 深入剖析malloc与free源码
深入剖析malloc与free源码





大家好,这里是物联网心球。
笔者一直想写一些和读者们工作比较贴近的文章,最近发现大家对malloc和free的关注度比较高,正好笔者也认真研究过glibc源码,所以决定详细介绍一下malloc和free的底层原理和源码实现。
(本文以64位系统为例,基于glibc 2.39版本)
1.整体介绍
malloc和free属于glibc ptmalloc内存池,学习源码之前,我们先要从整体上了解ptmalloc的设计思想,图1是ptmalloc内存池的整体介绍。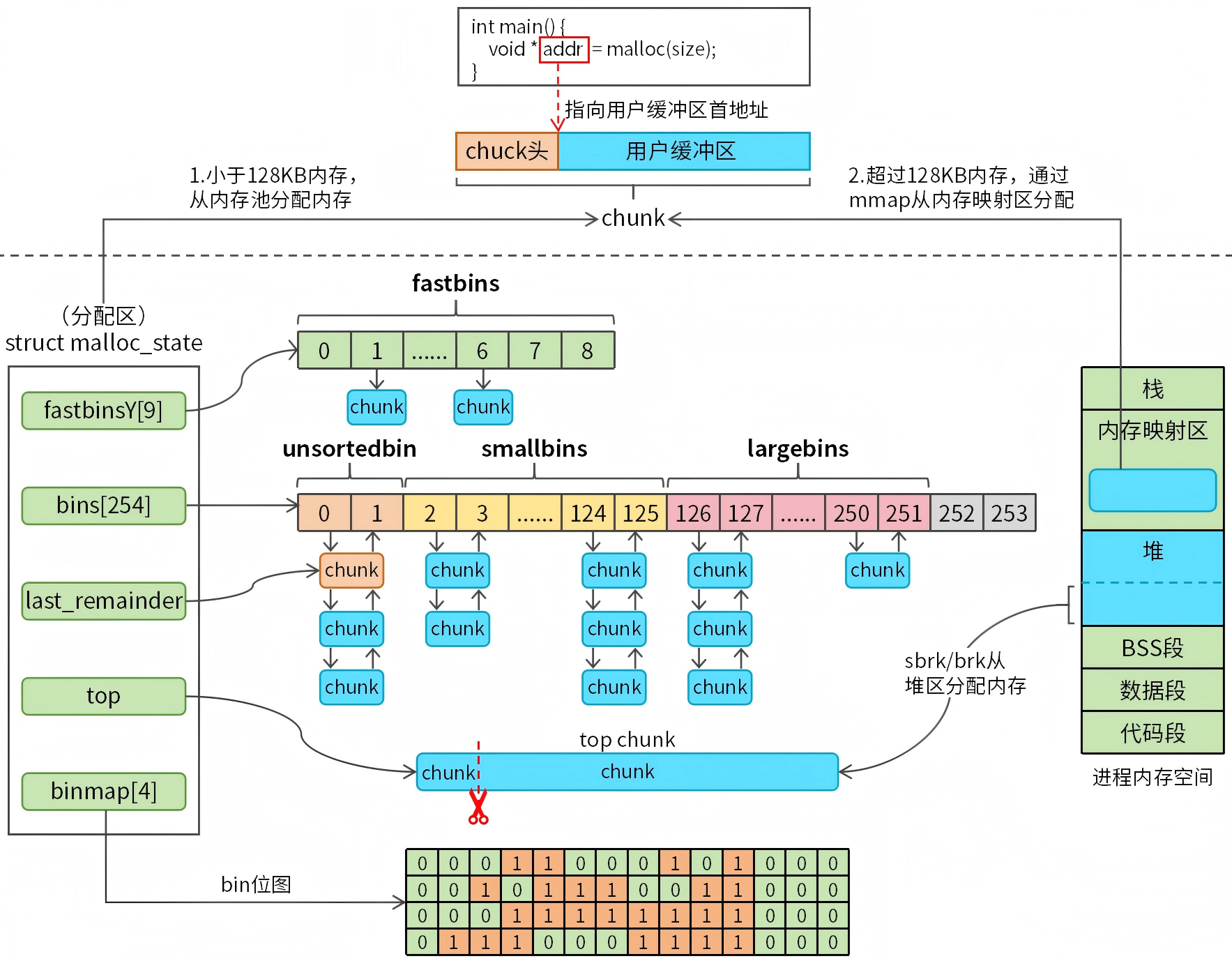
图1 整体介绍
简单来说,ptmalloc核心设计思想就两个部分:chunk和bins。
chunk指的是内存块,chunk可以分配给用户程序(已分配状态),也可以存放在内存池(空闲状态)。chunk的数据结构设计非常巧妙,可以轻松实现chunk合并和裁剪,后续会详细介绍。
内存池中通常会存放大量的chunk,chunk的大小也会有很大差异,内存池需要高效管理这些chunk,ptmalloc通过struct malloc_state结构来管理chunk,malloc_state又称arena(分配区)。struct malloc_state结构体定义(只保留关键信息)如下:
struct malloc_state {
mfastbinptr fastbinsY[NFASTBINS];
mchunkptr top;
mchunkptr last_remainder;
mchunkptr bins[NBINS * 2 - 2];
unsigned int binmap[BINMAPSIZE];
};
相关成员介绍如下:
- fastbinsY[NFASTBINS]:fastbinsY表示fastbins,数组长度为9,用于快速分配小块内存(64位系统通常为32-160字节)。
- top:表示top chunk,当其他bins中没有合适大小的chunk时,会从top chunk中裁剪出合适的chunk用于内存分配。
- last_remainder: 指向上次裁剪smallbins链表中chunk剩余的chunk。
- bins[NBINS * 2 - 2]:数组长度为254,包含三种类型的bin:
- unsortedbin:一个特殊的bin,刚释放的chunk会先放入这里,后续从unsortedbin转入其他bin。
- smallbins:62个双向链表,每个链表管理固定大小的chunk(64 位系统通常为:32-1024 字节,16 字节步进),。
- largebins:63个双向链表,每个链表管理一个范围大小的chunk(64位系统通常大于1024字节)。
- binmap[BINMAPSIZE]: 128位位图,用于快速查找smallbins和largebins中可用的chunk,避免遍历整个bins数组。
用户程序通过malloc申请内存时,如果内存池没有可用内存,系统会尝试通过sbrk和brk从堆内存扩容。如果malloc申请的内存超过128KB,那么系统会跳过内存池,直接通过mmap从内存映射区分配内存。
2.chunk介绍
在介绍chunk相关知识前,我先要强调一下chunk的重要性。chunk是ptmalloc内存池的基础,只有深入理解了chunk才能搞懂ptmalloc。
2.1 chunk是什么?
