







I. 读写文本文件
i) read_csv() / read_table()
ii) to_csv()
iii) pd.read_excel()
iv) pd.to_excel()
v) 打开大文件(.csv)
II. 读写json数据
i) pd.read_json()
ii) Series.to_json() / DataFrame.to_json()
III. 从数据库中读取数据
i) pd.read_sql()I. 读取文本格式的数据
以下是pandas中用于将表格型数据的读取为DataFrame对象的函数,其中以pd.read_csv()方法和pd.read_table()方法最为常用
函数 说明
read_csv 把csv文件转化为DataFrame对象。默认分隔符为逗号(,)
read_table 把常规的带分隔符的文件转化为DataFrame对象。默认分隔符为制表符(/t)
read_fwf 读取定宽列格式数据(也就是说,没有分隔符)
read_clipboard 把剪贴板中的数据转化为DataFrame对象i)read_csv() / read_table()
这两个方法除了默认的分隔符不同之外,其他参数都一样,所以就一起介绍了。
由于其中的参数很多,我仅从个人使用经验出发重点介绍几个参数,以下排名分先后:
read_csv() / read_table()
read_table(filepath_or_buffer, sep='t', delimiter=None, header='infer',
names=None, index_col=None, usecols=None, squeeze=False,
prefix=None, mangle_dupe_cols=True, dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, nrows=None, na_values=None,
keep_default_na=True,na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=False, infer_datetime_format=False,
keep_date_col=False, date_parser=None, dayfirst=False, iterator=False,
chunksize=None, compression='infer', thousands=None, decimal=b'.',
lineterminator=None, quotechar='"', quoting=0, escapechar=None,
comment=None, encoding=None, dialect=None, tupleize_cols=None,
error_bad_lines=True, warn_bad_lines=True, skipfooter=0,
doublequote=True, delim_whitespace=False, low_memory=True,
memory_map=False, float_precision=None)
engine 解析器引擎, 可选'c'或'python', 默认为None. C更快, 但Python功能更完备.
填'c'或默认不填都会造成文件初始化失败, 这里直接选'python'即可,。
encoding 读写文件使用的编码方式.字符串类型, 默认为None.
我们常遇到含中文的csv文件, 此时推荐选择'utf-8-sig'或'utf_8_sig'
names 要使用的列名字符串的列表.类数组, 默认为None.
如果文件不包含字段行, 应该显式传递header=None.如果names列表中有重复的
字段名,会报UserWarning.
header 用作列名的行号(可以为多个).整数或整数的列表, 默认为'infer'.
默认行为是推测列名:
1.如果names参数没有列名字符串的列表传入, 行为等同于header=0,
即把第一行作为字段名
2.如果names参数有列名字符串的列表传入, 行为等同于header=None
index_col Column(s) to use as the row labels of the ``DataFrame``
可以是int, str, sequence of int / str 或 False, 默认为None.
int指column index(从0开始), str指column name,
如果传入的是字符串或整数的序列, 则使用MultiIndex
int or sequence or False, default None. If a sequence is given, a
MultiIndex is used.
parse_dates boolean or list of ints or names or list of lists or dict,
default False
* boolean. If True -> try parsing the index.
* list of ints or names. e.g. If [1, 2, 3] -> try parsing
columns 1, 2, 3 each as a separate date column.
* list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and
parse as a single date column.
* dict, e.g. {'foo' : [1, 3]} -> parse columns 1, 3 as date and call
result 'foo'
If a column or index contains an unparseable date, the entire column
or index will be returned unaltered as an object data type.
For non-standard datetime parsing, use ``pd.to_datetime`` after
``pd.read_csv``
Note: A fast-path exists for iso8601-formatted dates.
chunksize 每个块(chunk)中行的数量,打开大文件时使用. int, default None
nrows Number of rows of file to read. Useful for reading pieces of large files
(快速查看大数据集的前n行,非常快) int, default None
usecols Return a subset of the columns.
