






对于窗口函数,比如row_number(),rank(),dense_rank(),NTILE(),PERCENT_RANK()等等,现在MySQL8.0+版本已经支持了!
这是一个原始数据表,数据用于测试
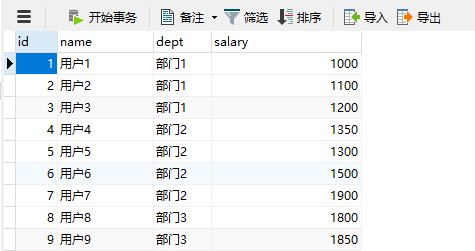
第一部分:开窗函数和排名类函数结合
1.使用SQL查看工资排名(注意,这个功能如果没有开窗函数还是比较难写的哦,有兴趣可以试一下, 但是现在却如此简单! )
SELECT
`name`,
`dept`,
`salary`,
row_number () over (PARTITION BY `dept` ORDER BY salary DESC ) AS salary_rank
FROM
t_user
得到结果:
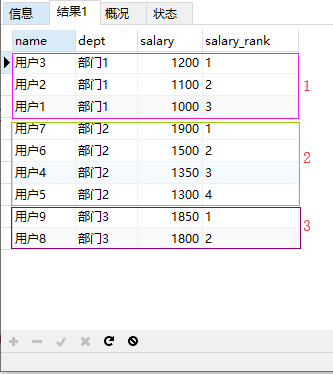
2.使用开窗函数计算每个部门工资最高的前3个人 (这个功能如果没有开窗函数会很复杂)
SELECT
*
FROM
(
SELECT
`name`,
`dept`,
`salary`,
row_number () over (PARTITION BY `dept` ORDER BY salary DESC) AS salary_rank
FROM
t_user
) AS tmp
WHERE
tmp.salary_rank <= 3
得到结果:
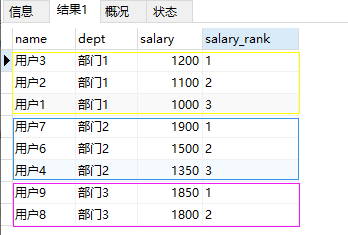
和上面 row_number()非常类似的一个开窗函数还有rank()
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
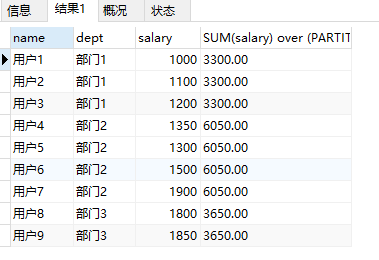
第二部分:开窗函数和SUM()等聚合函数结合
SELECT
`name`,
`dept`,
`salary`,
SUM(salary) over (PARTITION BY `dept`)
FROM
t_user
结果可以看到,这个语句效果和SUM()配合Group BY 使用效果是一样的,只是结果集格式不同而已:
但是,在上面的语句中加上ORDER BY之后,结果就完全不同了! 需要特别注意
SELECT
`name`,
`dept`,
`salary`,
SUM(salary) over (PARTITION BY `dept` ORDER BY salary ASC)
FROM
t_user
结果:
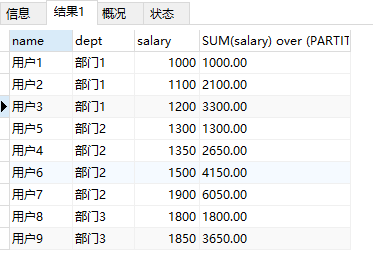
总结规律: 有order by;按照排序连续累加;无order by,计算partition by后的和;over()中没有partition by,计算所有数据总和
同时,order by 的ASC和DESC也会导致结果不同!
第三部分 分析函数(lag、lead)
lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率。
lead() over([partition by prov_name [ORDER BY val_cnt]])
lag、lead有三个参数,第一个是表达式或字段,第二个是偏移量,第三个是为控制默认赋值
例如:lead(field, num, defaultvalue) field需要查找的字段,num往后查找的num行的数据,defaultvalue没有符合条件的默认值。
SELECT
`name`,
`dept`,
`salary`,
lag (salary, 1) over (PARTITION BY `dept` ORDER BY salary DESC)
FROM
t_user
得出以下结果
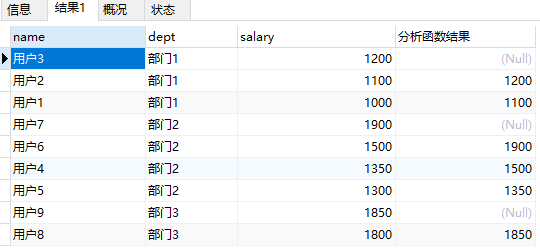
分析函数执行后结果,可以看出来,lag函数就是把同个partition组内的order by排名上一条放到自己后面作为一个新列,
这个效果在需要错位相减,做逐差计算增长率之类的时候简直就是神器!
lead()函数和lag函数左右相反,偏移的方向不同而已
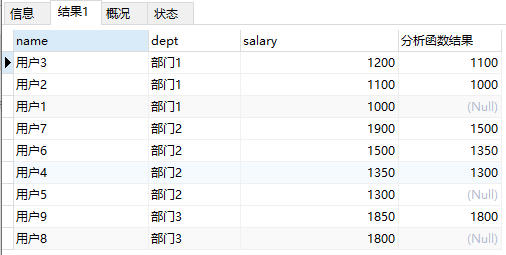
SELECT
`name`,
`dept`,
`salary`,
lead (salary, 1) over (PARTITION BY `dept` ORDER BY salary DESC) '分析函数结果'
FROM
t_user
结果:
文章来源: www.oschina.net,作者:沧海一刀,版权归原作者所有,如需转载,请联系作者。
原文链接:https://my.oschina.net/u/2338224/blog/3112042















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









