






前言
问题提出
源表t_source结构如下:
item_id int,
created_time datetime,
modified_time datetime,
item_name varchar(20),
other varchar(20)
要求:
1.源表中有100万条数据,其中有50万created_time和item_name重复。
2.要把去重后的50万数据写入到目标表。
3.重复created_time和item_name的多条数据,可以保留任意一条,不做规则限制。
实验环境
Linux虚机:CentOS release 6.4;8G物理内存(MySQL配置4G);100G机械硬盘;双物理CPU双核,共四个处理器;MySQL 8.0.16。
建立测试表和数据
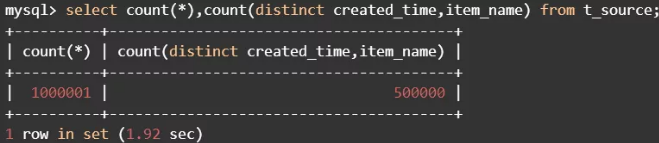
源表中有1000001条记录,去重后的目标表应该有500000条记录。
巧用索引与变量
1.无索引对比测试
(1)使用相关子查询

这个语句很长时间都出不来结果,只看一下执行计划吧。
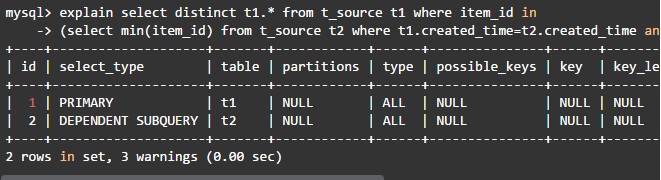
主查询和相关子查询都是全表扫描,一共要扫描100万*100万数据行,难怪出不来结果。
(2)使用表连接

这种方法用时14秒,查询计划如下:
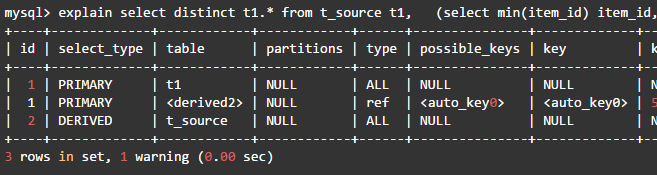
·内层查询扫描t_source表的100万行,建立临时表,找出去重后的最小item_id,生成导出表derived2,此导出表有50万行。
·MySQL会在导出表derived2上自动创建一个item_id字段的索引auto_key0。
·外层查询也要扫描t_source表的100万行数据,在与导出表做链接时,对t_source表每行的item_id,使用auto_key0索引查找导出表中匹配的行,并在此时优化distinct操作,在找到第一个匹配的行后即停止查找同样值的动作。
