






字符串定义
字符串是 Python中最常用的数据类型。字符串的意思就是"一串字符",比如"Hello,Charlie"是一个字符串,"How are you?"也是一个字符串。
Python要求字符串必须使用引号括起来,使用单引号也行,使用双引号也行,当然三引号(一对连续的单引号或者双引号 :"""字符串""" , '''字符串''')也可以,只要两边的引号能配对即可。Python中三引号可以将复杂的字符串进行赋值。Python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
python字符串是不可变数据类型,有序数据类型。
字符串的两种定义方式
1、通过内置函数str()函数将其他数据类型转化为字符串
>>> a = str(1.345)
>>> a
'1.345'
# 查看类型
>>> type(a)
str
2、直接加引号定义
>>> s = '人生苦短, 我用Python'
>>> s
'人生苦短, 我用Python'
字符串的运算
字符串运算与整数(int)或浮点数(float)有所区别,不是逻辑运算,而是首位拼接、重复字符串以及判断一个字符串是否包含某个字符或字符串。
+ 加号运算
将两个字符串首位拼接,产生一个新的字符串,原字符串对象值保持不变。
>>> a = 'pyt'
>>> b = 'hon'
>>> a+b # 重新定一个对象,原对象值不变
'python'
>>> b
'hon'* 乘号运算
一个字符串与一个整数相成,表示将原来字符串重复整数次。
>>> a = '1'
>>> a*8
'11111111'
# 整体输出
>>> b = 'Python'
>>> b*3
'PythonPythonPython'in 包含运算
in 表示a是否在b里,结果为 是-True 或 否-False。相对应的,not in,表示a是否不在b里。
>>> a = 'o'
>>> b = 'Python'
>>> a in b #判断a是否在b里面
True
# 整体判断
>>> '12' in 'Python'
False
字符串的索引和切片
字符串也是一个可迭代对象, 也就是说每一个字符串实际上都有一个对应的索引值。字符串的切片,就是从原字符串中提取一部分出来,可以是连续的,也可以是离散的。
那么字符串依靠的是什么来取得呢?那就是索引。
| 元素1 | 元素2 | 元素3 | ... | 元素n-1 | 元素n | |
|---|---|---|---|---|---|---|
| 索引 | 0 | 1 | 2 | ... | n-2 | n-1 |
| 索引 | -n | -(n-1) | -(n-2) | ... | -2 | -1 |
索引
字符串切片的标准语法:
str [开始位置: 终止位置: 步长和方向]
- 开始位置:即开始取的位置,这个位置的元素是能取到的。
- 终止位置:即停止的位置,注意该位置的值取不到。
- 第三个参数:不写默认是1,正数表示从左往右取,负数表示从右往左取,绝对值表示步长。
>>> s = "人生苦短,我用python"
>>> s
'人生苦短,我用python'
>>> len(s) # len()函数可以用来查看字符串的长度
13
>> s[0] # 取出人
'人'
>>> s[4]
','
>>> s[-1]
'n'切片
str [开始位置:终止位置:步长和方向]
终止位置取不到第三个参数:不写默认是1,正数表示从左往右取,负数表示从右往左取,绝对值表示步长。
>>> s = '人生苦短,我用python'
>>> s[0:4:1]
'人生苦短'
>>> s[2:-4:1]
'苦短,我用py'
>>> s[7::1]
'python'
>>> s[3::-1]
'短苦生人'
三个检索的方法
检索方法即通过一定的函数,寻找一串字符串内所包含某个字符或字符串的计数、位置等。
| 方法 | 语法 | 参数 | 备注 |