chunk是内存分配的基本单位,它其实是一个内存块。chunk被分配后能够存储用户数据,空闲时能够插入bin中,随时做好被分配的准备。
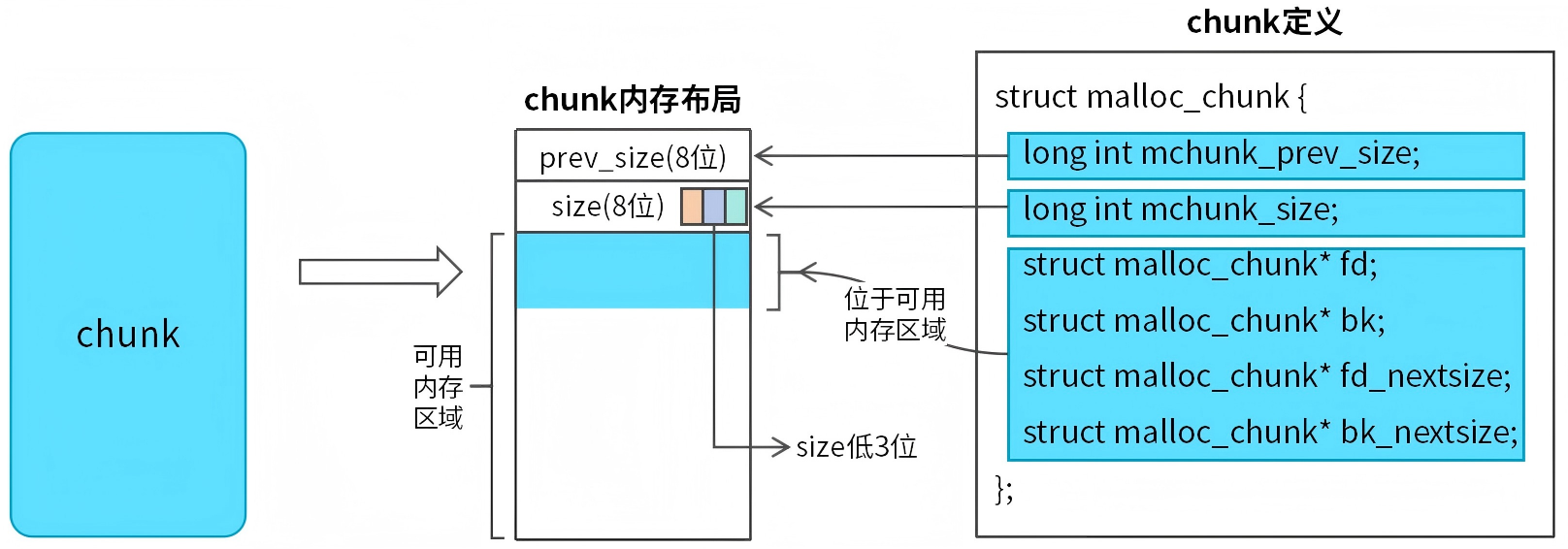
图2 chunk结构和定义
chunk的内存布局和结构如图2所示。我们把chunk划分为两个部分:chunk头和可用内存区域。
chunk头为struct malloc_chunk结构,定义如下:
struct malloc_chunk {
long int mchunk_prev_size;
long int mchunk_size;
struct malloc_chunk* fd;
struct malloc_chunk* bk;
struct malloc_chunk* fd_nextsize;
struct malloc_chunk* bk_nextsize;
};
主要字段说明如下:
- mchunk_prev_size:8字节,简称prev_size,表示前一个chunk的大小。
- mchunk_size:8字节,简称size,表示当前chunk的大小。size的低3位是标志位,3个标志说明如下:
- PREV_INUSE (P位):最低位,表示前一个chunk是否在使用中,0表示前一个chunk空闲,1表示前一个chunk已分配。
- IS_MMAPPED (M位):第二低位,表示当前chunk是否通过mmap分配。
- NON_MAIN_ARENA (A位):第三低位,表示当前chunk是否属于主线程的分配区(malloc_state)。
- fd:8字节,指向下一个空闲chunk的指针。这个字段仅在当前chunk是空闲时有效。如果当前chunk已分配,那么fd字段被复用为可用内存(8字节)。
- bk:指向前一个空闲chunk的指针。该字段和fd功能类似。
- fd_nextsize:8字节,largebins中指向下一个比当前chunk小的空闲chunk。用于largebins快速查找不同大小的空闲chunk,提高分配效率,如果当前chunk是已分配的,那么fd_nextsize字段被复用为可用内存(8字节)。
- bk_nextsize:8字节,largebins中指向前一个比当前chunk大的空闲chunk,和fd_nextsize功能类似。
从chunk内存布局可以看到,fd、bk、fd_nextsize和bk_nextsize四个字段和可用内存区域是复用的。当chunk是已分配状态时,fd、bk、fd_nextsize、bk_nextsize将被视为可用内存区域的一部分(64位系统共32字节)。当chunk变为空闲状态是,chunk需要借助fd、bk、fd_nextsize、bk_nextsize插入bin中。