(3)使用变量
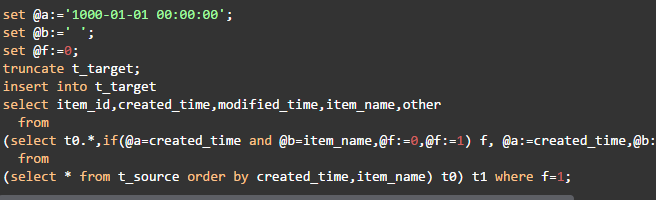
这种方法用时13秒,查询计划如下:
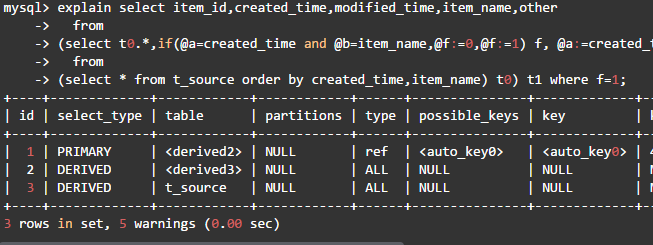
·最内层的查询扫描t_source表的100万行,并使用文件排序,生成导出表derived3。
·第二层查询要扫描derived3的100万行,生成导出表derived2,完成变量的比较和赋值,并自动创建一个导出列f上的索引auto_key0。
·最外层使用auto_key0索引扫描derived2得到去重的结果行。
与上面方法2比较,总的扫描行数不变,都是200万行。只存在一点微小的差别,这次自动生成的索引是在常量列 f 上,而表关联自动生成的索引是在item_id列上,所以查询时间几乎相同。至此,我们还没有在源表上创建任何索引。无论使用哪种写法,要查重都需要对created_time和item_name字段进行排序,因此很自然地想到,如果在这两个字段上建立联合索引,利用索引本身有序的特性消除额外排序,从而提高查询性能。
2.建立created_time和item_name上的联合索引对比测试

(1)使用相关子查询

本次用时19秒,查询计划如下:
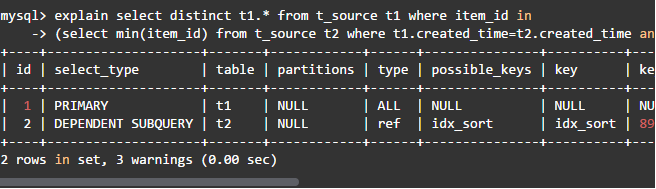
·外层查询的t_source表是驱动表,需要扫描100万行。
·对于驱动表每行的item_id,通过idx_sort索引查询出两行数据。
(2)使用表连接

本次用时13秒,查询计划如下:
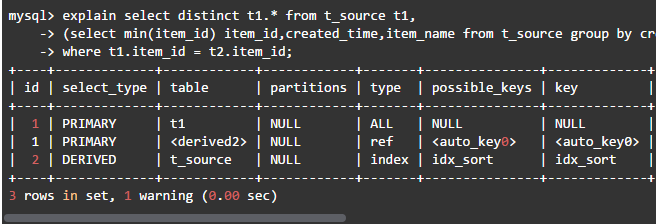
和没有索引相比,子查询虽然从全表扫描变为了全索引扫描,但还是需要扫描100万行记录。因此查询性能提升并不是明显。
