






初学Python实现学校图书馆座位自动抢座预约
初学Python实现学校图书馆座位自动抢座预约
最近突然有个想利用python爬取学校图书馆预约的想法(因为图书馆单人的座位很难抢)可是没学过python,就草草了解下python基础语法然后找本《Python3网络爬虫实战》来啃了。
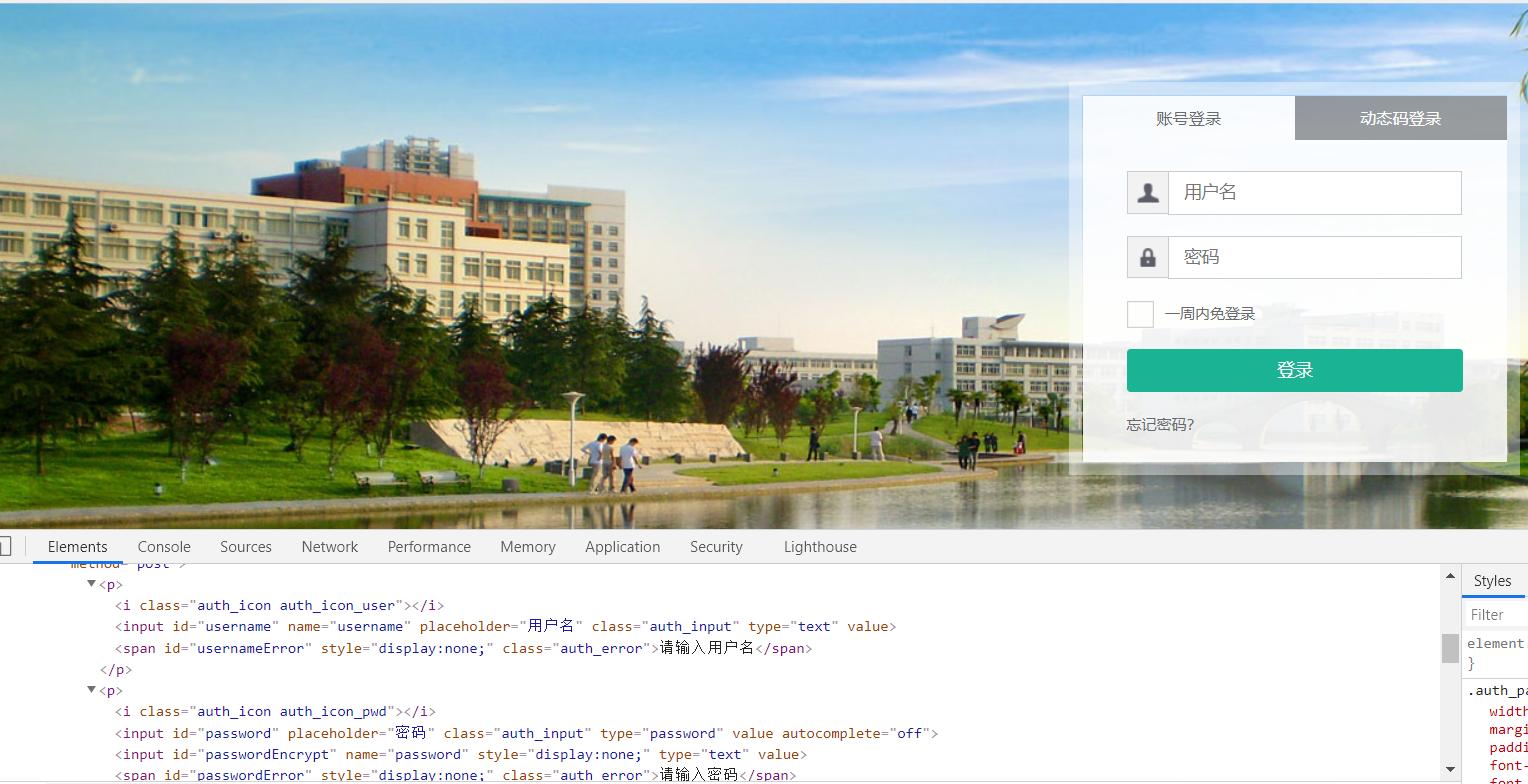
首先了解了一波urllib和request库,由于有JavaWeb的基础了解cookie,session等概念所以学起来不难。加上前面有前端的知识,所以看到预约页面的前端元素如此简单便信心满满的开始爬了,可是结果出乎意料。
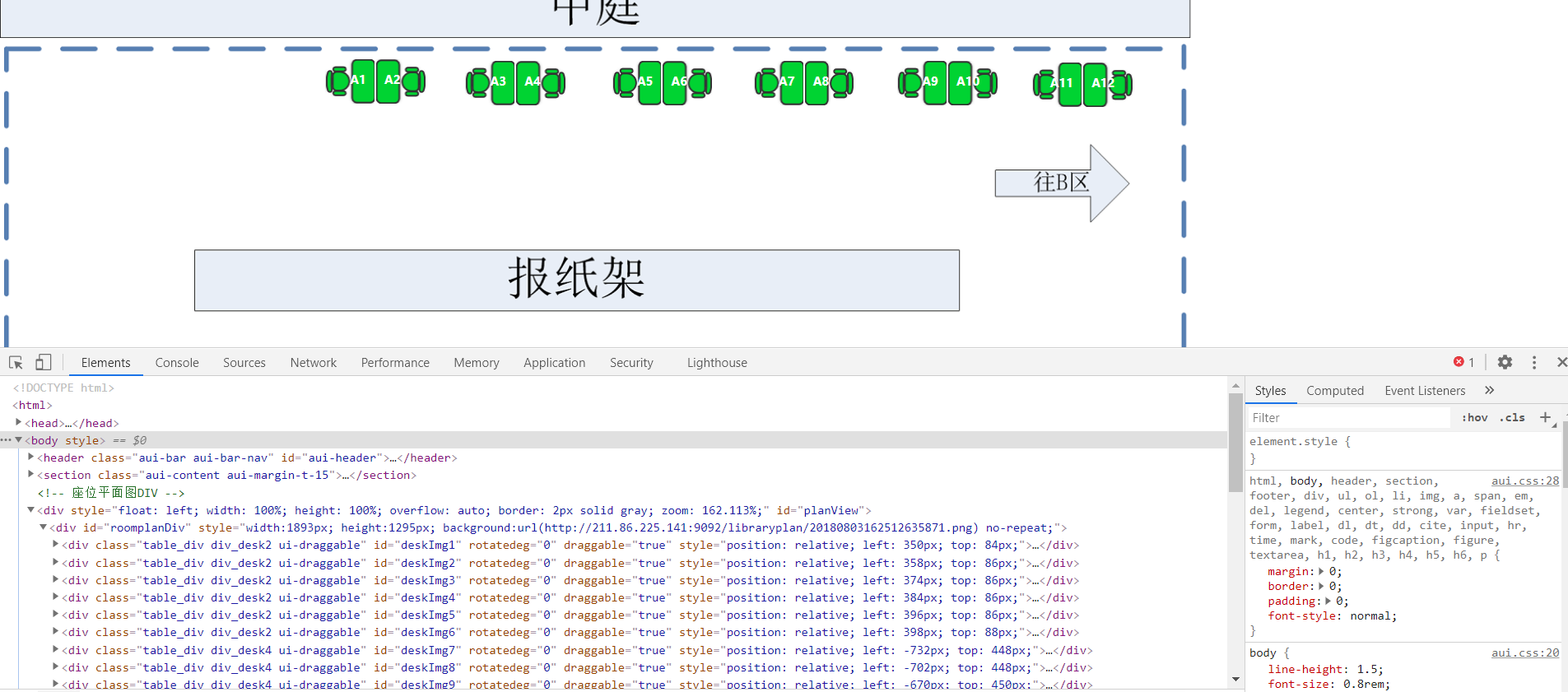
一开始思路就是用request请求带上cookie和请求参数,弄清楚请求参数
“roomId”: self.ahpu_lib[‘2B’],
“dateStr”: “2020-9-11”,
“startHour”: start_time,
“endHour”: end_time
代表的意义就可以自定义请求发送了。
def outdate(self, start_time, end_time):
url = 'http://seat.ahpu.edu.cn:9091/tsgintf/main/service'
# 请求头信息
headers = {
'Cookie': "JSESSIONID=5CC89802136333B8B7378A223D3BFD36",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
# 请求数据
json = {"intf_code": "QRY_PRE_SEAT",
"params": {
"roomId": self.ahpu_lib['2B'],
"dateStr": "2020-9-11",
"startHour": start_time,
"endHour": end_time
}
}
res = requests.post(url, json=json, headers=headers)
html = res.text
soup = BeautifulSoup(html, "lxml")
print(soup.prettify())
room_div = soup.find(attrs={'id': 'roomplanDiv'})
可是发现遍历出来的元素和网页上不一样,貌似是死的数据。后来仔细一看发现这部分是Js动态渲染的,直接请求是获取不到的。那怎么办呢?