list-like or callable, default None
If list-like, all elements must either be positional
(i.e. integer indices into the document columns) or strings that
correspond to column names provided either by the user in `names` or
inferred from the document header row(s). For example, a
valid list-like `usecols` parameter would be [0, 1, 2] or
['foo', 'bar', 'baz']. Element order is ignored, so ``usecols=[0, 1]``
is the same as ``[1, 0]``.read_csv()和read_table()方法只是分隔符不同的区别:

有了read_table(),我们很多时间就不需要用with open打开txt文件了:

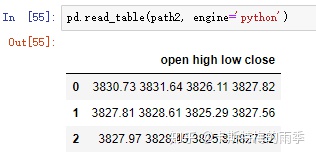
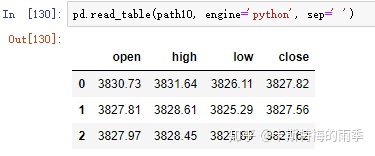
一个示例:
数据集如下

如果用with open解析:
def data_processing(path):
'''K线数据处理'''
with open(path) as f:
content = f.readlines()
content = [json.loads(dic.rstrip()) for dic in content]
t = [datetime.fromtimestamp(dic.get('id')) for dic in content]
o = [dic.get('open') for dic in content]
h = [dic.get('high') for dic in content]
l = [dic.get('low') for dic in content]
c = [dic.get('close') for dic in content]
v = [dic.get('vol') for dic in content]
df = pd.DataFrame({
'time': t,
'open': o,
'high': h,
'low': l,
'close': c,
'volume': v
})
df.set_index('time', inplace=True)如果用read_table()解析:
def data_processing(path):
'''K线数据处理'''
df = pd.read_table(path, engine='python', names=['records'])
df['records'] = df['records'].map(lambda x: json.loads(x))
df['timestamp'] = df['records'].map(lambda x: datetime.fromtimestamp(x.get('id')))
df['open'] = df['records'].map(lambda x: x.get('open'))
df['high'] = df['records'].map(lambda x: x.get('high'))
df['low'] = df['records'].map(lambda x: x.get('low'))
df['close'] = df['records'].map(lambda x: x.get('close'))
df.drop('records', axis=1, inplace=True)
df.set_index('timestamp', inplace=True)
return df综合示例:
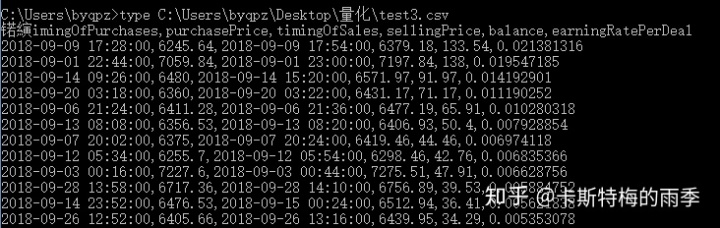
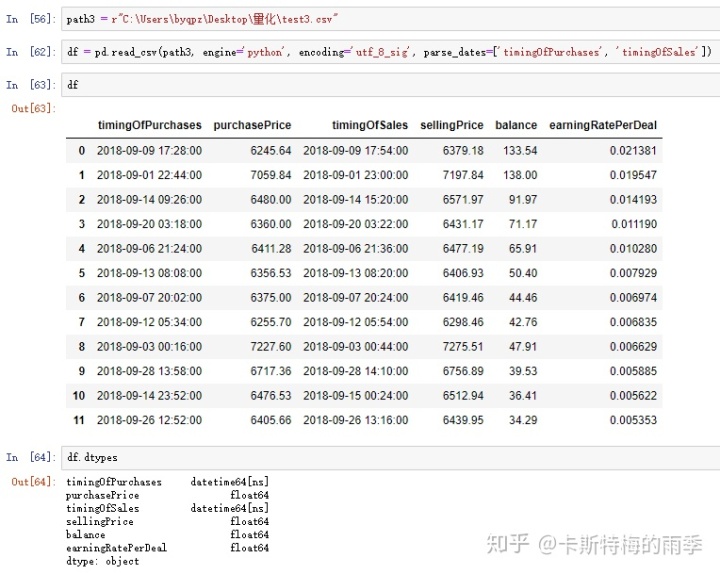
ii) to_csv()
这个方法用于把pandas对象写入csv文件中
to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True,
index=True, index_label=None, mode='w', encoding=None, compression=None,
quoting=None, quotechar='"', line_terminator='n', chunksize=None, tupleize_cols=None,
date_format=None, doublequote=True, escapechar=None, decimal='.')
参数
path_or_buf 保存路径
string or file handle, default None
File path or object, if None is provided the result is returned as a string.