(3)使用变量
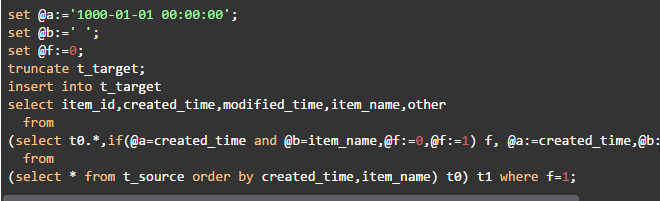
本次用时13秒,查询计划与没有索引时的完全相同。可见索引对这种写法没有作用。能不能消除嵌套,只用一层查询出结果呢?
(4)使用变量,并且消除嵌套查询
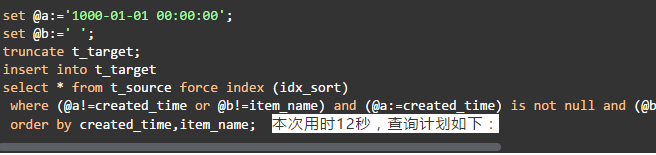
本次用时12秒,查询计划如下:
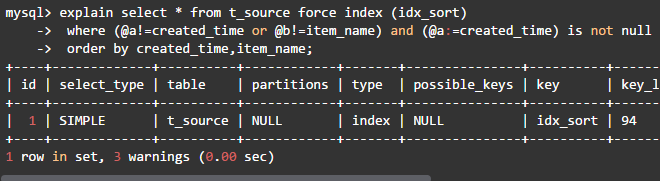
该语句具有以下特点:
·消除了嵌套子查询,只需要对t_source表进行一次全索引扫描,查询计划已达最优。
·无需distinct二次查重。
·变量判断与赋值只出现在where子句中。
·利用索引消除了filesort。
在MySQL 8之前,该语句是单线程去重的最佳解决方案。仔细分析这条语句,发现它巧妙地利用了SQL语句的逻辑查询处理步骤和索引特性。一条SQL查询的逻辑步骤为:
1.执行笛卡尔乘积(交叉连接)
2.应用ON筛选器(连接条件)
3.添加外部行(outer join)
4.应用where筛选器
5.分组
6.应用cube或rollup
7.应用having筛选器
8.处理select列表
9.应用distinct子句
10.应用order by子句
11.应用limit子句
每条查询语句的逻辑执行步骤都是这11步的子集。拿这条查询语句来说,其执行顺序为:强制通过索引idx_sort查找数据行 -> 应用where筛选器 -> 处理select列表 -> 应用order by子句。为了使变量能够按照created_time和item_name的排序顺序进行赋值和比较,必须按照索引顺序查找数据行。这里的force index (idx_sort)提示就起到了这个作用,必须这样写才能使整条查重语句成立。