|---|---|---|---|
| 计数 | str.count(sub[, start[, end]]) -> int | (要计数的对象,开始位置,终止位置) | |
| 查找 | str.find(sub[, start[, end]]) -> int | (要查找的对象,开始位置,终止位置) | 找不到返回-1 |
| 索引 | str.index(sub[, start[, end]])-> int | (要查找的对象,开始位置,终止位置) | 找不到则报错 |
count()
字符串.count(要计数的对象, 开始索引值,结束索引值), 返回寻找的对象,在字符串里面出现的次数。
要计算某个对象在一串字符串中出现的次数,可选用count()。如计算"数据"在"关注公众号《数据STUDIO》,和我一起学习数据分析"中出现的次数。
>>> a = '关注公众号《数据STUDIO》,和我一起学习数据分析'
>>> a.count("数据") # 把数据当做一个整体进行计数
2
>>> a.count('数据',0,10) #在[0:10)这个片段上对‘数据’进行计数
1find()
字符串.find(要查找的对象,开始位置,结束位置),如果对象包含在字符串内,则返回开始的索引值,否则返回-1
rfind()返回的是最后一次出现的位置。
注意:与count()不同,find()返回的是索引值,即找出"数"在"关注公众号《数据STUDIO》,和我一起学习数据分析"中的位置。
>>> a = '关注公众号《数据STUDIO》,和我一起学习数据分析'
>>> a.find('数') #默认是第一次出现的索引位置
6
>>> a.rfind('数') #rfind()最后一次出现的索引位置
22
>>> a.find('数', 0, 3) # 相当于在[0:3)这个片段内查找,找得到就返回在原来字符串中的索引,找不到返回-1
-1
>>> a.find('关注') #如果存在则返回第一个字符的索引,即‘一’的索引
0index()
index()方法同find()方法基本一样,也是用于检索字符串类是否包含特定的对象,返回的也是索引值只不过如果要检索的对象如果不存在于字符串内,不会像find()一样返回-1,而是直接报错 rindex()是最后一次出现的位置
>>> a = '关注公众号《数据STUDIO》,和我一起学习数据分析'
>>> a.index('数') # 默认返回第一次出现的位置
6
>>> a.rindex("数") # 返回最后一次出现的索引值
22
>>> a.index("帅") # 找不到就报错
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
-7-19b366464b93> in
----> 1 a.index('帅')
ValueError: substring not found三个分割的方法
分割字符串,即将一长串字符串,按照一定的规则,如通过特殊字符、指定的字符或字符串,全部分割或指定分割次数分割,以列表的形式存储输出,可通过切片索引的方式取出。
| 方法 | 语法 | 参数 |
|---|---|---|
| 分割 | str.split(sep=None, maxsplit=-1) | 默认以\t \n \r 空格 等特色符合分割,默认分割次数为全部分割 |
| 分割 | str.splitlines(keepends=False) | 注意没有分割符,就是以\t \n \r 空格 等分割符分割 |
| 分割 | str.partition(sep, /) | 把str以分割符为标准,分割成三部分,str前 str str后,返回的是元组 |
split()
字符串.split("分割符", 分割次数)
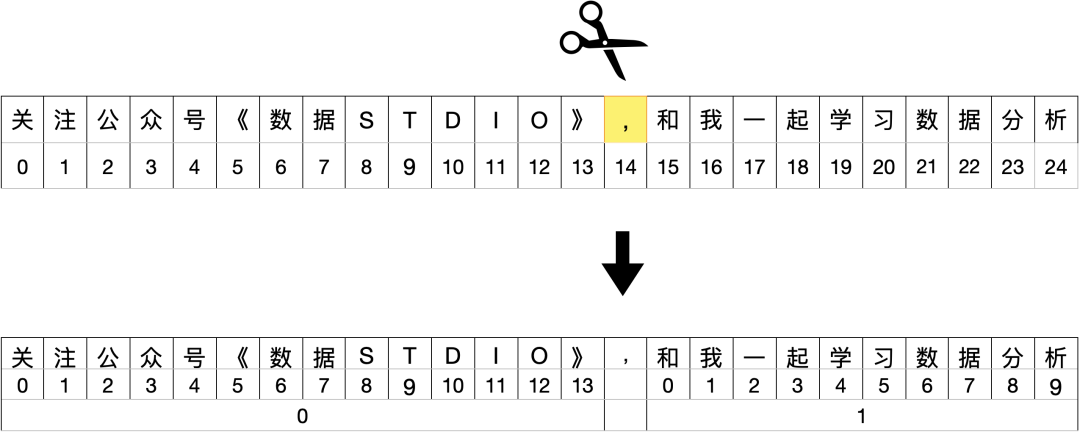
如图所示,split()按照默认分割符,分割字符串,得到,两边的分片字符串,并以列表的形式存储。