注意,chunk不管是已分配还是空闲,prev_size和size字段都不会被复用。prev_size和size决定了一块虚拟地址连续的内存如何被划分为一个个chunk,我们通过一个简单的例子来说明,如图3所示。
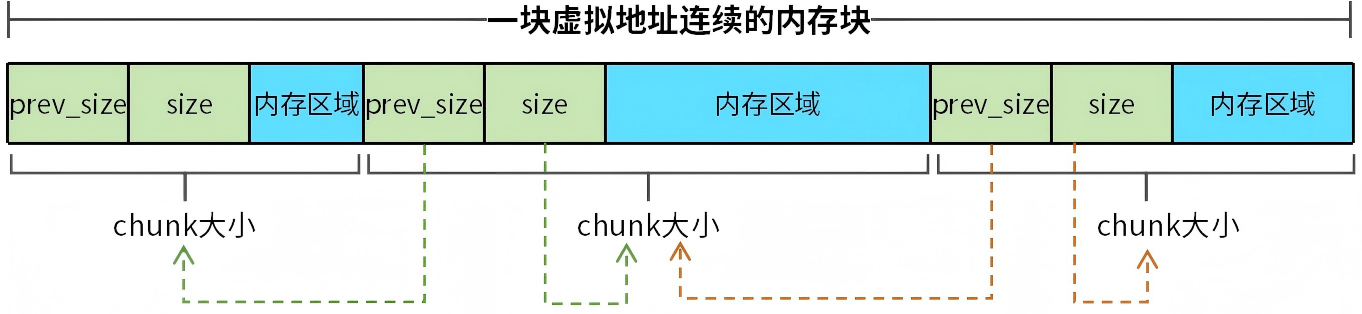
图3 prev_size和size的作用
当用户程序从堆内存分配一块内存时,首先找到该内存块的起始地址,将起始地址处前16字节转换成prev_size和size,size决定了首个chunk占用内存大小。如果我们想把内存块分为多个chunk,第二个chunk的起始地址为内存块起始地址偏移首个chunk的size大小。同理设置第二个chunk的prev_size和size,就完成了第二个chunk的内存布局。以此类推,我们可以将一块虚拟地址连续的内存块切分成不能的chunk。
注意:chunk的最小值为32字节,包括:prev_size(8字节)、size(8字节)、fd(8字节)、bk(8字节),这样即保证了chunk能够分配给用户程序,又保证了chunk能够插入bin。当用户程序申请的可用内存区域偏小,即可用内存区域、prev_size和size三者内存总和小于32字节时,系统会自动将chunk设置为32字节。如图4所示。
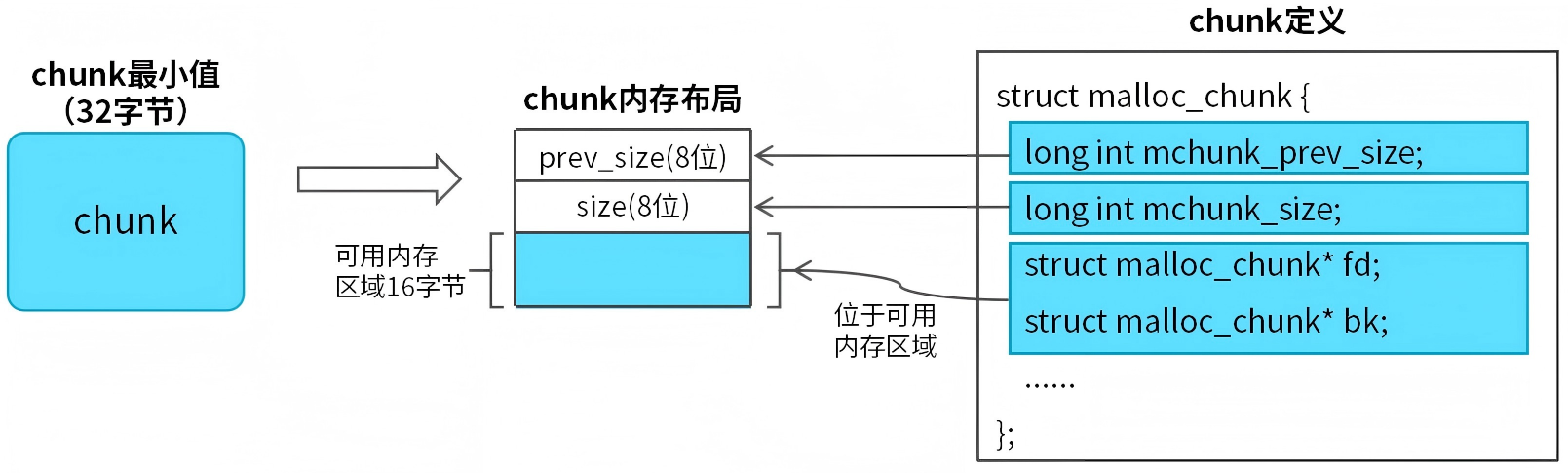
图4 chunk最小值
2.2 chunk合并和裁剪
chunk的数据结构体(struct malloc_chunk)是经过精心设计的,这种设计能够很方便地实现小块内存合并,防止内存碎片,同时大块的chunk能够裁剪成小块内存,从而减少内存的浪费。
chunk的合并和裁剪一直以来都是一个难点,很多读者对这个知识点并不了解,下面我来详细介绍它。
(1)chunk合并
chunk的合并分为:先前和并和向后合并。不管是哪种合并方式,都是将虚拟地址连续的两个chunk合并为一个chunk。我们首先来看一下向前合并,如图5所示。
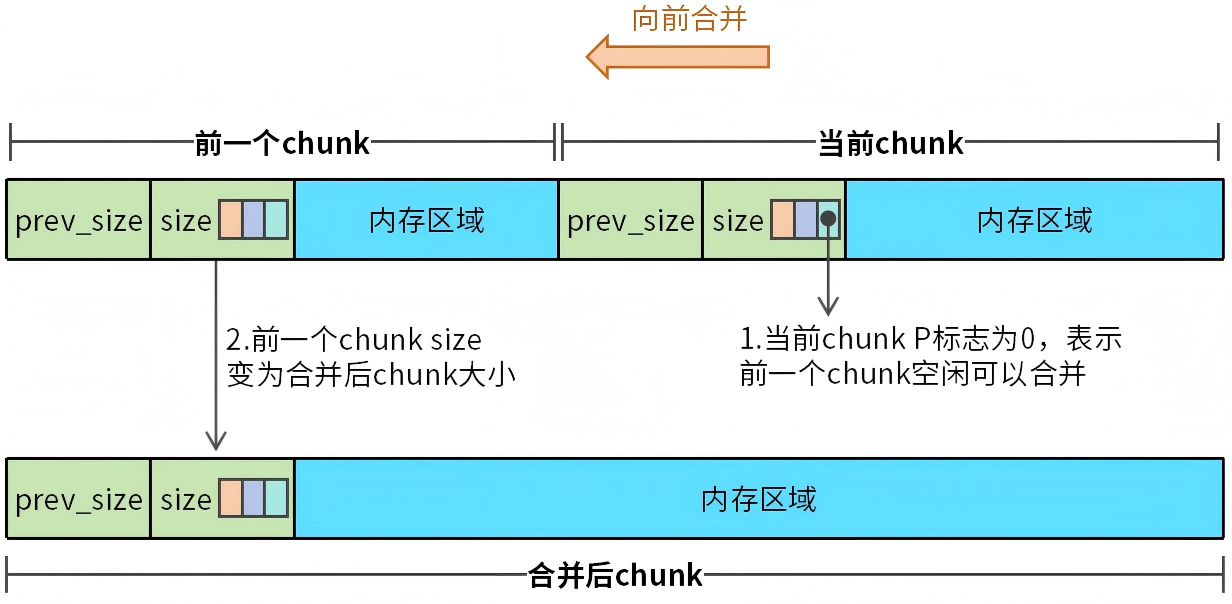
图5 chunk向前合并
向前合并的场景通常发生在当前chunk从已分配状态变为空闲状态时,此时需要执行一次向前合并的操作。在执行操作前,需要确定前一个chunk是否可以合并,如果前一个chunk已分配,那么两个chunk合并会导致程序异常。如果前一个chunk也是空闲状态,那么两个chunk可以合并。
向前合并的过程并不复杂,我们只需要把当前chunk视为前一个chunk内存区域的一部分,然后修改前一个chunk的size为合并后chunk的大小就完成了合并。