否则,因为先扫描表才处理排序,因此不能保证变量赋值的顺序,也就不能确保查询结果的正确性。order by子句同样不可忽略,否则即使有force index提示,MySQL也会使用全表扫描而不是全索引扫描,从而使结果错误。索引同时保证了created_time,item_name的顺序,避免了文件排序。force index (idx_sort)提示和order by子句缺一不可,索引idx_sort在这里可谓恰到好处、一举两得。查询语句开始前,先给变量初始化为数据中不可能出现的值,然后进入where子句从左向右判断。先比较变量和字段的值,再将本行created_time和item_name的值赋给变量,按created_time、item_name的顺序逐行处理。item_name是字符串类型,(@b:=item_name)不是有效的布尔表达式,因此要写成(@b:=item_name) is not null。最后补充一句,这里忽略了“insert into t_target select * from t_source group by created_time,item_name;”的写法,因为它受“sql_mode='ONLY_FULL_GROUP_BY'”的限制。
利用窗口函数
MySQL 8中新增的窗口函数使得原来麻烦的去重操作变得很简单。
 这个语句执行只需要12秒,而且写法清晰易懂,其查询计划如下:
这个语句执行只需要12秒,而且写法清晰易懂,其查询计划如下:
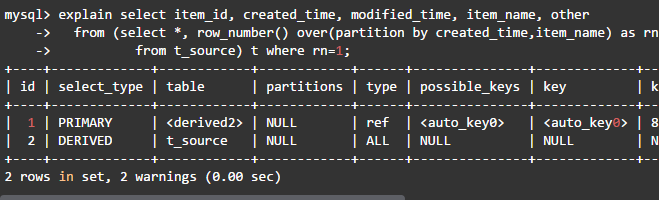
该查询对t_source表进行了一次全表扫描,同时用filesort对表按分区字段created_time、item_name进行了排序。外层查询从每个分区中保留一条数据。因为重复created_time和item_name的多条数据中可以保留任意一条,所以oevr中不需要使用order by子句。