index 是否保留行索引
boolean, default True
Write row names (index)
encoding 如果包含中文, 必须加上encoding='utf_8_sig'
string, optional
A string representing the encoding to use in the output file,
defaults to 'ascii' on Python 2 and 'utf-8' on Python 3.DataFrame保存到csv文件
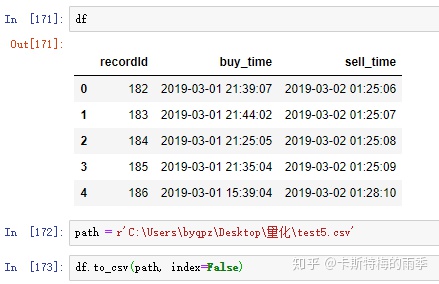
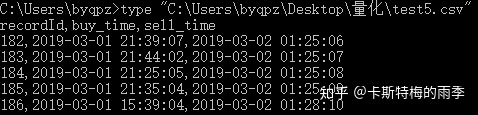
Series保存到csv文件
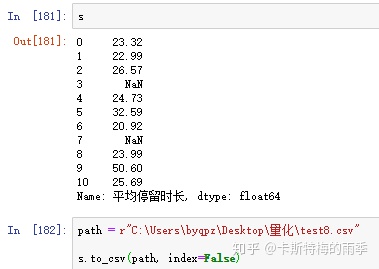

如果包含中文
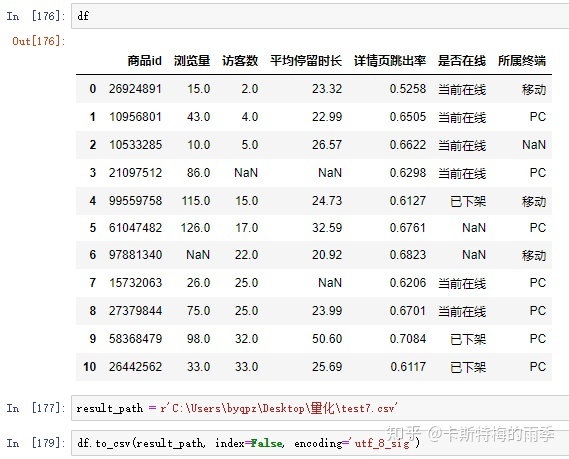
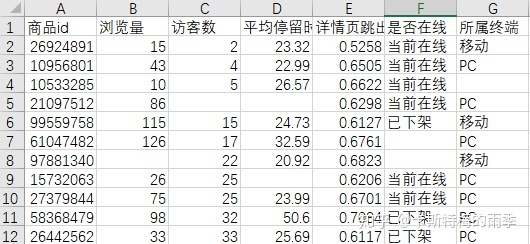
iii)pd.read_excel()
read_excel()方法和前面介绍的两个方法参数大同小异。
小异如下:
- read_excel()方法有一个sheet_name参数,用于指定工作表
- 对于read_excel()方法,engine和encoding都是不需要的。
- read_excel()方法没有chunksize参数
- read_excel()方法的usecols参数不能指定字符串的列表
read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None,
squeeze=False, dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skiprows=None, nrows=None, na_values=None, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True,
**kwds)
sheet_name string, int, mixed list of strings/ints, or None, default 0
Strings are used for sheet names
Integers are used in zero-indexed sheet positions.
Lists of strings/integers are used to request multiple sheets.
Specify None to get all sheets.
str|int -> DataFrame is returned.
list|None -> Dict of DataFrames is returned, with keys representing
sheets.
Available Cases
* Defaults to 0 -> 1st sheet as a DataFrame
* 1 -> 2nd sheet as a DataFrame
* "Sheet1" -> 1st sheet as a DataFrame
* [0,1,"Sheet5"] -> 1st, 2nd & 5th sheet as a dictionary of DataFrames
* None -> All sheets as a dictionary of DataFrames
names : array-like, default None
List of column names to use. If file contains no header row,
then you should explicitly pass header=None
header int, list of ints, default 0
Row (0-indexed) to use for the column labels of the parsed
DataFrame. If a list of integers is passed those row positions will
be combined into a ``MultiIndex``. Use None if there is no header.
index_col int, list of ints, default None
Column (0-indexed) to use as the row labels of the DataFrame.
Pass None if there is no such column. If a list is passed,
those columns will be combined into a ``MultiIndex``. If a
subset of data is selected with ``usecols``, index_col
is based on the subset.
parse_dates
bool, list-like, or dict, default False
The behavior is as follows:
bool. If True -> try parsing the index.
list of int or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3 each as
a separate date column.
list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and parse as
a single date column.