接下来来聊聊向后合并,为了提高合并效率,系统完成了向前合并之后,通常还会执行一次向后合并。向后合并的过程如图6所示。
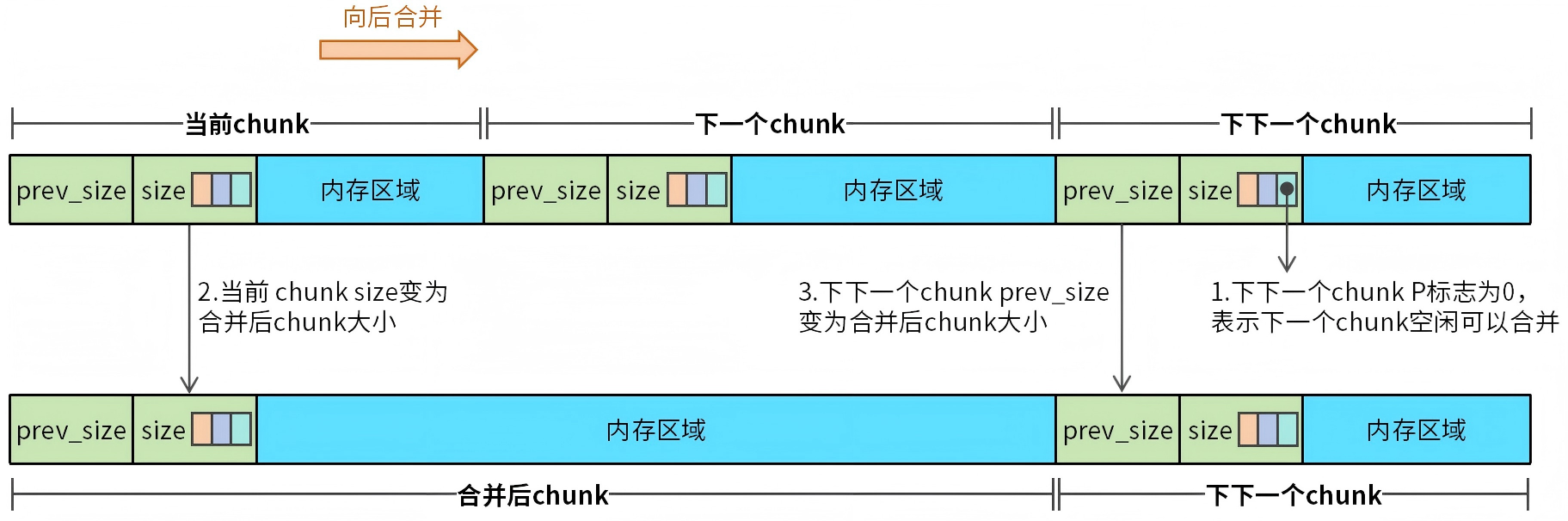
图6 chunk向后合并
向后合并同样要判断下一块chunk是否为空闲状态,判断的方法是先找到下一个chunk的下一个chunk(即下下一个chunk),然后根据下下一个chunk的P位来判断下一个chunk是否空闲。如果下一块chunk空闲,那么就能够执行向后合并的操作。
向后合并的操作步骤为:首先,下一个chunk和当前chunk执行一次向前合并操作;接着,将下下一个chunk的prev_size修改为合并后chunk的大小。
(2)chunk裁剪
当用户程序通过malloc申请内存,如果内存池中没有匹配大小的chunk,那么通常会从一个大的chunk裁剪出一个匹配的chunk给用户程序。此时需要完成一次chunk裁剪操作,chunk裁剪操作如图7所示。
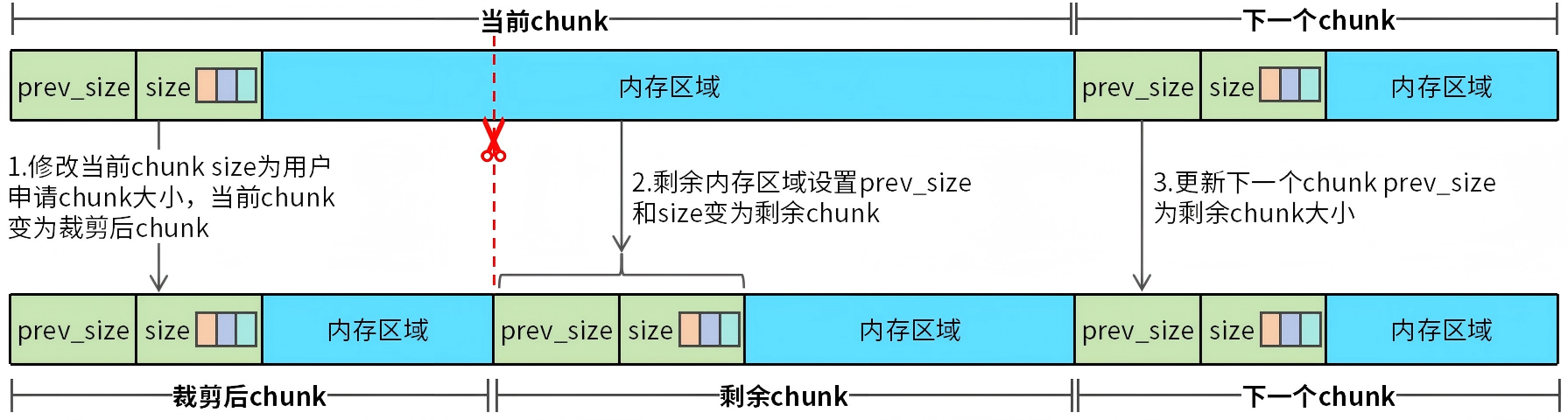
图7 chunk裁剪
需要被裁剪的chunk为当前chunk,裁剪过程如下:
首先,修改当前chunk size为用户申请的chunk大小。
接着,将当前chunk剩余内存区域重构成一个新的chunk,将剩余内存区域首地址前16字节设置prev_size和size,prev_size设置为裁剪后chunk大小,size设置为剩余内存大小。注意,此时size的低三位标志也要正确设置。
最后,还要修改下一个chunk的prev_size,将prev_size修改为剩余chunk大小。
2.3 top chunk
top chunk是堆顶的空闲chunk,它始终位于堆的末尾。当内存池中的现有的chunk无法满足分配请求时,top chunk可以扩展以提供更多的内存。当top chunk的空间不足以满足分配请求时,分配器会通过brk或mmap向操作系统请求更多内存,从而扩展top chunk的大小。
由于chunk可以很方便地进行合并和裁剪,top chunk可以裁剪出合适的chunk。当top chunk的前一个chunk空闲时,top chunk可以和前一个chunk执行一次向前合并操作,形成一个更大内存的top chunk。
3.bins介绍
chunk是内存分配的基本单元,ptmalloc需要将所有的空闲的chunk管理起来,chunk的管理需要做到精细化,不仅需要根据chunk大小进行分类,还要满足高效分配的要求。bins就是chunk管理的方式。
bin的种类很多,下面一一来介绍。
3.1 fastbins
fastbins通过单链表来管理chunk,如图8所示。
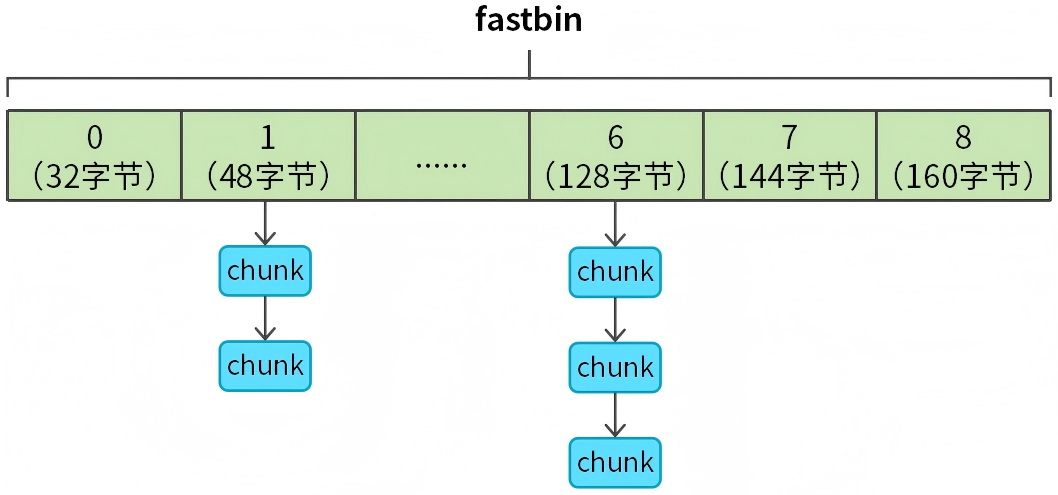