当然也可指定分割符分割字符串。
>>> s = '关注公众号《数据STUDIO》,和我一起学习数据分析'
>>> s.split()
['关注公众号《数据STUDIO》,和我一起学习数据分析']
>>> s = '《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
>>> s.split('关注')
['《数据STUDIO》', '《数据STUDIO》', '《数据STUDIO》']rsplit()
字符串.rsplit("分割符", 分割次数)
如果想从右边开始分隔(还是加个“r”)
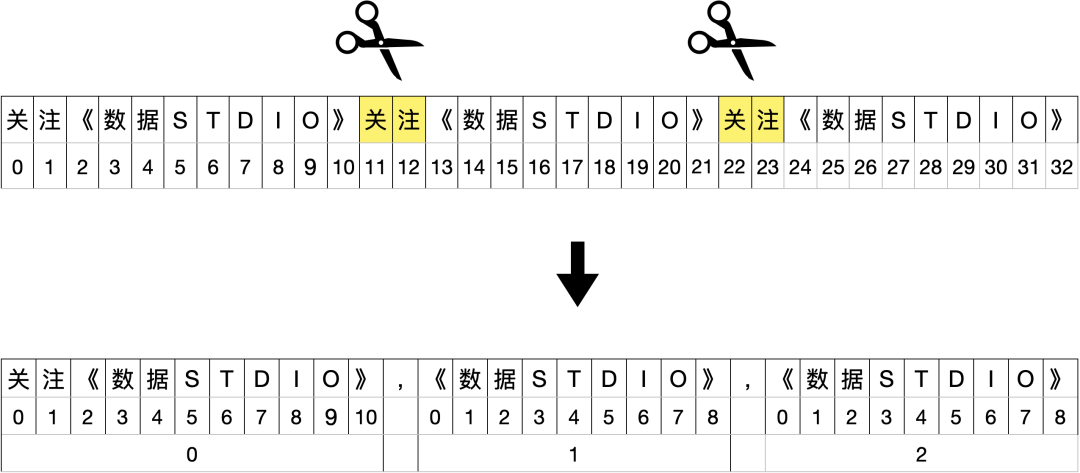
可以传入参数去限制分割几次。
>>> s = '关注《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
>>> s.rsplit('关注', 2) #可以传入参数去限制分割几次
['关注《数据STUDIO》', '《数据STUDIO》', '《数据STUDIO》']splitlines()
字符串.splitlines(True或False)
按照行分割,返回一个包含各行作为元素的列表。
字符串.splitlines()按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表。如果参数 keepends=False,不包含换行符,如果为 keepends=True,则保留换行符。
如有这么很长一句话,其中包含各种特殊符号,splitlines()将按照特殊字符按行分割。
>>> s="关于你\r我有太多东西关于你\r\n清醒的时候放不下矜持\n不敢说我喜欢你\n只有在某个夜晚多愁善感又萦绕在心头\n或是朋友聚会上的大醉\n才敢借着情绪说\n我喜欢你\n喜欢了好久好久"
>>> s.splitlines() #括号里面默认填False,效果一样,不显示换行符。按行分割
['关于你',
'我有太多东西关于你',
'清醒的时候放不下矜持',
'不敢说我喜欢你',
'只有在某个夜晚多愁善感又萦绕在心头',
'或是朋友聚会上的大醉',
'才敢借着情绪说',
'我喜欢你',
'喜欢了好久好久']
>>> s.splitlines(keepends=True) # 保留分隔符
['关于你\r',
'我有太多东西关于你\r\n',
'清醒的时候放不下矜持\n',
'不敢说我喜欢你\n',
'只有在某个夜晚多愁善感又萦绕在心头\n',
'或是朋友聚会上的大醉\n',
'才敢借着情绪说\n',
'我喜欢你\n',
'喜欢了好久好久']partition()
字符串.partition(分隔符)
默认是第一个分割,分成三部分,返回的是元组。分隔符左边一部分,分隔符右边一部分,分隔符本身。
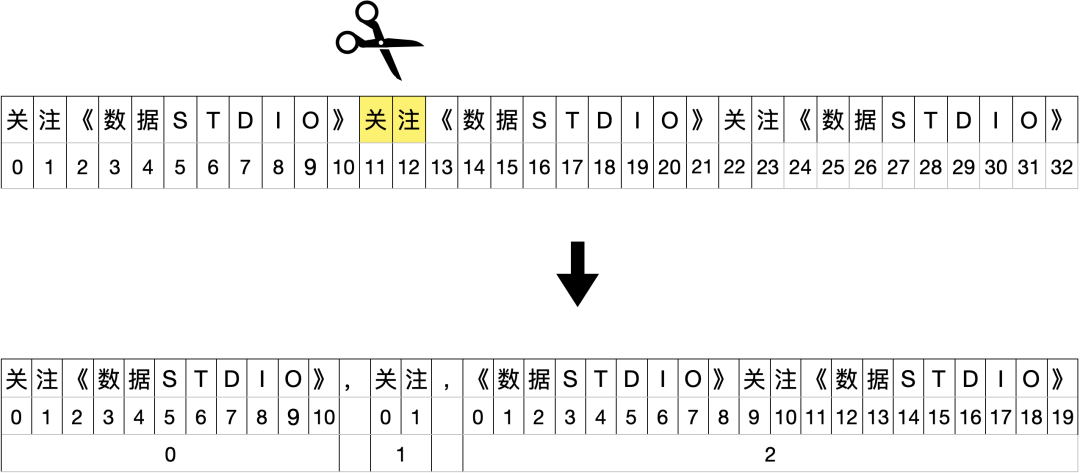
>>> s = '《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
>>> s.partition('关注')
('《数据STUDIO》', '关注', '《数据STUDIO》关注《数据STUDIO》')
>>> s.rpartition('关注') # 如果想从右边开始分割(还是加个“r”)
('《数据STUDIO》关注《数据STUDIO》', '关注', '《数据STUDIO》')
一个合并的方法
字符串.join(包含字符串的序列)
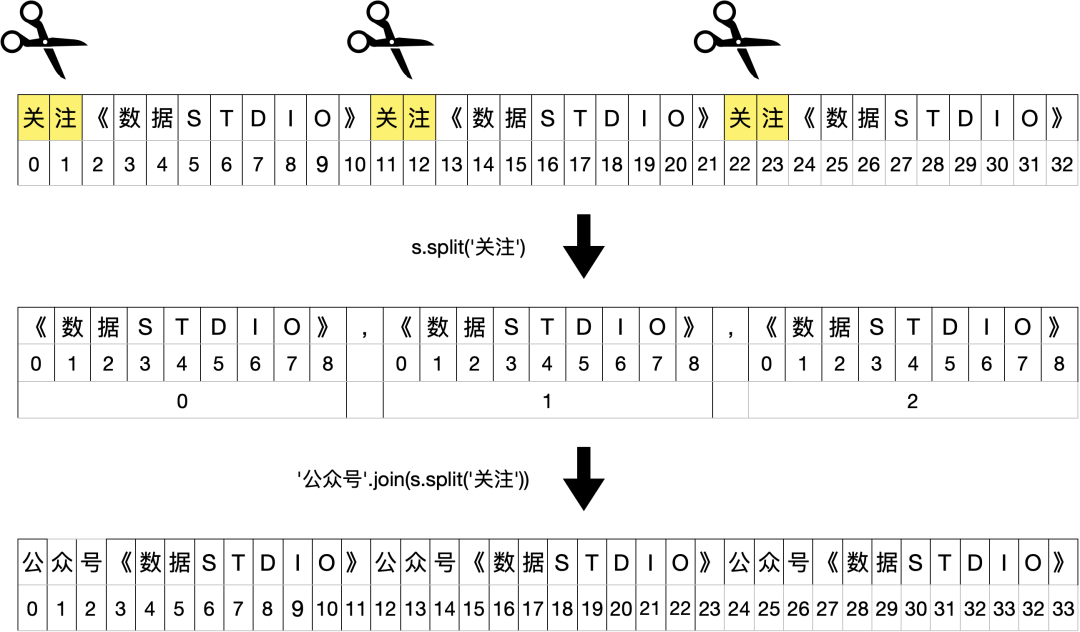
join方法是通过扮演'桥梁'角色的连接字符串将片段字符串连接起来。
>>> s = '关注《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
>>> '公众号'.join(s.split('关注'))
'公众号《数据STUDIO》公众号《数据STUDIO》公众号《数据STUDIO》'
