






2023 年 4 月,Meta 发布 Segment Anything Model (SAM),号称能够「分割一切」,这一颠覆传统计算机视觉 (CV) 任务的创新性成果引起了业内的广泛讨论,并被快速应用于医疗图像分割等垂直领域的研究中。日前,SAM 再升级,Meta 开源了 Segment Anything Model 2 (SAM 2),成为计算机视觉领域的又一个划时代里程碑。
从图像分割跨越到视频分割,SAM 2 在实时提示分割方面展现出了卓越性能, 该模型将图像和视频的分割、跟踪功能引入到统一的模型中,只需在视频帧上输入提示(点击、框或掩码),就能精准识别并分割图像或视频中的任何对象,这种独特的零样本学习能力赋予了 SAM 2 极高的通用性,在医学、遥感、自动驾驶、机器人、伪装物体检测等领域展现出巨大的应用潜力。 Meta 对其充满信心:「我们相信,我们的数据、模型和见解将成为视频分割和相关感知任务的重要里程碑!」
确实如此,SAM 2 前脚上线,大家就迫不及待的用了起来,效果好到 Unbelievable!

图源:Carlos Santana
SAM 2 开源不到半个月,多伦多大学研究人员就将它用在医学图像和视频上,还顺便发表了一篇 paper!

论文原文:
https://arxiv.org/abs/2408.03322
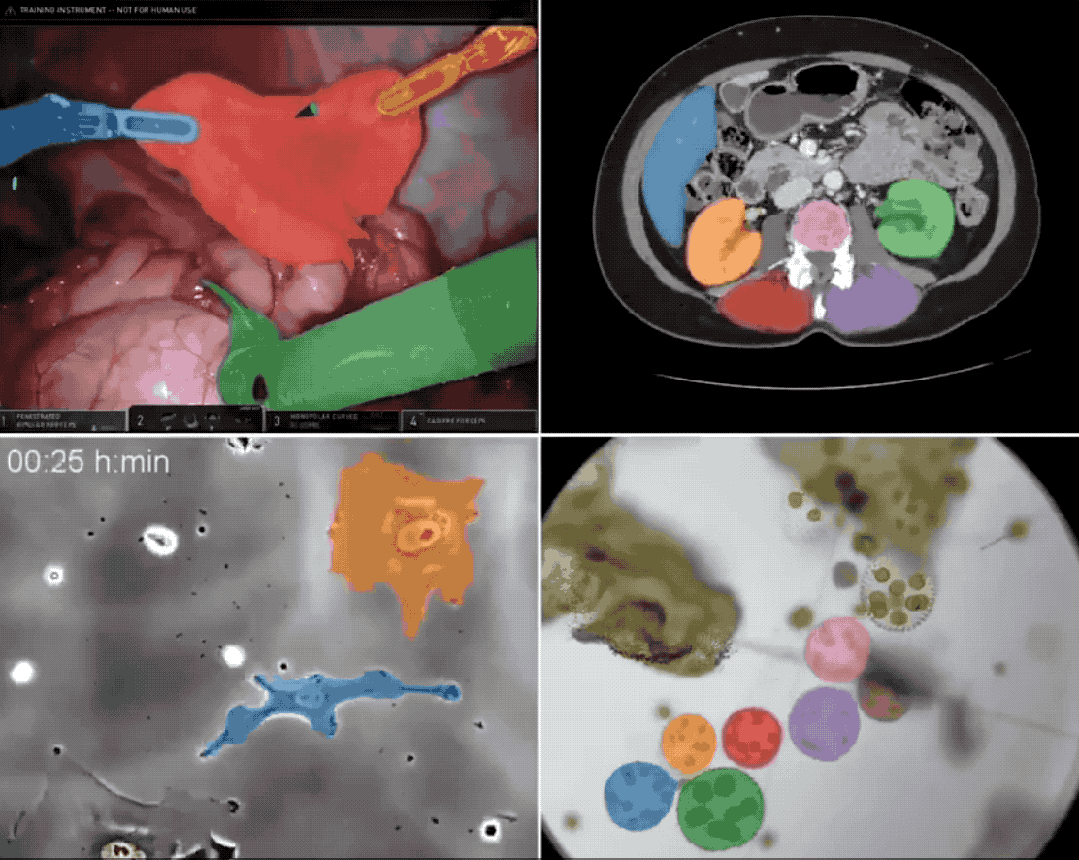