图8 fastbins介绍
malloc_state分配区中的fastbinsY[NFASTBINS]数组表示fastbins,数组长度为9,每个数组元素表示一个固定大小的chunk链表,由于是单链表,所以只需要借助hunk中的fd指针就能够完成链表操作。
fastbins数组首元素表示32字节chunk链表,用户申请的chunk小于32字节,统一按32字节chunk处理。fastbins数组以16字节步进,覆盖的chunk大小范围为32-160字节。
3.2 unsortedbin、smallbins、largebins
unsortedbin、smallbins、largebins都属于malloc_state分配区中的bins[NBINS * 2 - 2]数组,数组长度为254。如图9所示。

图9 bins数组分类
大家看到这个图,一定会有一个疑问:为什么unsortedbin占用了两个数组元素?关于这个点,笔者也踩了很多坑。网络上的很多资料对于这个点也是一笔带过,但是,这个点却是理解unsortedbin、smallbins、largebins的关键。下面我们进行详细解析,如图10所示。
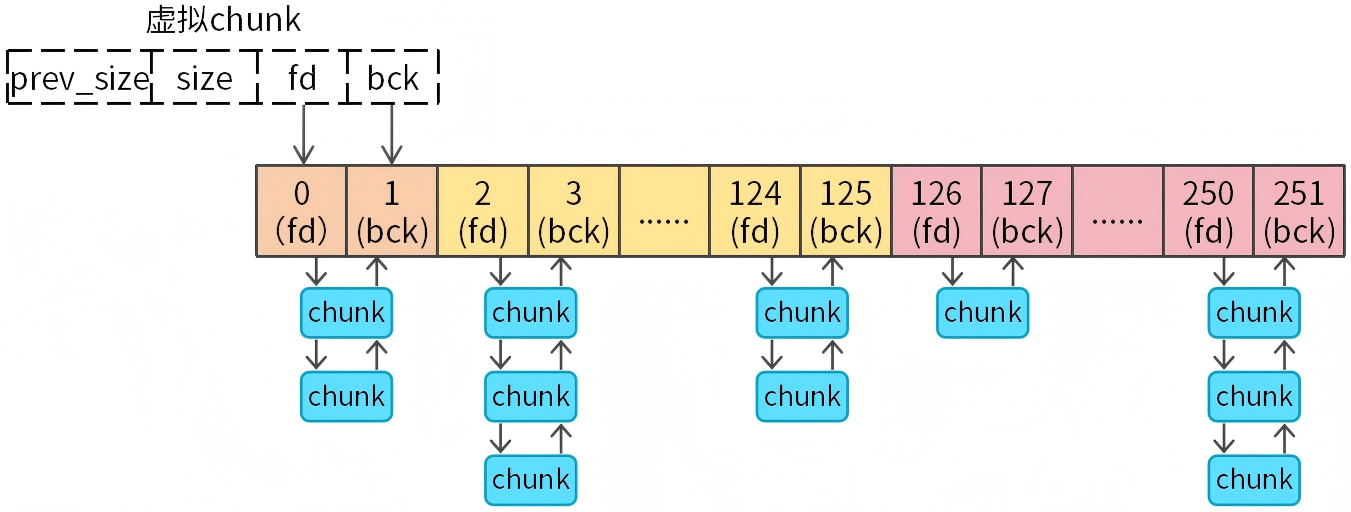
图10 bins数组解析
bins数组中的元素存放的并非chunk指针,而是存放chunk对象的fd和bck成员。bins数组类型为指针类型(struct malloc_chunk*类型,64位系统为8字节),bins数组一个元素是8个字节。chunk对象fd和bck也是8个字节,所以fd和bck都会占用一个数组元素。fd和bck分别是chunk链表的前驱指针和后驱指针,通过fd和bck就能够建立双向链表了。
bins数组中的fd和bck的范围需要借助虚拟chunk,简单来说就是把bins数组四个元素虚拟成一个chunk,最小chunk的内存布局为:prev_size(8字节)、size(8字节)、fd(8字节)、bck(8字节),刚好对应数组四个元素(32字节)。
值得注意的是,当我们访问unsortedbin(bins数组前两个元素)时,虚拟chunk的prev_size和size会超出数组范围,是否会造成数组越界呢?答案是不会。因为我们只是借助虚拟chunk来范围fd和bck成员,并不会范围虚拟chunk的prev_size和size成员。
(1)unsortedbin
bins数组的前两个元素就是unsortedbin,它是一个特殊的双向链表,用于存储那些尚未被分类的空闲chunk。当一个chunk被释放时,它首先被放入unsorted bin,而不是直接放入其他bins。这样做的目的是为了减少内存分配的开销,同时在后续的内存分配过程中,可以快速从unsortedbin中找到合适的chunk进行分配。