dict, e.g. {{‘foo’ : [1, 3]}} -> parse columns 1, 3 as date and call result ‘foo’
If a column or index contains an unparseable date, the entire column or
index will be returned unaltered as an object data type. For non-standard datetime
parsing, use pd.to_datetime after pd.read_csv
nrows int, default None
Number of rows to parse
usecols int or list, default None
* If None then parse all columns,
* If int then indicates last column to be parsed
* If list of ints then indicates list of column numbers to be parsed
* If string then indicates comma separated list of Excel column letters and
column ranges (e.g. "A:E" or "A,C,E:F"). Ranges are inclusive of
both sides.示例1
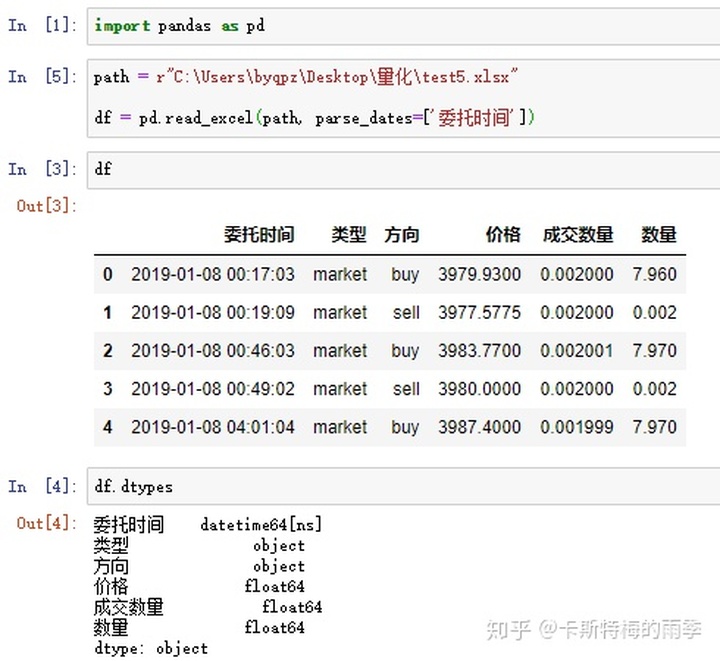
示例2
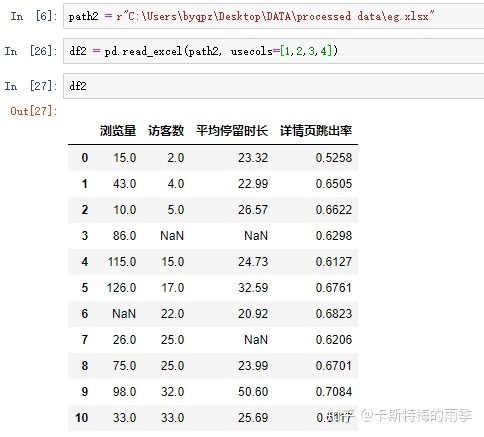
iv) pd.to_excel()
把pandas对象写入一个excel工作表中
to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None,
header=True, index=True, index_label=None, startrow=0, startcol=0,
engine=None, merge_cells=True, encoding=None, inf_rep='inf',
verbose=True, freeze_panes=None)
excel_writer 文件路径或已存在的ExcelWriter对象
string or ExcelWriter object
File path or existing ExcelWriter
sheet_name string, default 'Sheet1'
Name of sheet which will contain DataFrame
index boolean, default True
Write row names (index)
header : bool or list of str, default True
Write out the column names. If a list of string is given it is
assumed to be aliases for the column names.
freeze_panes tuple of int (length 2), optional
冻结窗格, 第一个参数为行, 第二个参数为列, 如冻结首行应写为(1,0)
和read_excel类似,包含中文时无需注明encoding
示例1:
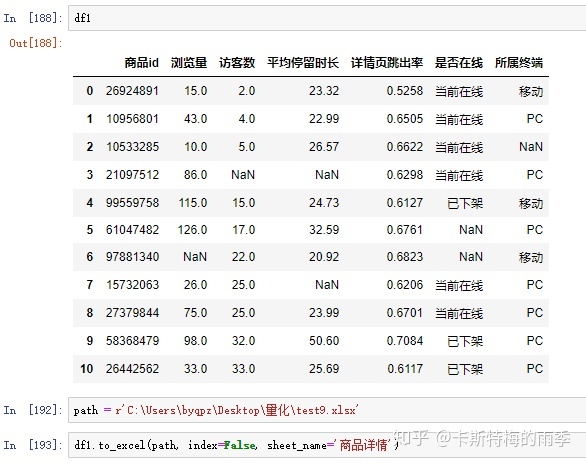
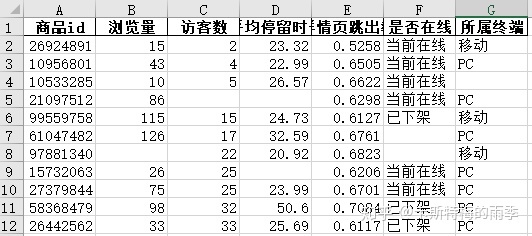

示例2:
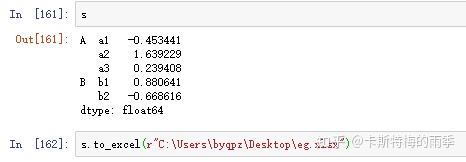
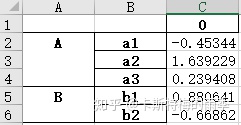

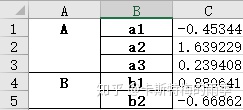
除此之外还可以用如下这种形式往一个工作簿中写入多张工作表:
>>> writer = pd.ExcelWriter('output.xlsx')
>>> df1.to_excel(writer,'Sheet1')
>>> df2.to_excel(writer,'Sheet2')
>>> writer.save()那么,如何往既有的工作簿中写入新的工作表呢?
