







一 前言
本文介绍的是开发spark极其核心的地方,可以说懂得解决spark数据倾斜是区分一个spark工程师是否足够专业的标准,在开发中几乎天天面临这个问题。
二 原理以及现象
先来解释一下,出现什么现象的时候我们认定他为数据倾斜,以及数据倾斜发生的原理是什么?
比如一个spark任务中,绝大多数task任务运行速度很快,但是就是有那么几个task任务运行极其缓慢,慢慢的可能就接着报内存溢出的问题了,那么这个时候我们就可以认定是数据倾斜了。
接下来说一下发生数据倾斜的底层理论,其实可以非常肯定的说,数据倾斜就是发生在shuffle类的算子中,在进行shuffle的时候,必须将各个节点的相同的key拉到某个节点上的一个task来进行处理,比如按照key进行聚合和join操作等,这个时候其中某一个key数量特别大,于是就发生了数据倾斜
数据倾斜示意图
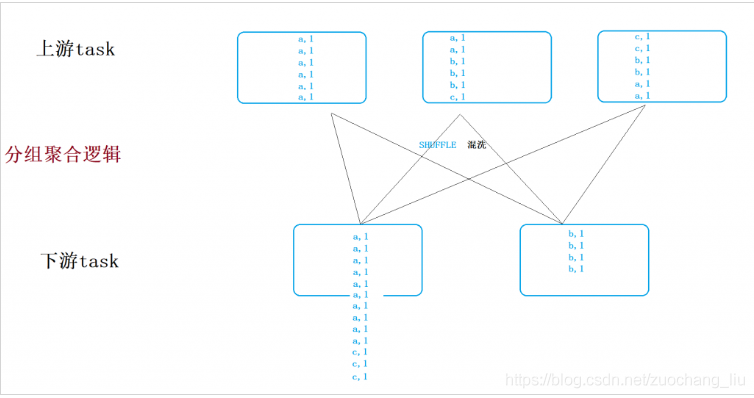
分组聚合逻辑中,需要把相同key的数据发往下游同一个task,如果某个或某几个key的数量特别大,则会导致下游的某个或某几个task所要处理的数据量特别大,也就是要处理的任务负载特别大
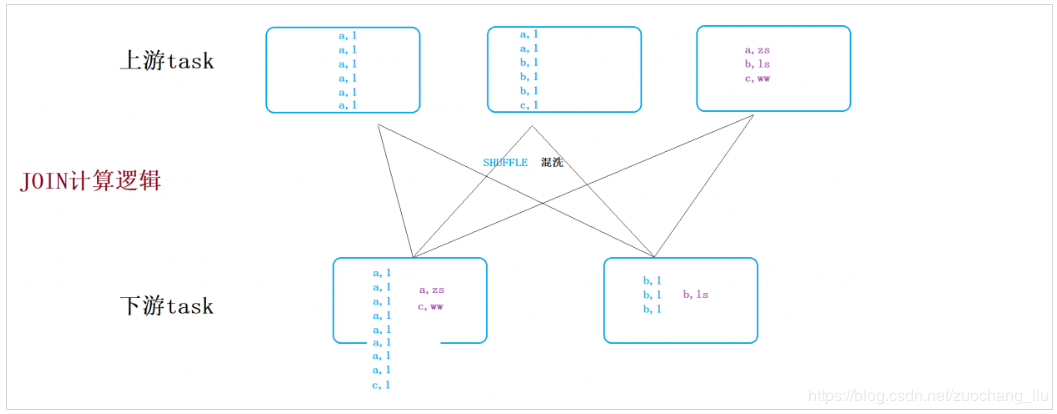
join计算中,A表和B表中相同key的数据,需要发往下游同一个task,如果A表中或B表中,某个key或某几个key的数量特别大,则会导致下游的某个或某几个task所要处理的数据量特别大,也就是要处理的任务负载特别大
三 数据倾斜的危害
当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势。
另外,当发生数据倾斜时,部分任务处理的数据量过大,可能造成内存不足使得任务失败,并进而引进整个应用失败。
四 定位数据倾斜的代码
上面我们知道了数据倾斜的底层原理,那么就好定位代码了,所以我就可以改写这段代码,让spark任务来正常运行了。
我们知道了导致数据倾斜的问题就是shuffle算子,所以我们先去找到代码中的shuffle的算子,比如distinct、groupBYkey、
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