(2)smallbins
bins数组索引范围(2-125)表示smallbins,如图11所示。
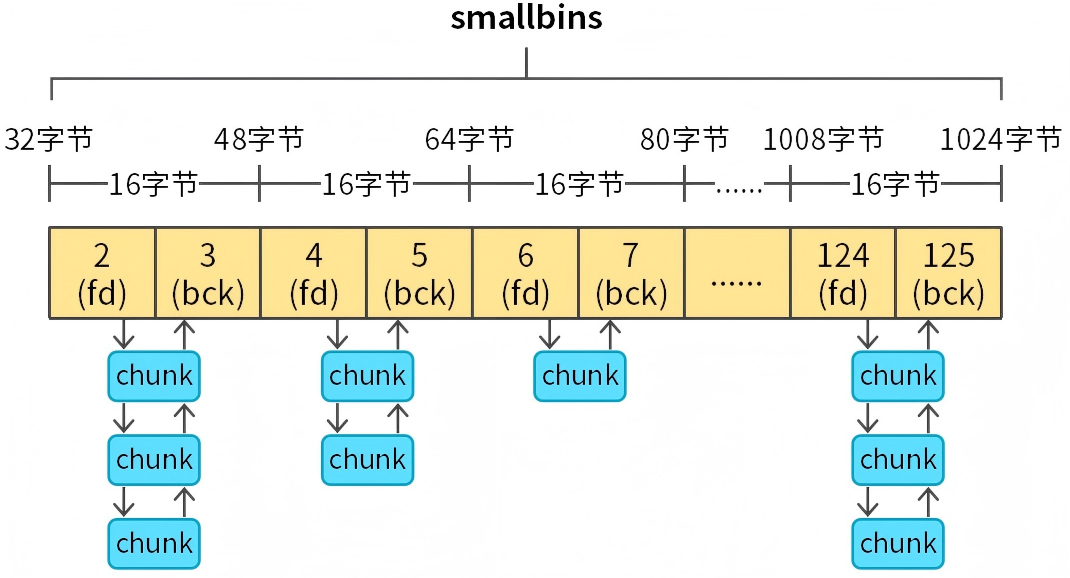
图11 smallbins介绍
smallbins共62个双向链表(通过fd和bck构成双向循环链表),每个链表中的chunk都是固定长度,以16字节步进。覆盖的内存范围为:32字节-1024字节,注意1024字节不包含在内,申请的chunk大于等于1024字节需要从largebin或者top chunk分配内存。
(3)largebins
bins数组索引范围(126-251)表示largebins,如图12所示,
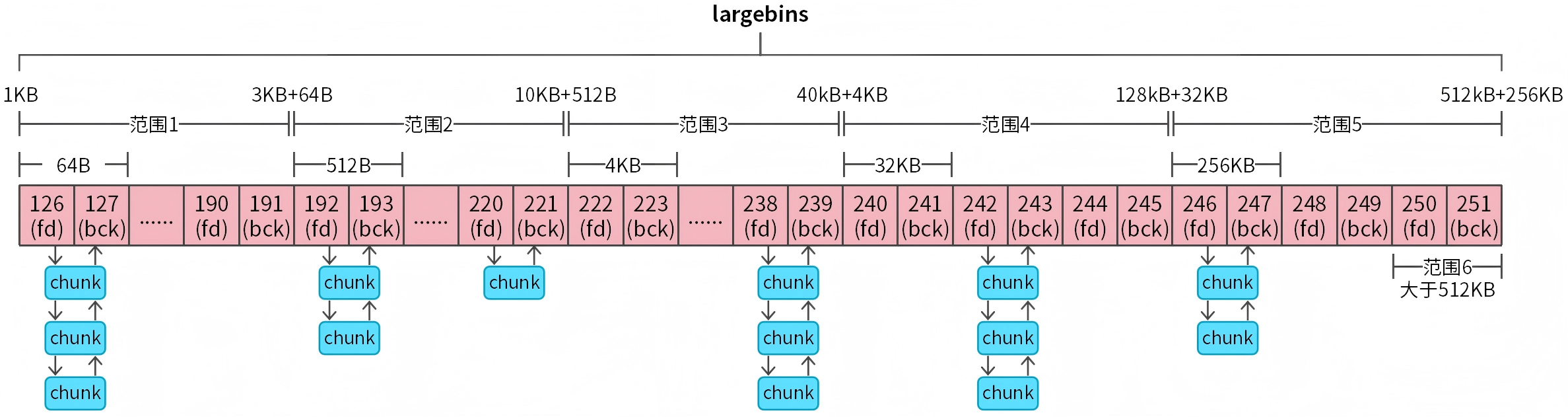
图12 largebins介绍
largebins共63个双向链表(通过fd和bck构成双向循环链表),与smallbins的固定大小管理不同,largebins采用范围管理策略,能够高效处理各种大尺寸内存请求。ptmalloc内存池能够分配的内存大小为128KB,如果这128KB都按照固定大小来管理,那么管理起来会很困难。ptmalloc采取的策略为超过1024字节的chunk采用范围管理策略。
largebins将大于1024字节内存范围分为6个部分,见表1。
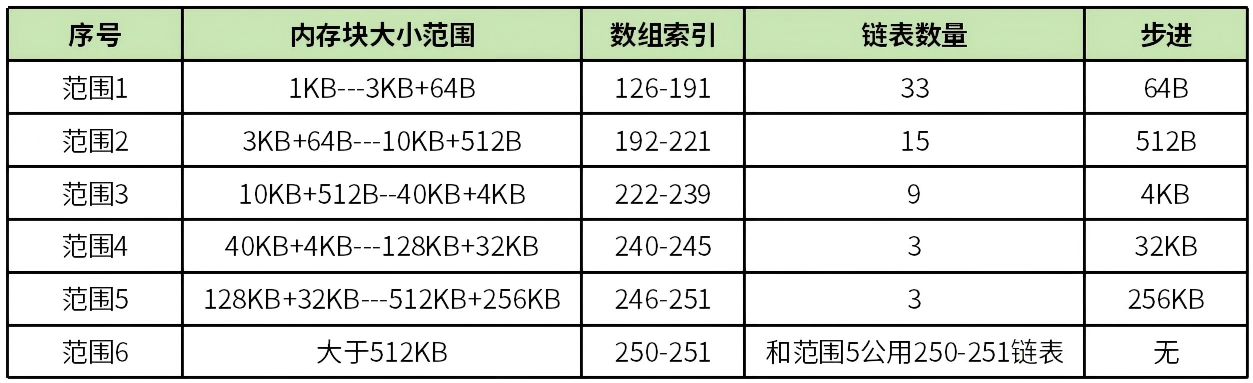
表1 largbins范围
这6个部分并非随意划分,而是通过一定的算法计算而来,相关glibc源码如下:
#define largebin_index_64(sz) \
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)
上述转换算法的逻辑并不简单,建议初学者先按照表1来理解largebins分配内存逻辑,这样可以降低学习成本。
由于largebins是通过范围管理,意味着largebins链表中会有不同大小的chunk,当用户程序从largebins分配内存时,需要从largebins链表中匹配合适大小的chunk。按照传统方法只能轮询链表,即使链表中的有相同大小的chunk,也必须重复轮询。为了快速从largebins链表中找到匹配大小的chunk,largebins增加了快速索引机制(fd_nextsize和bk_nextsize),如图13所示。
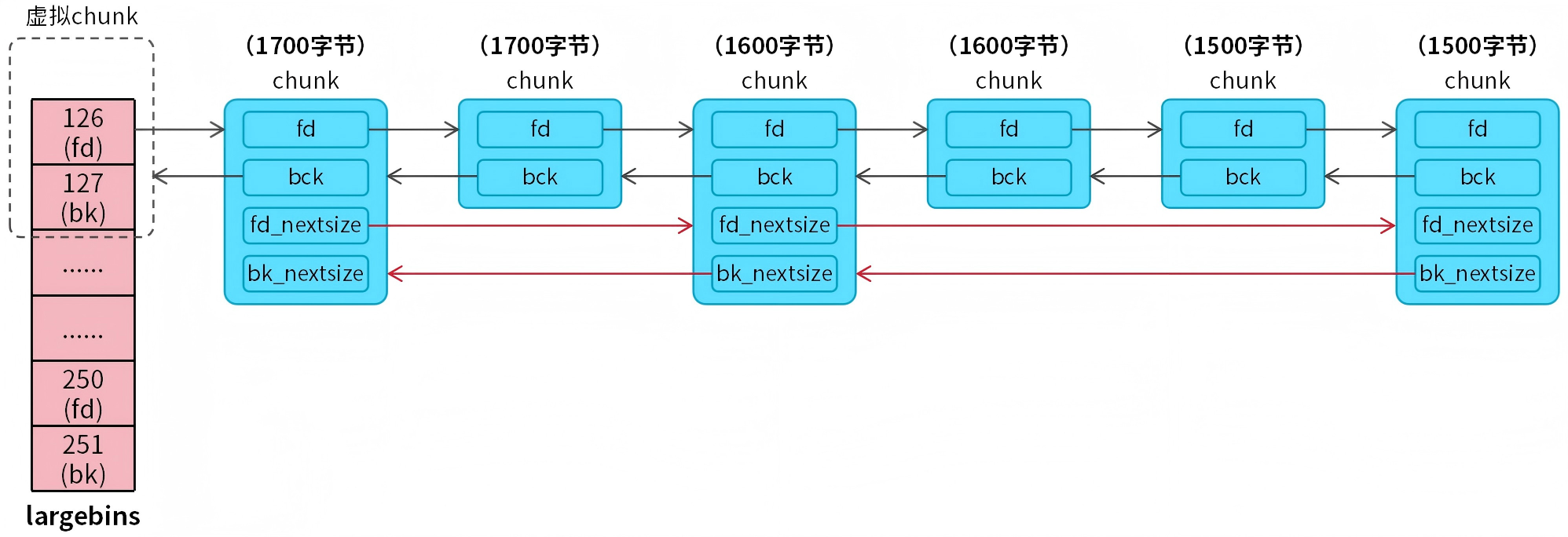
图13 largebins链表快速索引
