






Trick Code:https://github.com/caishiqing/joint-mrc#%E5%A4%9A%E4%BB%BB%E5%8A%A1%E8%B0%83%E5%92%8Cgithub.com
一、Trick简介
1、背景介绍
由于NLP任务很多篇章都会超过BERT的最大长度限制,因此绝大多数情况下需要做截断。但是简单的截断会有一定风险,可能会把实体 or 答案截断,又或者实体 or 答案处于片段的边缘,这样导致缺乏上下文信息。那么要怎么截断合适呢?
考虑以下情形:假设最大长度设为500,有一段篇章长度600,这时候要如何截断?常规情况下肯定就在长度500处截断呗,那么问题来了,剩下长度100的片段如何处理?直接作为第二段吗?那也太挫了,很可能实体 or 答案就被截断了(如果在500附近),或者落在第二段中导致上下文匮乏。那么我们不难想到一个策略,就是允许一定的交叉,即0-500为第一段,100-600为第二段,只要实体 or 答案不是特别长,不管是在第二段的边界上还是在第二段之外,都会落在第一段,反之一样一定落在第二段,再或许正好在中间,那么两段都包含实体 or 答案,如果是这样那再好不过,最终提取到实体 or 答案的机会会更大。
上面描述的情形可能比较简单,用规则就可以解决了,那如果长度是1100呢?500处截断,然后500-1000截断,又剩下100咋处理?可能有人立马联想到可以允许交叉啊,第三段从600到1100呗,那么第二第三段有很大的交叉自然没问题,但第一第二段之间的实体 or 答案很有可能被截断或者丢失上下文信息,总体风险还是很高。那么最好的解决方案是把第二段往前移动一些,那么问题来了,移动多少合适呢?如果移动得太多,第二第三段之间就可能会断开,那就得需要第四段,段落就会变得冗余。那你一定会想到,刚好移动到第一第二段之间的交叉和第二第三段之间的交叉相等就可以了呗。没错,这样是最好的分段设计,而且操作也很容易实现,但是问题是我们不能直接按照固定窗口大小来截取啊,这样很有可能把句子截断。
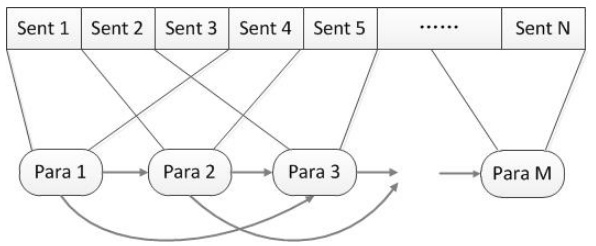
一个合理的先验假设是实体 or 答案一般不会跨句,也就是要么在一个句子内部,要么包含一个或多个完整的句子。基于这样的假设我们需要以句子为单位做规划,我们的目标是在保证覆盖全文以及段落长度限制条件的约束下,使分段结果具有最小的冗余度并且最小化丢失答案信息的风险(使答案至少落在一个段落中,而且落在越中间的位置越好)。当篇章的长度继续增加,需要更多的段落来截断时,组合的空间也会爆炸式增长,这时候就轮到我们的动态规划算法出场了。
2、基本思路:
1、将原始文本按照中英文的逗号、句号、感叹号、问号进行分割,获得多个子片段。
2、贪婪模式:使用快慢指针获取所有的子文本,满足一个子文本包含多个子片段,
一个子文本的长度小于阈值,考虑到最后的一个子片段的长度也应该属于一个合理的子文本。
3、初始构造有向无环图(候选路径)的时候,就当前子文本而言,右侧最近的有向边就是下一个子文本
(即基本路径),右侧距离最远的有向边就是当前子文本的索引加上当前子文本包含子片段的个数。
4、反向递归计算,通过构造虚拟节点N,计算当前节点所有候选路径到虚拟节点的路径和,挑选
最短的候选路径,记录路径和以及对应的候选节点。
5、正向选择0节点到N节点的最优路径。3、示意图解析如下:

二、代码解析
def split_text(text, max_len, split_pat=r'([,。]”?)', greedy=False):
"""
文本分片
将超过长度的文本分片成多段满足最大长度要求的最长连续子文本
约束条件:1)每个子文本最大长度不超过max_len;
2)所有的子文本的合集要能覆盖原始文本。
Arguments:
text {str} -- 原始文本
max_len {int} -- 最大长度
Keyword Arguments:
split_pat {str or re pattern} -- 分割符模式 (default: {SPLIT_PAT})
greedy {bool} -- 是否选择贪婪模式 (default: {False})
贪婪模式:在满足约束条件下,选择子文本最多的分割方式
非贪婪模式:在满足约束条件下,选择冗余度最小且交叉最为均匀的分割方式
Returns:
tuple -- 返回子文本列表以及每个子文本在原始文本中对应的起始位置列表
Examples:
text = '今夕何夕兮,搴舟中流。今日何日兮,得与王子同舟。蒙羞被好兮,不訾诟耻。心几烦而不绝兮,得知王子。山有木兮木有枝,心悦君兮君不知。'
sub_texts, starts = split_text(text, max_len=30, greedy=False)
for sub_text in sub_texts:
print(sub_text)
print(starts)
for start, sub_text in zip(starts, sub_texts):
if text[start: start + len(sub_text)] != sub_text:
print('Start indice is wrong!')
break
"""
# 文本小于max_len则不分割
if len(text) <= max_len:
return [text], [0]
# 分割字符串 '我爱,你中国.' -> ['我爱', ',', '你中国', '.', ''] 注意最后一个字符!
segs = re.split(split_pat, text)
# init
sentences = []
# 将分割后的段落和分隔符组合
for i in range(0, len(segs) - 1, 2):
sentences.append(segs[i] + segs[i + 1])
if segs[-1]:
sentences.append(segs[-1])
n_sentences = len(sentences)
sent_lens = [len(s) for s in sentences]
assert len(text) == sum(sent_lens)
# 所有满足约束条件的最长子片段
alls = []
for i in range(n_sentences):
length = 0
sub = []
for j in range(i, n_sentences):
if length + sent_lens[j] <= max_len or not sub:
sub.append(j)
length += sent_lens[j]
else:
break
alls.append(sub)
# 将最后一个段落加入
if j == n_sentences - 1:
if sub[-1] != j:
alls.append(sub[1:] + [j])
break
if len(alls) == 1:
return [text], [0]
if greedy:
# 贪婪模式返回所有子文本
sub_texts = [''.join([sentences[i] for i in sub]) for sub in alls]
# 每个子文本开始的位置
starts = [0] + [sum(sent_lens[:i]) for i in range(1, len(alls))]
return sub_texts, starts
else:
# 用动态规划求解满足要求的最优子片段集
# 有向图
DG = {}
# 子文本个数
N = len(alls)
for k in range(N):
tmplist = list(range(k + 1, min(alls[k][-1] + 1, N)))
# 保证了 tmplist[N-1] = [N]
if not tmplist:
tmplist.append(k + 1)
DG[k] = tmplist
routes = {}
# 0是最开始节点,N节点是虚拟的节点,N到N节点的权重为0,-1是终止
# 其中第一个位置值表示当前节点到N的‘最短路径权重和’,第二个位置值表示所有候选路径中挑选出的最短路径所确定的下一个‘节点索引’
routes[N] = (0, -1)
# N-1, N-2, ..., 0,反向计算真实节点距离虚拟节点的距离(权重)
for i in range(N - 1, -1, -1):
templist = []
# 遍历当前节点所有可能的候选节点
for j in DG[i]:
# 注意N-1到N节点的权重也为0
cross = set(alls[i]) & (set(alls[j]) if j < len(alls) else set())
# 第i个节点与第j个节点交叉度 即交叉文本长度的平方
w_ij = sum([sent_lens[k] for k in cross]) ** 2
# 第j个子问题的值, 之前已经求得
w_j = routes[j][0]
# 当前节点i离虚拟节点N的路径长度 = 当前候选路径w_ij + j离终点的最短路径
w_i_ = w_ij + w_j
templist.append((w_i_, j))
# 挑选当前节点离虚拟节点N的路径
routes[i] = min(templist)
# 首个子文本,首个子文本的开始索引
sub_texts, starts = [''.join([sentences[i] for i in alls[0]])], [0]
k = 0
while True:
k = routes[k][1]
sub_texts.append(''.join([sentences[i] for i in alls[k]]))
starts.append(sum(sent_lens[: alls[k][0]]))
if k == N - 1:
break
return sub_texts, starts













 2138
2138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