其中包含字符串的序列必须是可迭代对象。
>>> '-->'.join(1234)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
-4-258db90e324a> in
----> 1 '-->'.join(1234)
TypeError: can only join an iterable调整字符串中单词的顺序。
>>> s = 'Life is short I use python'
>>> a = s.split()
>>> b = a[-1::-1]
>>> c = ' '.join(b)
>>> c
'python use I short is Life'
一个替换的方法
| 方法 | 语法 | 参数 | 返回值 |
|---|---|---|---|
| 替换 | str.replace(old, new, count=-1, /) | 被替换的字符, 用来替换的字符, 替换次数 | 新的字符串对象 |
字符串.replace(被替换的字符, 用来替换的字符, 替换次数)
字符串是不可变数据类型,返回新的字符串对象,原来的字符串都是没有发生变化
- 如果想要去除字符串里面某个字符,可以用
replace()方法。 - 用来替换的字符参数为空字符即可。
例
>>> s = '关注《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
>>> s.replace('关注', '公众号') #默认全部替换
'公众号《数据STUDIO》公众号《数据STUDIO》公众号《数据STUDIO》'
>>> s.replace('关注', '公众号', 2) # 指定替换次数(替换2次)
'公众号《数据STUDIO》公众号《数据STUDIO》关注《数据STUDIO》'
>>> s.replace('关注','') # 用空字符串来替换,可以利用这种方法删除字符串里的某些字符
'《数据STUDIO》《数据STUDIO》《数据STUDIO》'
一个中心化的方法
| 方法 | 语法 | 参数 | 返回 |
|---|---|---|---|
| 中心化 | str.center(width, fillchar=' ', /) | 宽度, 填充的字符串 | 返回长度和宽度居中的字符串 |
center()
字符串.center(字符串总宽度, 填充的字符串)
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格。
>>> a = '数据STUDIO'
>>> a.center(20, '*')
'******数据STUDIO******'
两个字符大小写转换方法
lower()
转换 str 中所有大写字符为小写,返回转换为小写的字符串的副本。
>>> s = '关注《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
>>> s.lower()
'关注《数据studio》关注《数据studio》关注《数据studio》'
>>> s
'关注《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
upper()
转换 str 中的小写字母为大写
>>> s = '关注《数据studio》关注《数据studio》关注《数据studio》'
>>> s.upper()
'关注《数据STUDIO》关注《数据STUDIO》关注《数据STUDIO》'
三个去除两端特殊字符的方法
| 方法 | 语法 | 参数 | 返回 |
|---|---|---|---|
| 去除两边 | str.strip(chars=None, /) | 传入指定去除什么,默认空白字符以及特殊字符包括制表符\t、回车符\r、换行符\n | 返回删除两端空格的字符串副本。 |