前面在介绍malloc_chunk结构时,只是简单地介绍了fd_nextsize和bk_nextsize成员。这两个成员只有在largebins中才会生效,它们用于将largebins中不同大小的chunk按从大到小的顺序构成双向循环链表。也就是说largebins中一个bin有两个链表,chunk中的fd_nextsize指向下一个比自身小的chunk,中途如果碰到和自身大小相等的chunk会跳过。chunk中的bk_nextsize指向前一个比自身大的chunk,同样会跳过和自身大小相等的chunk。
当需要从largebins链表分配chunk时,会优先根据fd_nextsize和bk_nextsize查看匹配大小的chunk。这样不用轮询重复大小的chunk,提高了轮询的效率。
4.bin位图
bin位图是一个比较特殊的机制,它的出现用于快速查找bins数组可用的空闲chunk,避免遍历整个bins数组。malloc函数尝试从smallbins和largebins获取空闲chunk时,需要根据申请的chunk大小轮询bins数组,找到可用的bin,轮询的方式是低效的,即使部分bin是空的(没有可用的chunk)也会被轮询到。为了解决这个问题,设计了bin位图。bin位图如图14所示。
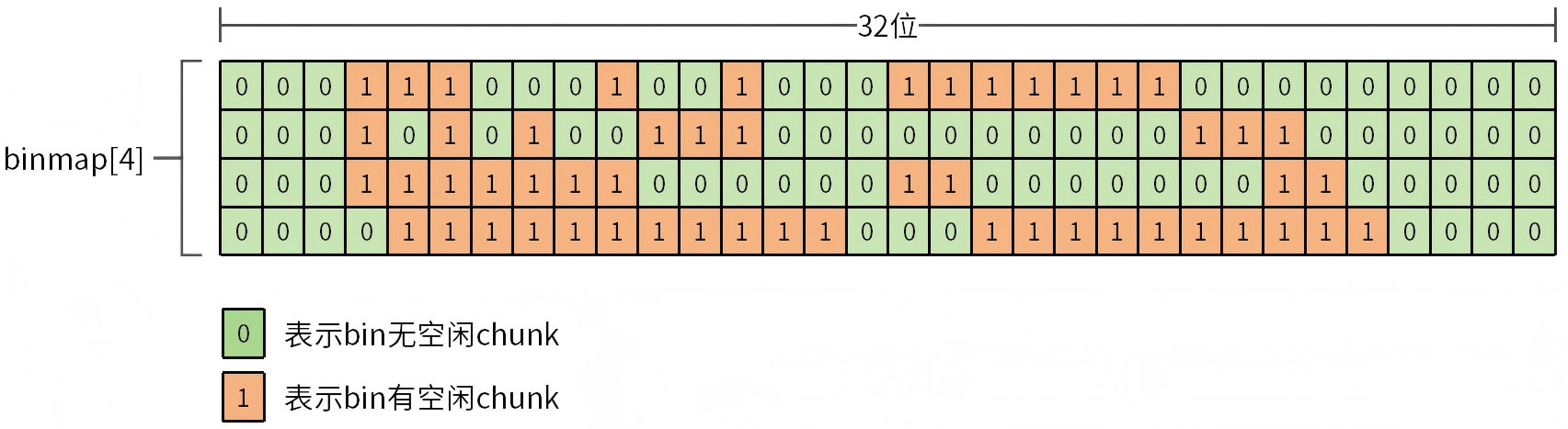
图14 bin位图
malloc_state分配区的binmap数组表示bin位图,数组类型为unsigned int(4字节),数组长度为4。单个数组元素表示32位,bin位图长度为128位。位图中每一位表示bins数组中一个bin是否有空闲chunk(0表示没有空闲chunk,1表示有空闲chunk)。
bin位图和bins数组成映射关系,具体映射过程为:
- 步骤1:根据申请的chunk大小计算出所在bins数组索引值。
- 步骤2:根据bins数组索引值计算出binmap数组索引。
- 步骤3:根据binmap数组索引找到binmap数组元素。
- 步骤4:通过bins数组索引计算出其在binmap中对应的位。
5.malloc源码分析
前面花了大量的篇幅讲解ptmalloc的实现原理,目的是为了降低大家学习malloc和free源码的难度。理论结合实践就能轻松搞懂malloc和free源码。
下面我以代码片段的形式来讲解malloc源码,用户程序调用malloc函数申请内存,首先会调用__libc_malloc函数。
void *__libc_malloc(size_t bytes)
{
mstate ar_ptr;
void *victim;
/* 获取malloc_state分配区 */
arena_get (ar_ptr, bytes);
/* 从分配区分配内存核心代码 */
victim = _int_malloc (ar_ptr, bytes);
......
