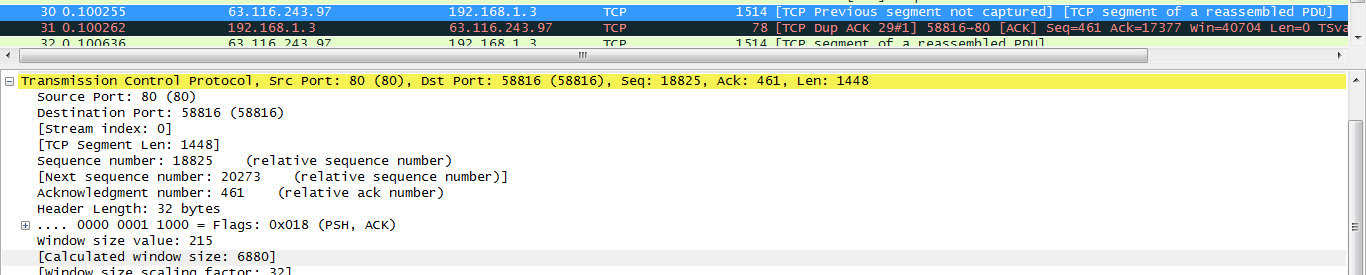
PACK#30
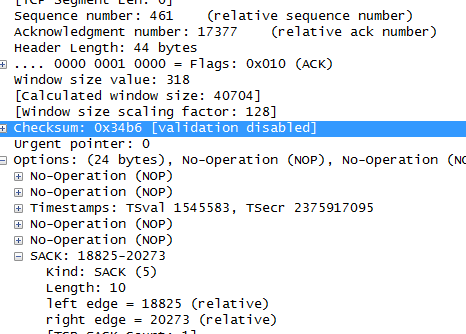
PACK#31
通过上面的几张图可以看出,PACK#26、 PACK#27、 PACK#28、 PACK#29、表示为正常的数据段, PACK#31表示是一个DUP-ACK,在该选项信息中包含有可能丢失的段,PACK#30表明传输的数据端和客户端需要的数据段不一致,通过下面的图可以确定:left_edge 和right_edge分别表示的含义。
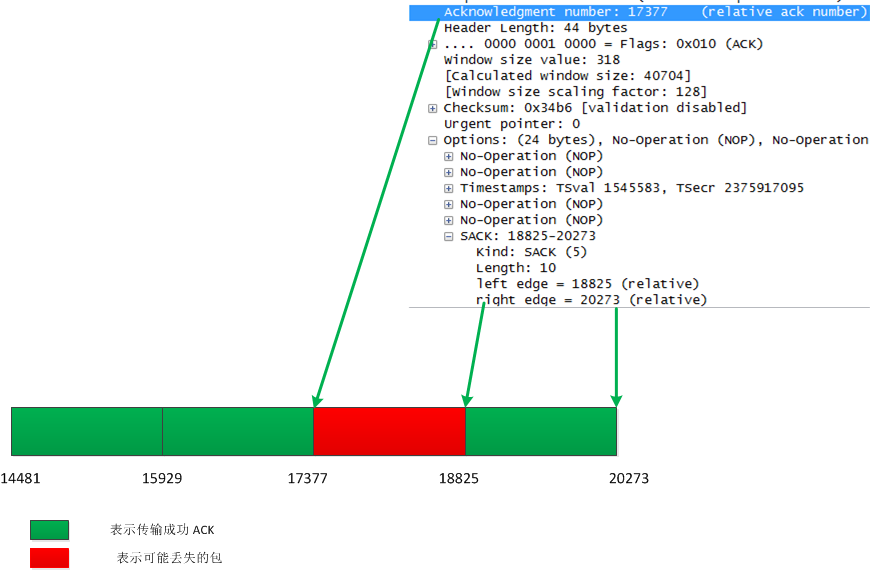
参考文献:
http://www.ibm.com/developerworks/cn/linux/l-tcp-sack/
http://packetlife.net/blog/2010/jun/17/tcp-selective-acknowledgments-sack/















 1797
1797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