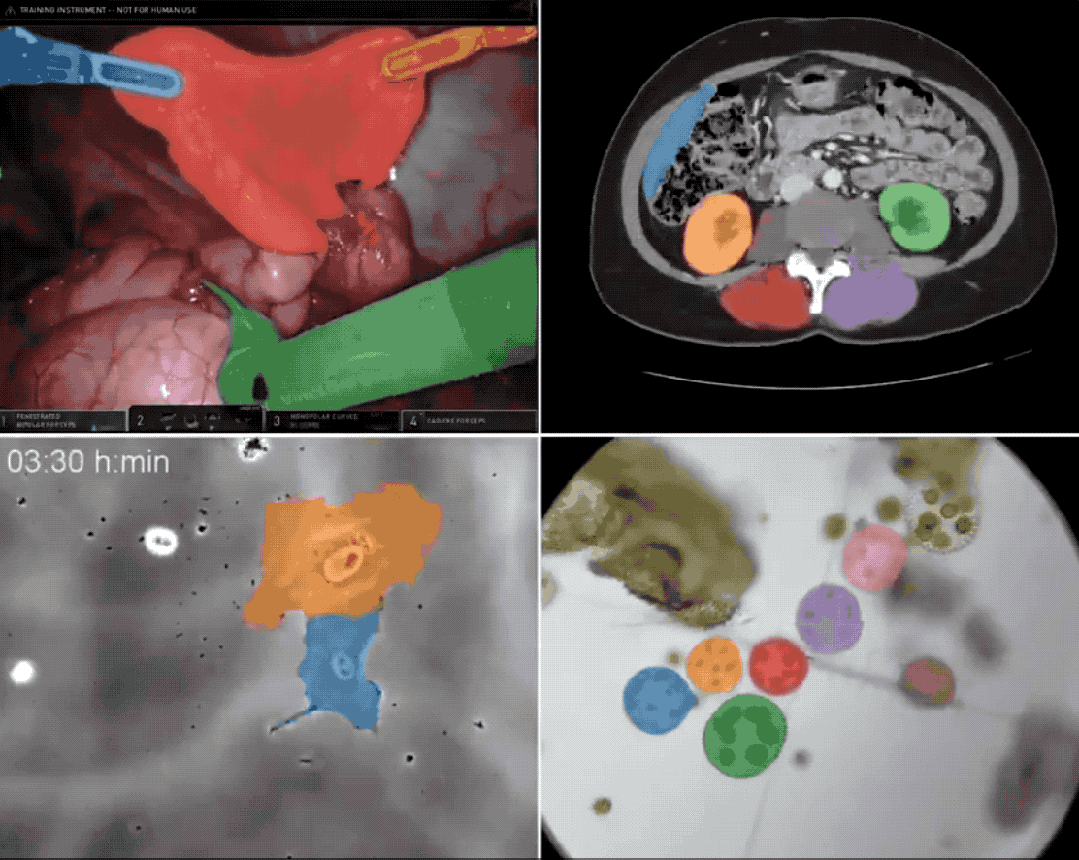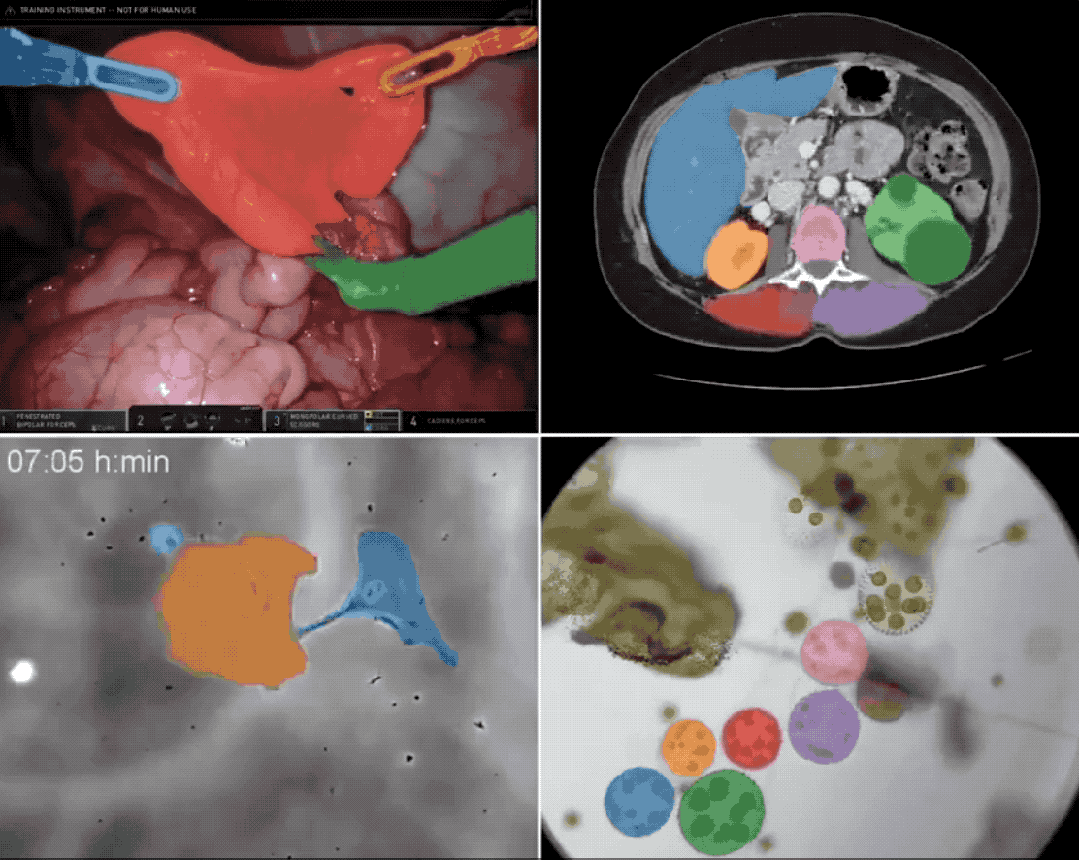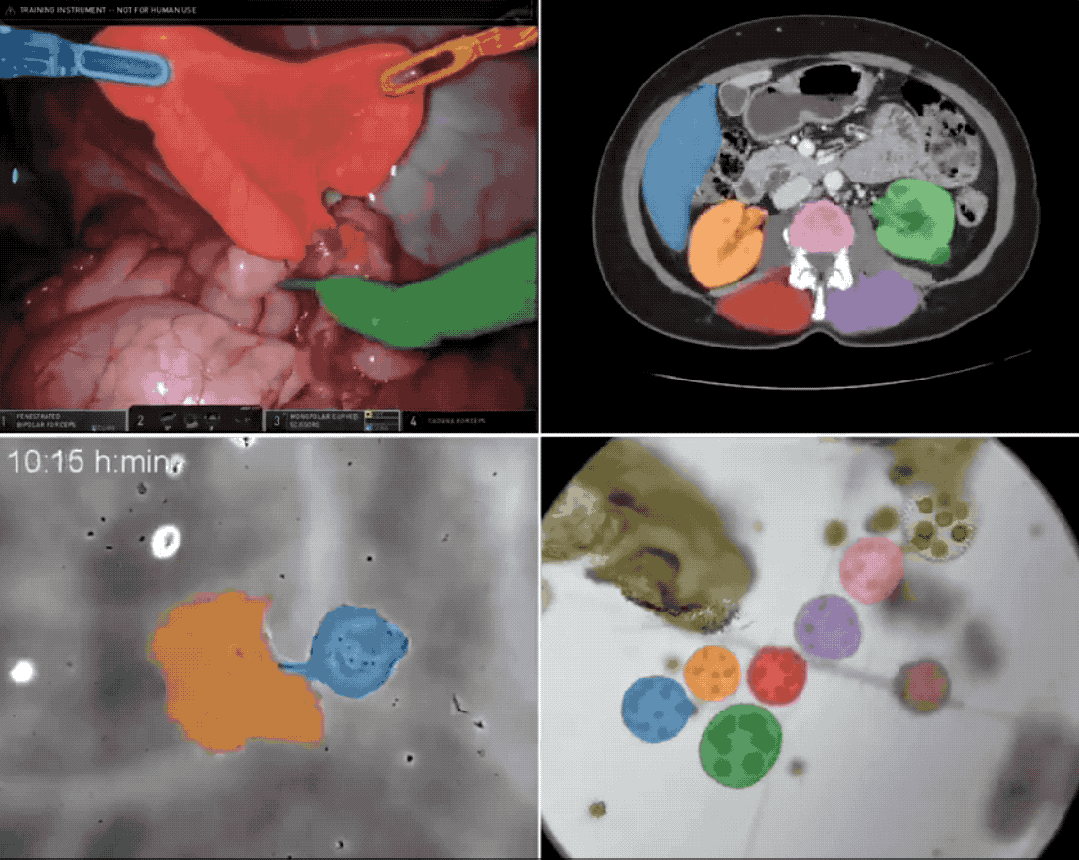
多伦多大学研究图源:Marktechpost AI Research News
模型需要数据来训练,SAM 2 也不例外。Meta 在同一时间还开源了用于训练 SAM 2 的大规模数据集 SA-V, 据悉,该数据集可用于训练、测试和评估通用对象分割模型 (generic object segmentation models),HyperAI超神经已经在官网上线了「SA-V:Meta 构建最大的视频分割数据集」,一键即可下载!
