







- 分类是NLP处理中的一项基本任务,可以是两类,多类甚至多标签分类。可以基于tensorflow,keras或者pytorch来完成。本文采用训练好的词向量+LSTM模型来完成分类。本文是英文分类的样例,中文分类类似,可以先按文章路径下载词向量文件,然后准备训练数据,依次准备,进行训练。
- 如果需要数据和完整源代码请在文章后留言。
- 预训练的词向量有很多,英文的包括glove的各种版本,实际上100维或者200维的足够满足日常使用。glove.6B.100d。中文的也很多,可以到这个路径下载:Embedding/Chinese-Word-Vectors
- 情感分类通常包括:生成数据集,训练或使用现成的词向量进行数据表示,准备训练模型,准备验证函数等,下面依次描述。
- 生成数据集。可以使用torchtext进行数据集生成。
torchtext的使用可以参考这个链接:Torchtext使用教程
数据文件包括:train.txt,eval.txt,test.txt,格式如下:
文本内容,标签(0/1),用 t 分隔,比如:
it 's worth taking the kids to 1
without shakespeare 's eloquent language , the update is dreary and sluggish 0
dense , exhilarating documentary 1
下面定义数据集生成函数:
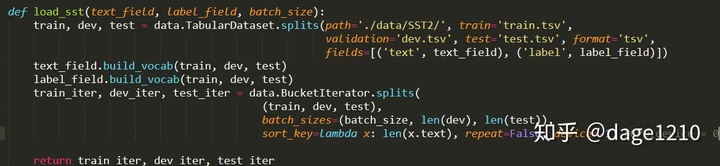
- 训练或使用现有的词向量进行数据表示,完成模型的embeddings
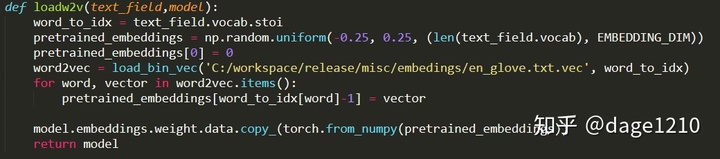
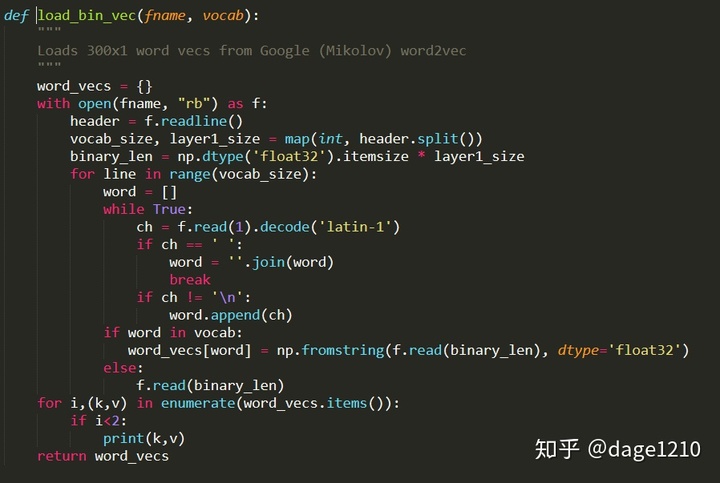
- 其中load_bin_vec函数的主要功能是完成从词向量文件,生成向量词典:
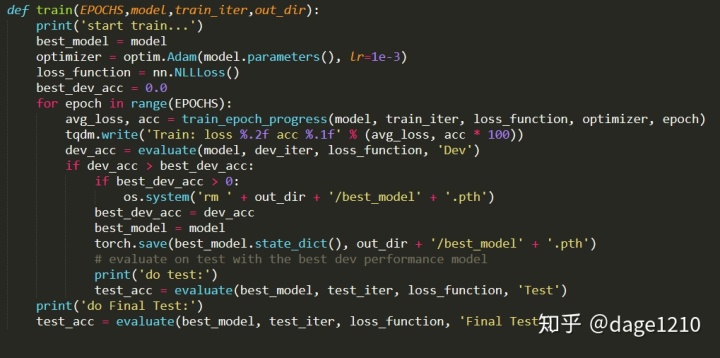
- 实现训练模型
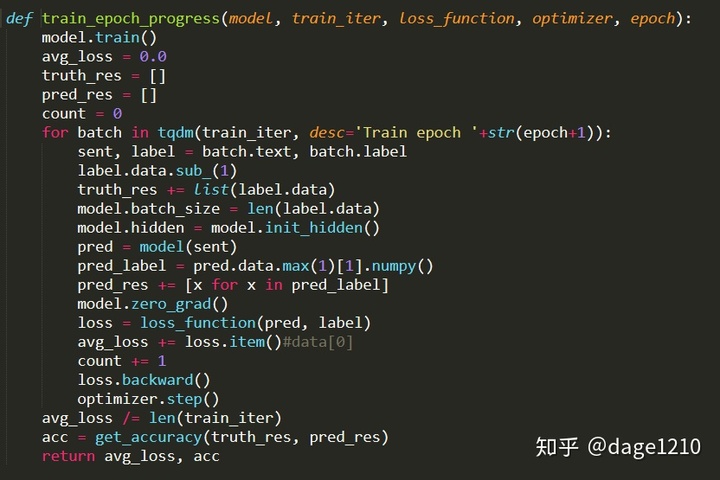
- 完成一轮训练的函数train_epoch_progress()
- LSTM模型定义:模型比较简单,首先是embedding层,然后是LSTM层,然后是hidden2label,输出各类标签的概率,然后通过F.log_softmax()函数取最大概率的一类。
- 另外,最新的torch版本不再使用Variable,可以使用init_hidden_plus()