后来又知道了selenium可以解决Js动态渲染页面元素的源代码,所以又换selenium开始爬。
selenium其实就是模仿我们用浏览器时的动作,比如点击拖动等,还可以执行一些Js脚本。运行时会打开一个浏览器窗口,而且是不支持post等其他请求的,只能用get请求。
首先当然是设置一下初始化所需要的参数和保存数据的变量。
def __init__(self,username,password):
# 浏览器对象
option = webdriver.ChromeOptions
option.headless = True
self.browser = webdriver.Chrome()
self.username = username
self.password = password
self.now = datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d')
#安徽工程大学图书馆楼层区域对应的roomId
self.ahpu_lib = {
'2A': '36', '2B': '37', '3A': '38', '3B': '39', '3C': '40', '4A': '42', '4B': '43', '4C': '44', '4E': '46',
'5A': '47', '5B': '48',
'5C': '49', '5D': '50', '6A': '51', '6B': '52', '6C': '53', '6D': '54', '6E': '55', '5S': '56'
}
# 保持登录状态所需cookie
self.loginData = {'domain': 'seat.ahpu.edu.cn', 'httpOnly': True, 'name': 'JSESSIONID', 'path': '/tsgintf',
'secure': False, 'value': 'F14952287EFA449AB69F3DAE46AC86D0'}
# 被占座位
self.seated = 0
# 剩余座位
self.left = 0
# 不可坐的
self.forbid = 0
# 双人座
self.single = []
然后再写一个登录方法,由于预约必须要登录,否则就会自动重定向到登录页面,所以我们用selenium来模仿登录。
登录重要的部分就是将loginData更新,也就是更新为登录状态下的cookie,以后每次刷新携带此Cookie就会保持登录状态了。
def login(self):
self.browser.get('http://seat.ahpu.edu.cn:9091/tsgintf/wechat/seat/html/reserving1.html?version=1.1')
wait = WebDriverWait(self.browser, 2)
# 登录
try:
UN = wait.until(EC.presence_of_element_located((By.ID, 'username')))
PW = wait.until(EC.presence_of_element_located((By.ID, 'password')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.auth_login_btn')))
except NoSuchElementException:
print("No Element!")
try:
self.browser.execute_script("arguments[0].value = '" + self.username + "';", UN)
self.browser.execute_script("arguments[0].value = '" + self.password + "';", PW)
self.browser.execute_script("javascript:$('.iCheck-helper').click();")
button.click()
except Exception:
print("Send Error!")