方法一:
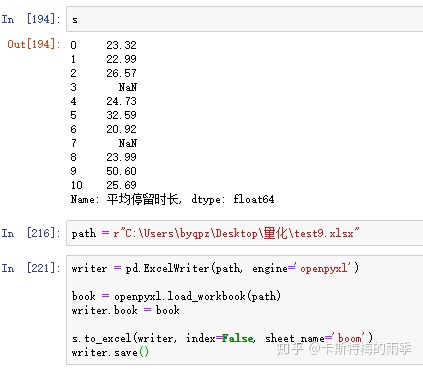
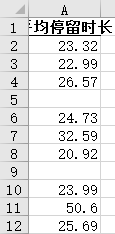
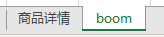
方法二:
pandas在0.24版本中给出了更方便的解决方案:

所以如果你用的是0.23或更低版本的pandas记得先升级:
pip install --upgrade pandas然后这么操作:

推荐方法二,非常方便,这也是官方推荐的方法。
iii)打开大文件(.csv)
偶尔,我们在处理数据时会遇到数百兆甚至几个G的数据集,这个时候别说处理,连查看都很难做到(如果你是个只用excel的分析师就更加难受了)。
文本使用的数据集如下:
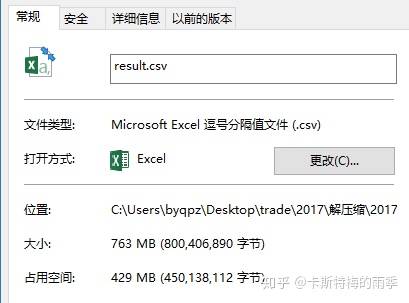
如果用excel打开会非常卡:

查看数据集
在得到一个数据集时,我们往往会先查看它的字段和数据,通过在read_csv()方法中指定nrows即可快速查看数据集的前n行,非常快
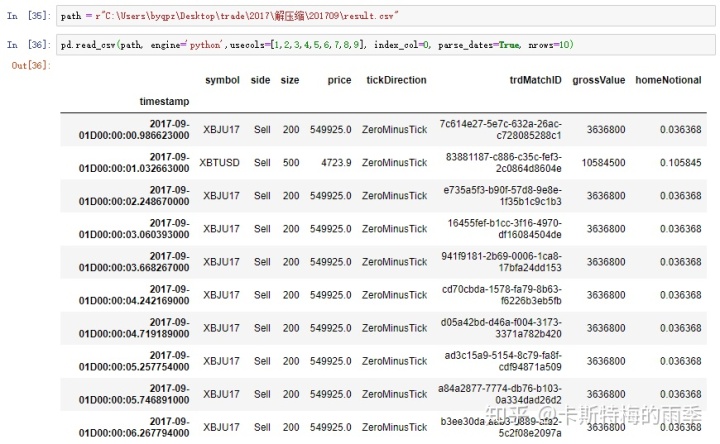
读取文件
开始之前,我们先看一下常规方法的耗时
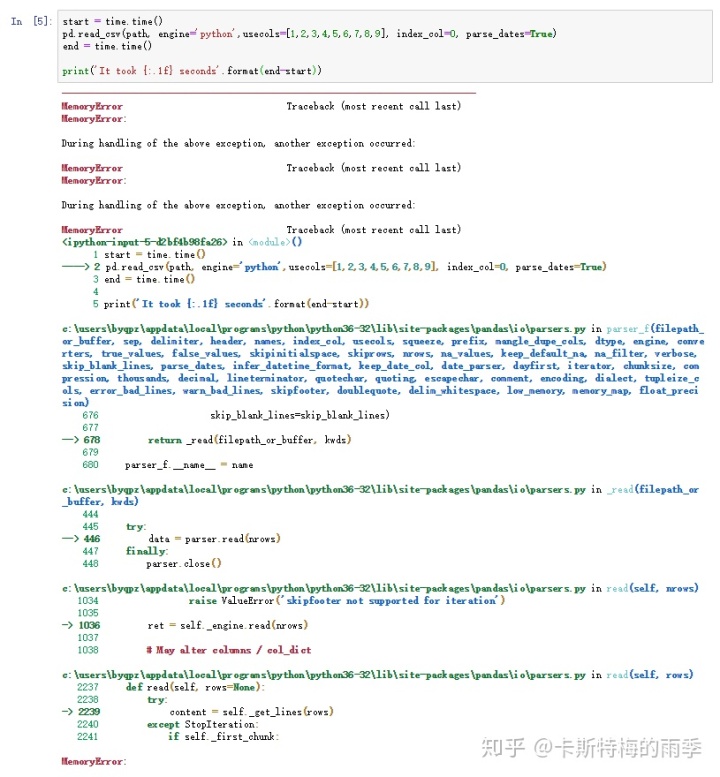
发现根本读不出来
然后我们看一下设置chunksize参数后的效果
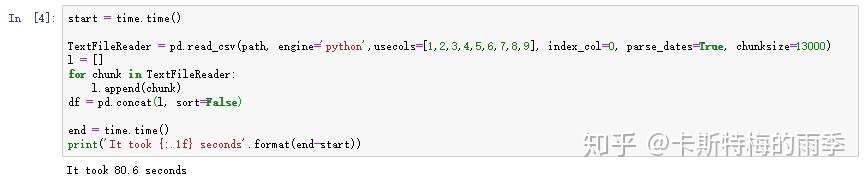
稍微花了点时间,因为算上了合并子DataFrame的开销,也可以不合并,把每个子DataFrame单独做处理,视具体情况而定。
II. 读写json数据
json标准库我们都知道,我们通常都用它来加载json文件、转换json字符串,但其实pandas提供了更为强大的json读写方法,而且这些方法和DataFrame、Series结合得更紧密,毕竟这两个是我们数据分析中最常用到的数据结构。所以本着哪个好用用哪个的实用主义精神,让我们告别json.load()/json.loads(),拥抱pd.read_json().