从执行计划看,窗口函数去重语句似乎没有消除嵌套查询的变量去重好,但此方法实际执行是最快的。MySQL窗口函数说明参见“https://dev.mysql.com/doc/refman/8.0/en/window-functions.html”。
多线程并行执行
前面已经将单条查重语句调整到最优,但还是以单线程方式执行。能否利用多处理器,让去重操作多线程并行执行,从而进一步提高速度呢?比如我的实验环境是4处理器,如果使用4个线程同时执行查重SQL,理论上应该接近4倍的性能提升。1.数据分片
在生成测试数据时,created_time采用每条记录加一秒的方式,也就是最大和在最小的时间差为50万秒,而且数据均匀分布,因此先把数据平均分成4份。
(1)查询出4份数据的created_time边界值
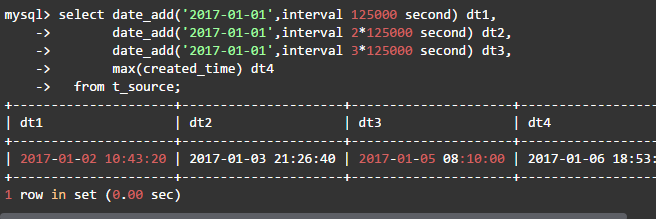
(2)查看每份数据的记录数,确认数据平均分布
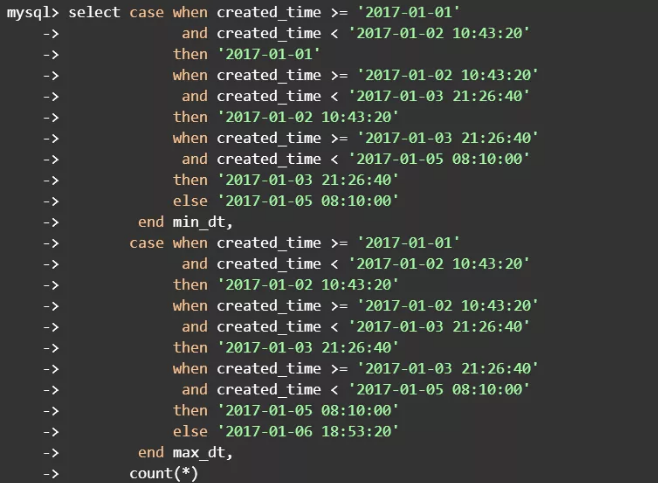
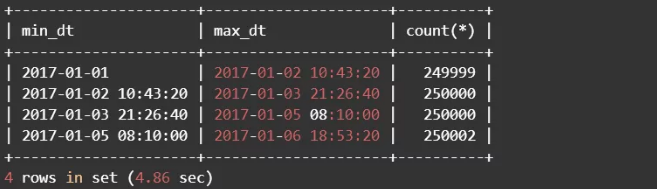
4份数据的并集应该覆盖整个源数据集,并且数据之间是不重复的。也就是说4份数据的created_time要连续且互斥,连续保证处理全部数据,互斥确保了不需要二次查重。实际上这和时间范围分区的概念类似,或许用分区表更好些,只是这里省略了重建表的步骤。
2.建立查重的存储过程
有了以上信息我们就可以写出4条语句处理全部数据。为了调用接口尽量简单,建立下面的存储过程。
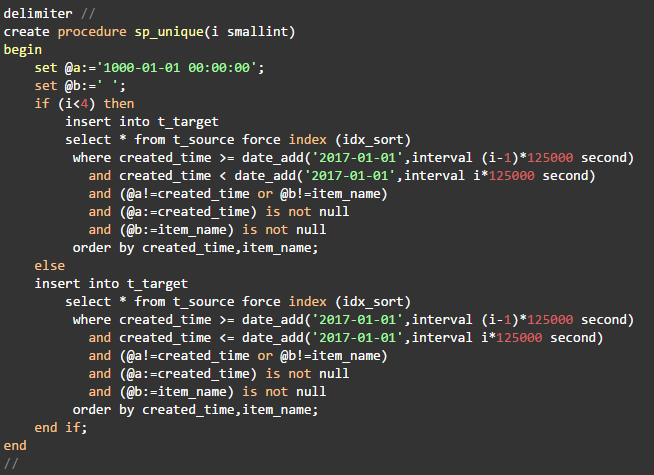
查询语句的执行计划如下:
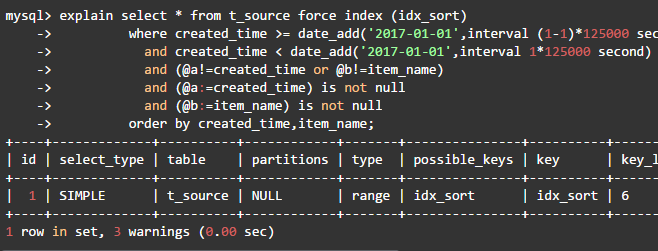
MySQL优化器进行索引范围扫描,并且使用索引条件下推(ICP)优化查询。
3.并行执行