| 去除右边 | str.rstrip(chars=None, /) | 传入指定去除什么,默认空白字符以及特殊字符包括制表符\t、回车符\r、换行符\n | 返回删除尾部空格的字符串副本。 |
| 去除左边 | str.lstrip(chars=None, /) | 传入指定去除什么,默认空白字符以及特殊字符包括制表符\t、回车符\r、换行符\n | 返回删除首部空格的字符串副本。 |
去除两边—— 字符串.strip(需要去除的字符)

两端字符包括特殊字符以及指定的字符串。
>>> s = ' 关注《数据studio》\r\n '
>>> s.strip() # 默认去除空格
'关注《数据studio》'
>>> s = '关注《数据STUDIO》关注《数据STUDIO》关注'
>>> s.strip('关注')
'《数据STUDIO》关注《数据STUDIO》'去除单边
字符串.rstrip()——只去除右边的空格和特殊字符
字符串.lstrip()——只去除左边的空格和特殊字符
>>> s = '关注《数据STUDIO》关注《数据STUDIO》关注'
>>> s.rstrip('关注')
'关注《数据STUDIO》关注《数据STUDIO》'
>>> s.lstrip('关注')
'《数据STUDIO》关注《数据STUDIO》关注'
一种字符串的格式化输出方法
字符串.format()
str.fromat()的普通形式
>>> print('{}{}《数据STUDIO》'.format('关注', '公众号')) #{}什么都不填写就依次传入
'关注公众号《数据STUDIO》'
>>> >>> print('{1}{2}《数据STUDIO》'.format('关注', '公众号')) #在{}里面填入索引值
'公众号关注《数据STUDIO》'
str.format( ) 接受参数形式
>>> '{公众号}的作者是{name}'.format(公众号='《数据STUDIO》',name='Jim') # 参数位置可以不按顺序显示。
'《数据STUDIO》的作者是Jim'
python 字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %F 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
Python转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
字符串的方法总览
| 方法 | 描述 |
|---|---|
| title() | 每个单词首字母大写 |
| lower()/upper() | 全部小写/大写 |
| capitalize() | 首字母大写,其余小写 |
| swapcase() | 反转大小写 |
| join(seq) | 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串,相对于运算符而言,性能更佳 |
| rstrip() | 删除字符串字符串末尾的空格. |
| istrip() | 删除字符串开头的空格 |
| strip([chars]) | 在字符串上执行 lstrip()和 rstrip() |
| ljust(width[, fillchar]) | 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| rjust(width,[, fillchar]) | 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| zfill (width) | 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| bytes.decode(encoding="utf-8", errors="strict") | Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| len(string) | 返回字符串长度 |
| center(width, fillchar) | 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| count(str, beg= 0,end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| find(str, beg=0 end=len(string)) | 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在字符串中会报一个异常. |
| rfind(str, beg=0,end=len(string)) | 类似于 find()函数,不过是从右边开始查找. |
| startswith(str, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| endswith(suffix, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| lstrip() | 截掉字符串左边的空格或指定字符。 |
| isalnum() | 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| isalpha() | 如果字符串至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
| isdigit() | 如果字符串只包含数字则返回 True 否则返回 False.. |
| islower() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| isspace() | 如果字符串中只包含空白,则返回 True,否则返回 False. |
| istitle() | 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| isupper() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| isdecimal() | 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
| rindex( str, beg=0, end=len(string)) | 类似于 index(),不过是从右边开始. |
| index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在字符串中会报一个异常 |
| split(str="", num=string.count(str)) | num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num 个子字符串 |
| replace(old, new [, max]) | 将字符串中的 str1 替换成 str2,如果 max 指定,则替换不超过 max 次。 |
| splitlines([keepends]) | 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| translate(table, deletechars="") | 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| maketrans() | 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
推荐阅读

















 2164
2164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