return victim;
}
__libc_malloc函数首先获取一个可用的malloc_state分配区,接着调用内存分配核心函数_int_malloc分配内存。
static void *_int_malloc (mstate av, size_t bytes)
{
INTERNAL_SIZE_T nb;
/* 用户申请的内存大小转换为chunk大小(16字节对齐) */
nb = checked_request2size (bytes);
/* chunk小于160字节,从fastbins分配内存 */
if(nb <= get_max_fast())
{
/* 通过chunk大小获取fastbin */
idx = fastbin_index (nb);
mfastbinptr *fb = &fastbin (av, idx);
mchunkptr pp;
victim = *fb;
/* 单链表操作,取出待分配的chunk */
REMOVE_FB (fb, pp, victim);
/* 计算chunk可用内存区域起始地址 */
void *p = chunk2mem (victim);
/* 分配内存,返回起始地址*/
return p;
}
/* chunk小于1024字节,从smallbins分配内存 */
if (in_smallbin_range (nb))
{
/* 通过chunk大小获取smallbin */
idx = smallbin_index (nb);
bin = bin_at (av, idx);
/* 分配内存 */
void *p = chunk2mem (victim);
return p;
}
/* 从unsortedbin分配chunk,循环10000次 */
for (;; )
{
victim = unsorted_chunks(av)->bk;
while (victim != unsorted_chunks(av)
{
/* 尝试从last_remainer chunk分配内存 */
if (in_smallbin_range(nb) &&
bck == unsorted_chunks (av) &&
victim == av->last_remainder &&
size > nb + MINSIZE)
{
1.裁剪last_remainer chunk
2.将裁剪后剩余chunk插入unsortedbin
3.分配内存(裁剪后chunk)
return p;
}
1.如果chunk和unsortedbin chunk匹配,直接分配内存
2.否则将chunk转移至smallbins或larginbins
}
}
/* 尝试从largebins分配内存*/
if (!in_smallbin_range (nb))
{
victim = victim->bk_nextsize;
/* 通过bk_nextsize快速索引largebins */
while (size = chunksize (victim)) < nb)
victim = victim->bk_nextsize;
.......
/* 将chunk从largebins链表中移除*/
unlink_chunk (av, victim);
1.裁剪chunk
2.裁剪剩余chunk插入unsortedbin
3.分配内存(裁剪后chunk)
return p;
}
/* 轮询bin位图准备工作,获取位图数组索引、数组元素、位 */
bin = bin_at (av, idx);
block = idx2block (idx);
map = av->binmap[block];
bit = idx2bit (idx);
/* 轮询bin位图 */
for (;; )
{
1.如果位图对应的位置1,获取对应的bin
2.从bin中取出chunk
3.大的chunk需要裁剪,剩余chunk插入unsortedbin
4.分配内存(裁剪后chunk)
return p;
}
use_top:
/* 从top chunk分配chunk */
victim = av->top;
size = chunksize (victim);
/* 如果top chunk满足内存分配要求*/
if (size >= nb + MINSIZE)
{
1.裁剪top chunk
2.更新top指针
3.分配内存(裁剪后chunk)
return p;
}
/* 如果top chunk不满足内存分配要求 */
else
{
/* 通过mmap进行内存分配或者通过sbrk、brk扩容 */
void *p = sysmalloc (nb, av);
/* 分配内存 */
return p;
}
}
malloc分配内存的整个过程都在_int_malloc函数中详细展示,读懂该函数就理解了malloc。
6.free源码分析
用户程序调用free函数释放内存,首先会调用__libc_free函数。
void __libc_free (void *mem)
{
mstate ar_ptr;
mchunkptr p;
/* free(0)直接返回 */
if (mem == 0)
return;
/* 将用户内存区域转换为chunk */
p = mem2chunk (mem);
/* 如果chunk是通过mmap分配,则通过munmap释放*/
if (chunk_is_mmapped (p))
{
munmap_chunk (p);
}
/* 释放chunk至malloc_state分配区 */
else
{
/* 获取malloc_state分配区 */
ar_ptr = arena_for_chunk (p);
/* 释放chunk核心代码 */
_int_free (ar_ptr, p, 0);
}
}
__libc_free函数传入的是可用内存区域地址,首先需要将改地址转换成chunk地址,然后判断chunk是否是通过mmap分配。如果chunk是通过mmap分配则通过munmap释放;否则需要将chunk释放至malloc_state分配区。释放至malloc_state分配区的核心函数是_int_free。
static void _int_free (mstate av, mchunkptr p, int have_lock)
{
INTERNAL_SIZE_T size;
mfastbinptr *fb;
/* 获取chunk大小 */
size = chunksize (p);
/* chunk释放至fastbins */
if (size <= get_max_fast ())
{
1.通过chunk大小找到fastbin
2.将chunk插入fastbin单链表
return;
}
/* 该情况将chunk释放至unsortedbin */
elseif (!chunk_is_mmapped(p)) {
/* 释放chunk至unsortedbin,
注意:释放过程中需要执行向前合并和向后合并操作!!! */
_int_free_merge_chunk (av, p, size);
}
/* chunk通过mmap分配 */
else {
/* 通过munmap释放 */
munmap_chunk (p);
}
}
总结:
malloc和free是工作和面试中经常会碰到的问题,了解了malloc和free的底层原理,对我们会有很大的帮助。


















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