- 准备验证函数
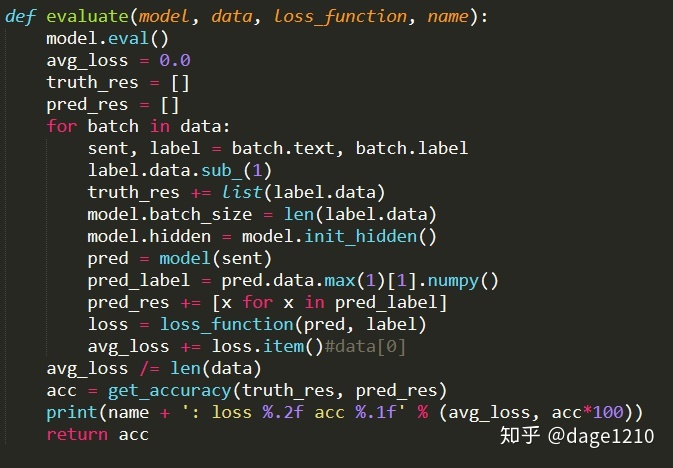
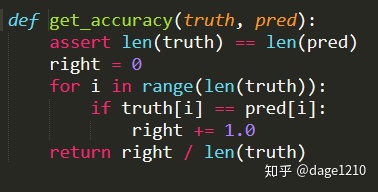
其中,get_accuracy()函数完成实际类别和预测类别的对比,计算准确率。
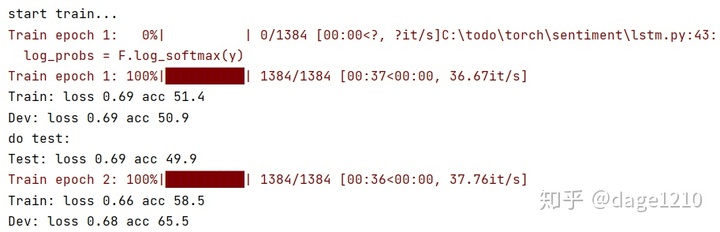
训练过程,两轮之后可以达到65.5%,6轮之后达到77.6%准确率。

还可以查看模型的相关信息:
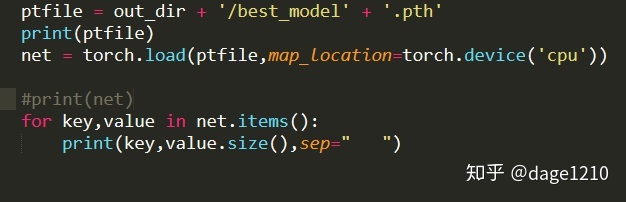
C:todotorchsentimentruns1607164778/best_model.pth
embeddings.weight torch.Size([16190, 100])
lstm.weight_ih_l0 torch.Size([600, 100])
lstm.weight_hh_l0 torch.Size([600, 150])
lstm.bias_ih_l0 torch.Size([600])
lstm.bias_hh_l0 torch.Size([600])
hidden2label.weight torch.Size([2, 150])
hidden2label.bias torch.Size([2])














 9377
9377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









