






1.数据预处理
准备图片数据(JPEGImages),标注文件(Annotations),以及划分好测试集训练集的索引号(ImageSets)
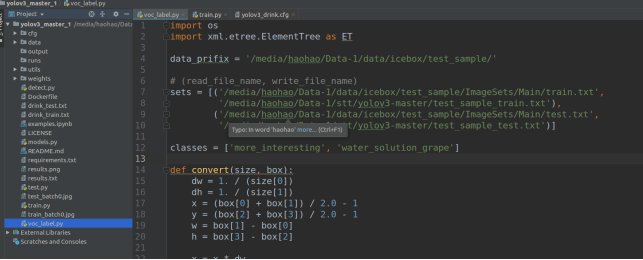
修改代码中voc_label.py文件中的路径以及类别,生成test_sample_train.txt 和test_sample_test.txt文件(训练,测试读此文件来找到图片路径),以及labels文件夹为数据的voc标注文件转换为txt文件(内容为每个图片中物体类别,以及框的归一化位置)
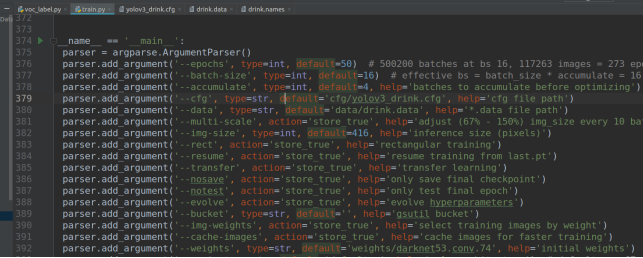
2.训练
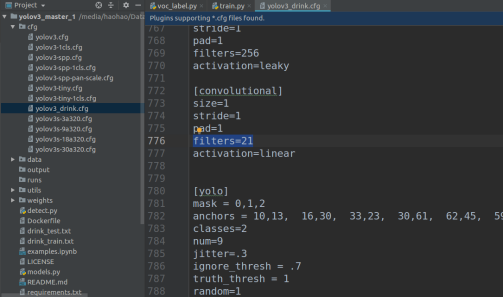
准备cfg(修改yolo层的类别classes(类别个数)和对应的filters((classes+5)× 3)如下图,data(训练测试的路径改为数据预处理生成的文件路径),names(类别名称)三个文件
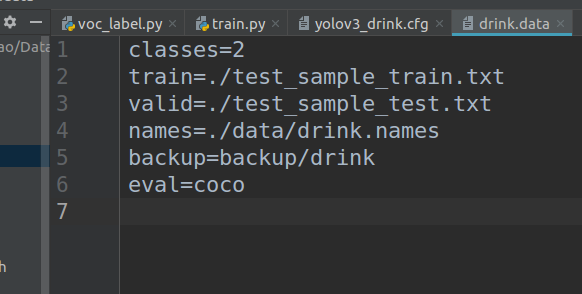
然后在train.py中修改
--epochs 所有数据共迭代多少次
--cfg 刚才的cfg文件路径
--data data文件路径
--weights 预训练模型(我会和数据一起打包发你)
命令行执行的话,也可以不修改代码中的这些位置直接输入下面命令效果一样
python train.py --epochs 100 --cfg cfg/yolov3_drink.cfg --data drink.data --weights weights/yolov3.weights
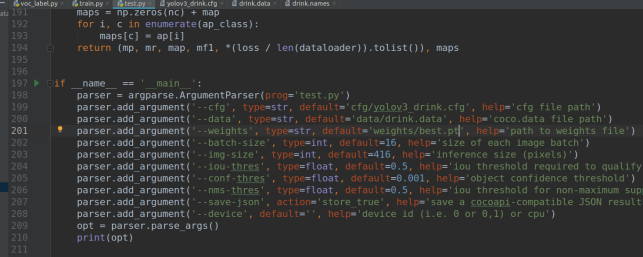
3.测试(test.py)
和训练差不多,修改 --cfg --data --weights(要测试的模型)然后run test.py
或命令行输入 python test.py --cfg cfg/yolov3_drink.data --data data/drink.data --weights weights/best.pt
运行结束会计算每个类别的map等,以及总体的精度结果
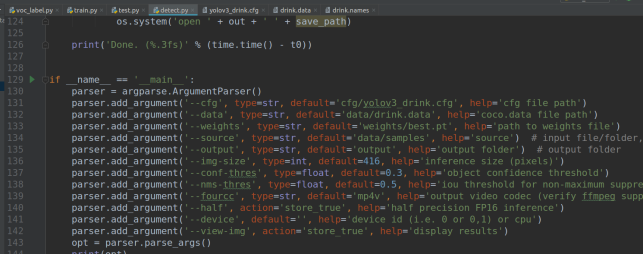
4.批量推理图片(detect.py)
--source 被推理的图片路径, --output 推理过后图片存放路径
代码,预训练模型(darknet53,yolov3两个),数据(100张voc格式标好的数据)下载链接https://download.csdn.net/download/weixin_44562081/11939321















 647
647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