i) pd.read_json()
这个方法的作用是将json字符串转化为pandas对象(注意,是json字符串不是json对象)
read_json(path_or_buf=None, orient=None, typ='frame', dtype=True, convert_axes=True,
convert_dates=True, keep_default_dates=True, numpy=False, precise_float=False,
date_unit=None, encoding=None, lines=False, chunksize=None, compression='infer')
参数
path_or_buf 要解析的json字符串或类文件对象
a valid JSON string or file-like, default: None
The string could be a URL. Valid URL schemes include http, ftp, s3, gcs, and file.
For file URLs, a host is expected. For instance,
a local file could be file://localhost/path/to/table.json
typ 目标类型, 'frame'或'series', 默认是'frame'
type of object to recover (series or frame), default ‘frame’
orient JSON字符串的格式表示, 如果typ == 'series',默认是'index',
如果typ == 'frame', 默认是'columns'
Indication of expected JSON string format. string. Compatible JSON strings can be
produced by to_json() with a corresponding orient value. The set of possible
orients is:
'split' : dict like {index -> [index], columns -> [columns], data -> [values]}
'records' : list like [{column -> value}, ... , {column -> value}]
'index' : dict like {index -> {column -> value}} 或 {index → value}
'columns' : dict like {column -> {index -> value}} 或[{column →value}]
'values' : just the values array
The allowed and default values depend on the value of the typ parameter.
when typ == 'series',
allowed orients are {'split','records','index'}
default is 'index'
The Series index must be unique for orient 'index'.
when typ == 'frame',
allowed orients are {'split','records','index', 'columns','values', 'table'}
default is 'columns'
The DataFrame index must be unique for orients 'index' and 'columns'.
The DataFrame columns must be unique for orients 'index', 'columns', and 'records'.
New in version 0.23.0: ‘table’ as an allowed value for the orient argument
convert_axes boolean, default True
Try to convert the axes to the proper dtypes.
convert_dates
boolean, default True
List of columns to parse for dates; If True, then try to parse datelike
columns default is True; a column label is datelike if
it ends with '_at',
it ends with '_time',