下面分别使用shell后台进程和MySQL Schedule Event实现并行。
(1)shell后台进程
建立duplicate_removal.sh文件,内容如下:
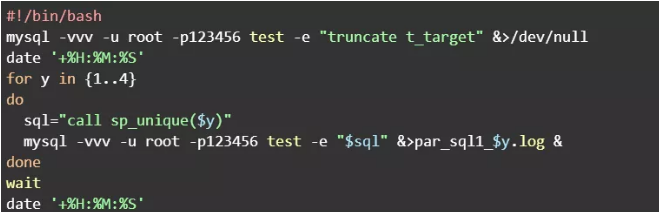
执行脚本文件

执行输出如下:

这种方法用时5秒,并行执行的4个过程调用分别用时为4.87秒、4.88秒、4.91秒、4.73秒:
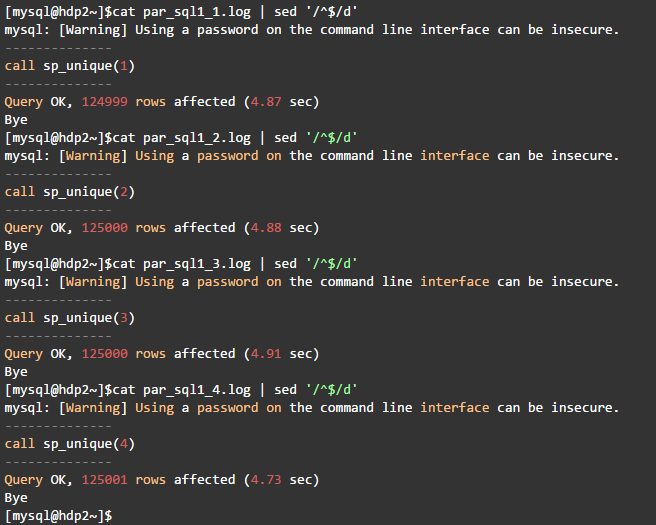
可以看到,每个过程的执行时间均4.85,因为是并行执行,总的过程执行时间为最慢的4.91秒,比单线程速度提高了2.5倍。
(2)MySQL Schedule Event
·建立事件历史日志表
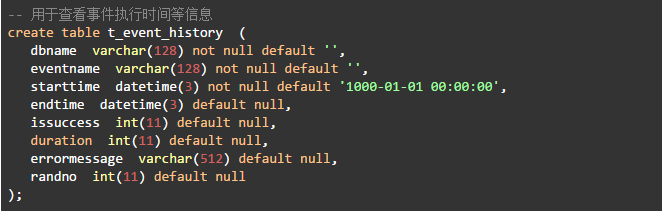
·为每个并发线程创建一个事件
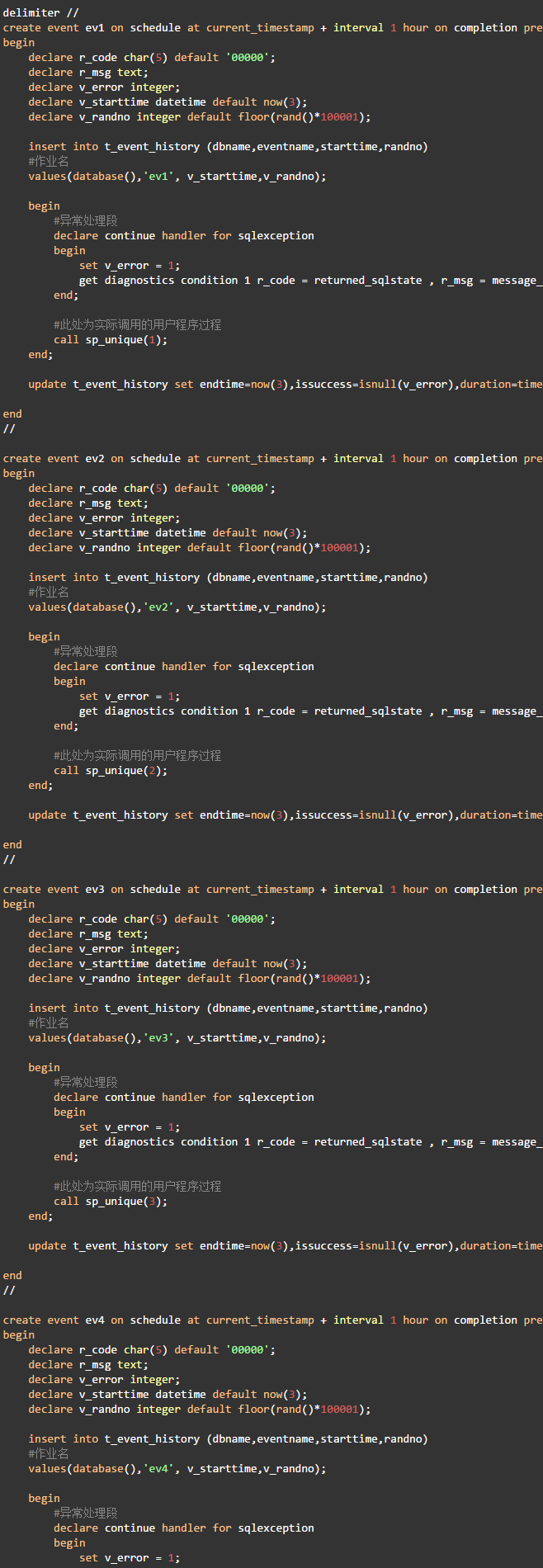
为了记录每个事件执行的时间,在事件定义中增加了操作日志表的逻辑,因为每个事件中只多执行了一条insert,一条update,4个事件总共多执行8条很简单的语句,对测试的影响可以忽略不计。执行时间精确到毫秒。
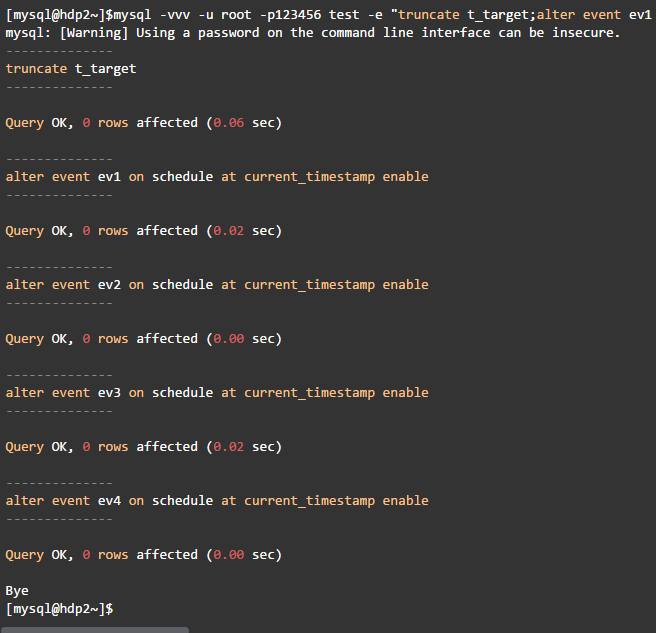
·触发事件执行

该命令行顺序触发了4个事件,但不会等前一个执行完才执行下一个,而是立即向下执行。这可从命令的输出可以清除看到:
·查看事件执行日志
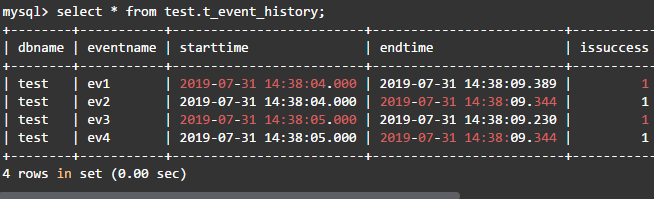
可以看到,每个过程的执行均为4.83秒,又因为是并行执行的,因此总的执行之间为最慢的5.3秒,优化效果和shell后台进程方式几乎相同。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