#设置Cookie
self.loginData.clear()
self.loginData = self.browser.get_cookie('JSESSIONID')
再写一个设置cookie的方法,也就是将browser浏览器添加我们的loginData这个cookie,前面的get请求是请求学校官网,因为执行add_cookie方法前必须要写一个同域名的请求。
#设置cookie
def set_Cookie(self):
self.browser.get('http://ids.ahpu.edu.cn/authserver/login?service=http%3A%2F%2Fxjwxt.ahpu.edu.cn%2Fahpu%2Flogin.action')
self.browser.add_cookie(self.loginData)
self.browser.get('http://seat.ahpu.edu.cn:9091/tsgintf/wechat/seat/html/reserving1.html?version=1.1')
(信息提交)
再来一个选择方法,预约所需的信息提交都交给这个方法
def choose(self,begin,over):
lib = self.browser.find_element_by_id('libraryId')
date = self.browser.find_element_by_id('dateStrId')
type = self.browser.find_element_by_id('typeStrId')
start = self.browser.find_element_by_id('startHourStrId')
end = self.browser.find_element_by_id('endHourStrId')
button = self.browser.find_element_by_css_selector('.aui-btn')
self.browser.execute_script("arguments[0].value = '3';", lib)
self.browser.execute_script("arguments[0].value = '" + self.now + "';", date)
self.browser.execute_script("arguments[0].value = '1';", type)
self.browser.execute_script("arguments[0].value = '" + begin + "';", start)
self.browser.execute_script("arguments[0].value = '" + over + "';", end)
button.click()
再写一个抢座的方法
这个方法就是执行一段脚本,通过看页面源码发现doPreSeat方法就是选择座位并预定了,参数是通过座位的名字来预定。
外面会有一个循环,如果抢座成功说明可以跳出这个循环了return False,否则就是继续循环抢座,return True
def occupy(self,location):
try:
self.browser.execute_script("doPreSeat('"+location+"',roomId,dateStr, getStorageItem('userPhysicalCard'), startHour, endHour);")
self.sendEmail(""+location+"抢座成功!")
return False
except:
return True
最重要的方法来了,就是遍历所有页面元素

首先设置cookie,如果此时cookie过期了就执行登录方法更新一下cookie再去请求。
根据这些html代码结合渲染出来的页面可以发现,class属性中最后是3的就是空余座位,1就是被占的,2就是为了防疫不许坐的座位。
由于我们要抢的是单人座,所以如果是单人座的话就直接抢,否则就统计一下情况,由于需要不断循环所以需要将数据全部归0.
def search(self,place,begin,over):
self.set_Cookie()
# 默认执行循环
flag = True
try:
self.choose(begin,over)
except:
print('登录过期!')
self.login()
self.set_Cookie()
self.choose(begin,over)
self.browser.execute_script("gotoReserving3Page("+self.ahpu_lib[place]+");")
# 加载页面
time.sleep(0.5)
soup = BeautifulSoup(self.browser.page_source,'lxml')
room_div = soup.find(attrs={'id': 'roomplanDiv'})
# 是否需要抢座,目的保证每次for循环都能执行
con = True
for desk in room_div.children:
# 单人座抢座
if len(list(desk.children)) == 2:
for ds in desk.children:
n = str(ds.attrs['class'])[-3:-2]
print(n)
if n == '3':
loc = ds.contents[0].string
self.single.append(loc)
if con:
flag = self.occupy(loc)
con = False
# 统计
for seat in desk.children:
s = str(seat.attrs['class'])
# 座位是否空闲看末尾的数字
n = s[-3:-2]
if n == '3':
self.left += 1
elif n == '1':
self.seated += 1
else:
self.forbid += 1
print("空闲座位{}个,不可坐座位{}个,被占座位{}个,单人空闲座位{}个".format(self.left,self.forbid,self.seated,len(self.single)))
self.left = 0
self.forbid = 0
self.seated = 0
self.single.clear()
return flag
最后就是无限循环了,可以设置一个定时任务,凌晨自动开始要不了几次循环就能抢到了。
if __name__ == '__main__':
print("输入用户名:学号")
username = input()
print("输入密码:")
password = input()
print("输入地点:格式 2A (2层A区域)")
place = input()
print("输入开始时间:(格式 12:00,根据官网只能预约当天)")
start = input()
print("输入结束时间:(间隔至少为1小时!)")
end = input()
app = Seat.Auto_Occupy(username,password)
while app.search(place,start,end):
print("运行中......")
print("成功!欢迎使用")
整个项目大约花了两,三个礼拜,不得不说python用起来还是很方便的,不过学校的抢座系统也没做啥反爬措施,爬起来难度也不是很大。
初学Python实现学校图书馆座位自动抢座预约相关教程














 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