it begins with 'timestamp',
it is 'modified', or
it is 'date'
lines boolean, default False
Read the file as a json object per line.
New in version 0.19.0.
解析json字符串为Series:
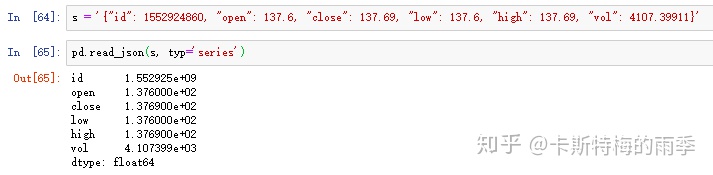
解析json字符串为DataFrame

读取json文件为DataFrame

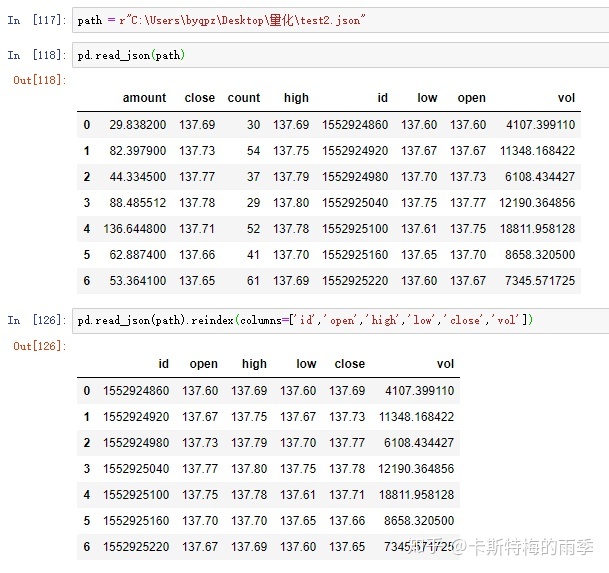
读取txt文件为DataFrame

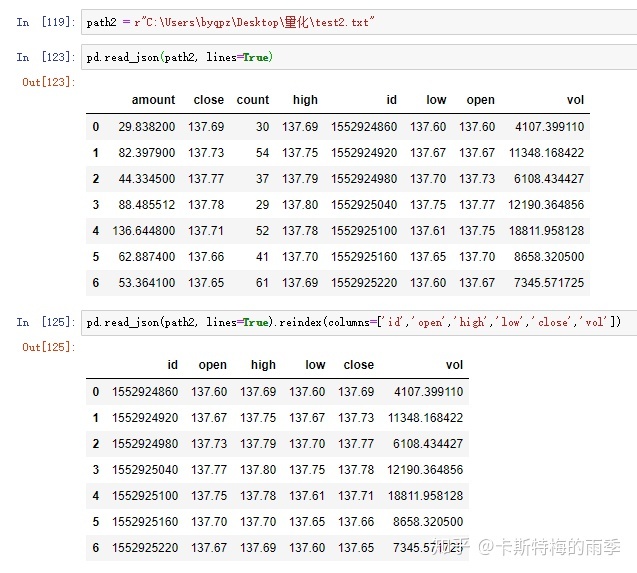
所以前面的函数可以这么写:
def data_processing(path):
'''K线数据处理'''
df = pd.read_json(path, lines=True).reindex(columns=['id','open','high','low','close'])
df['id'] = df['id'].map(lambda x: datetime.fromtimestamp(x))
df.set_index('id', inplace=True)
return dfii) Series.to_json() / DataFrame.to_json()
把pandas对象转化为json字符串
Convert the object to a JSON string.
Note NaN's and None will be converted to null and datetime objects
will be converted to UNIX timestamps.
to_json(path_or_buf=None, orient=None, date_format=None, double_precision=10,
force_ascii=True, date_unit='ms', default_handler=None, lines=False,
compression=None, index=True)
path_or_buf string or file handle, optional
File path or object. If not specified, the result is returned as
a string.
orient string
Indication of expected JSON string format.
* Series
- default is 'index'
- allowed values are: {'split','records','index'}
* DataFrame
- default is 'columns'
- allowed values are:
{'split','records','index','columns','values'}
* The format of the JSON string
- 'split' : dict like {'index' -> [index],
'columns' -> [columns], 'data' -> [values]}
- 'records' : list like
[{column -> value}, ... , {column -> value}]
- 'index' : dict like {index -> {column -> value}}
- 'columns' : dict like {column -> {index -> value}}
- 'values' : just the values array
- 'table' : dict like {'schema': {schema}, 'data': {data}}
describing the data, and the data component is
like ``orient='records'``.
.. versionchanged:: 0.20.0
lines boolean, default False
If 'orient' is 'records' write out line delimited json format. Will
throw ValueError if incorrect 'orient' since others are not list like.
index boolean, default True
Whether to include the index values in the JSON string. Not
including the index (``index=False``) is only supported when
orient is 'split' or 'table'.把pandas对象转化为json字符串1:
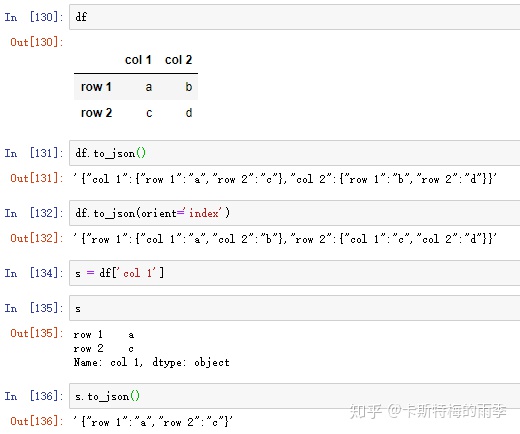
把pandas对象转化为json字符串2:
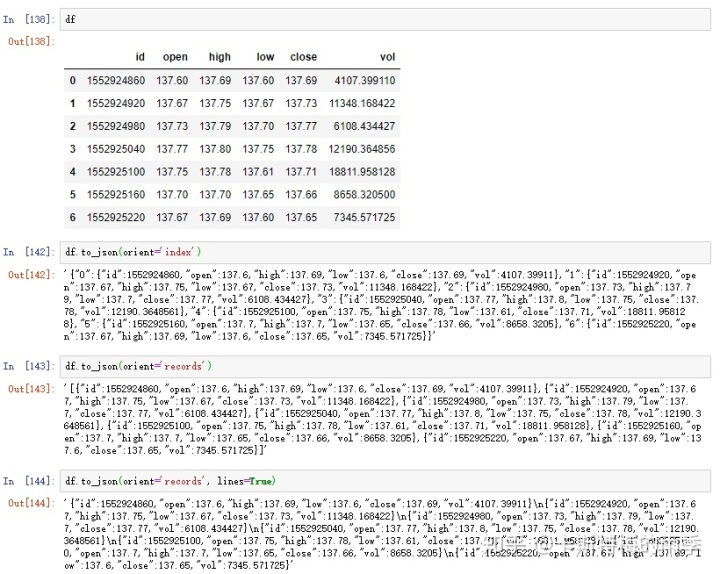
把pandas对象转化为json文件
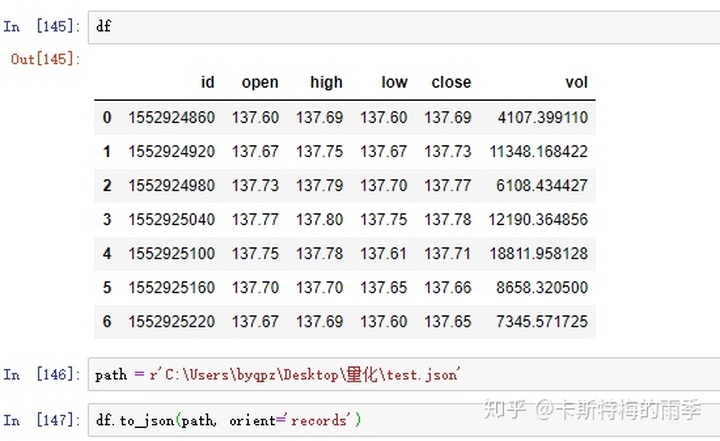
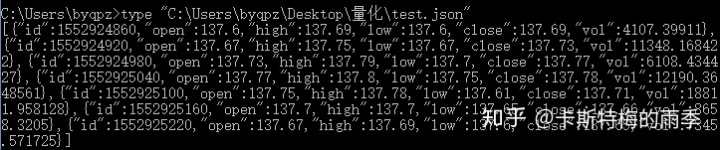
III. 从数据库中读取数据
i) pd.read_sql()
把SQL查询结果或数据库的表读取为DataFrame.这个方法其实是read_sql_query()和read_sql_table()的封装,read_sql()根据输入选择不同的方法执行。
Read SQL query or database table into a DataFrame.
This function is a convenience wrapper around ``read_sql_table`` and
``read_sql_query`` (for backward compatibility). It will delegate
to the specific function depending on the provided input. A SQL query
will be routed to ``read_sql_query``, while a database table name will
be routed to ``read_sql_table``. Note that the delegated function might
have more specific notes about their functionality not listed here.
read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None,
columns=None, chunksize=None)
sql SQL查询语句或表名
string or SQLAlchemy Selectable (select or text object)
SQL query to be executed or a table name.
con 数据库连接对象
SQLAlchemy connectable (engine/connection) or database string URI
or DBAPI2 connection (fallback mode)
Using SQLAlchemy makes it possible to use any DB supported by that
library. If a DBAPI2 object, only sqlite3 is supported.
index_col string or list of strings, optional, default: None
Column(s) to set as index(MultiIndex).
columns list, default: None
List of column names to select from SQL table (only used when reading
a table).
parse_dates list or dict, default: None
- List of column names to parse as dates.
- Dict of ``{column_name: format string}`` where format string is
strftime compatible in case of parsing string times, or is one of
(D, s, ns, ms, us) in case of parsing integer timestamps.
- Dict of ``{column_name: arg dict}``, where the arg dict corresponds
to the keyword arguments of :func:`pandas.to_datetime`
Especially useful with databases without native Datetime support,
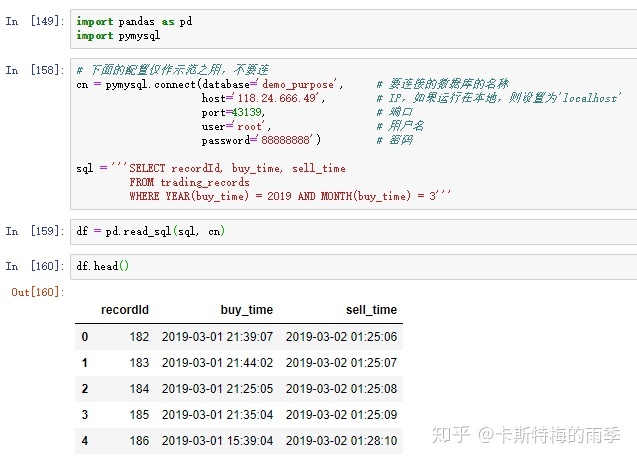
such as SQLite.以MySQL为例:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