SA-V 视频分割数据集直接下载:
https://go.hyper.ai/e1Tth
更多高质量数据集下载:
https://go.hyper.ai/P5Mtc
超越现有视频分割数据集!SA-V 涵盖多主题、多场景
Meta 研究人员使用数据引擎收集了一个大型且多样化的视频分割数据集 SA-V,如下表所示,该数据集包含 50.9K 个视频,642.6K 个 masklets (由 SAM 2 辅助手动注释 191K、由 SAM 2 自动生成 452K ), 与其他常见的视频对象分割 (VOS) 数据集相比,SA-V 在视频、masklets 和 masks 数量上均有大幅提升,其标注的 masks 数量是现有任何 VOS 数据集的 53 倍, 为未来的计算机视觉工作提供了丰富的数据资源。
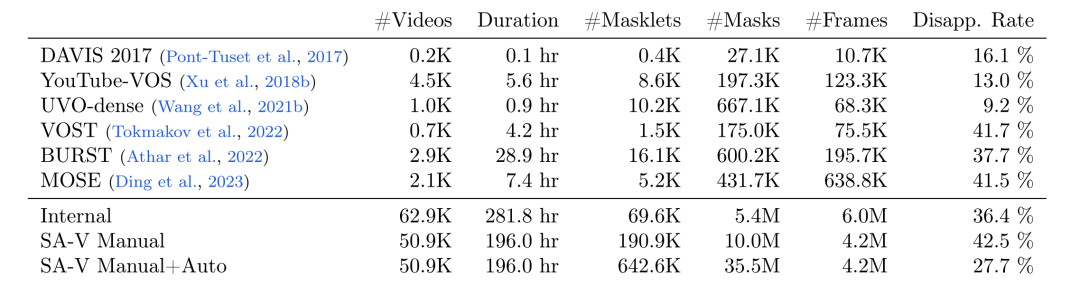
SA-V与开源VOS数据集在视频数量、时长
掩码片段数量、掩码数量、帧数量和消失率方面的比较
-
SA-V Manual 仅含手动标注的标签
-
SA-V Manual+Auto 将手动标注的标签与自动生成的掩码片段结合
据了解,SA-V 包含的视频数量超过了现有的 VOS 数据集,平均视频分辨率为 1401×1037 pixels,收集的视频涵盖各种日常场景, 包括 54% 的室内场景视频和 46% 的室外场景视频,平均时长为 14 秒。此外,这些视频的主题也多种多样, 包括位置、物体、场景等,Masks 的范围从大型物体(如建筑物)到细粒度的细节(如室内装饰)。
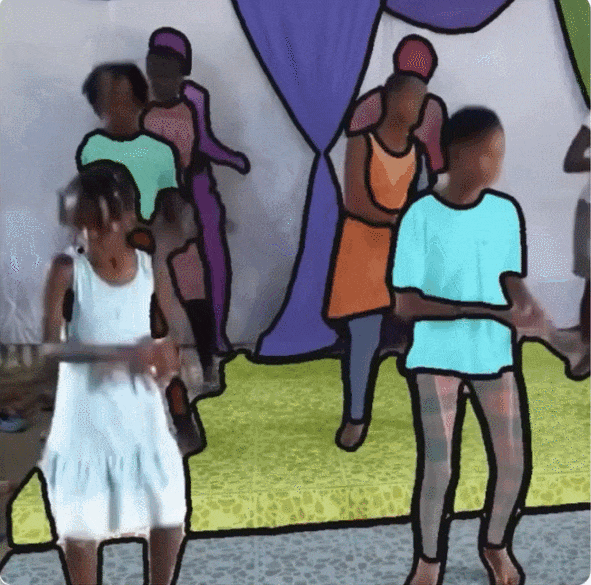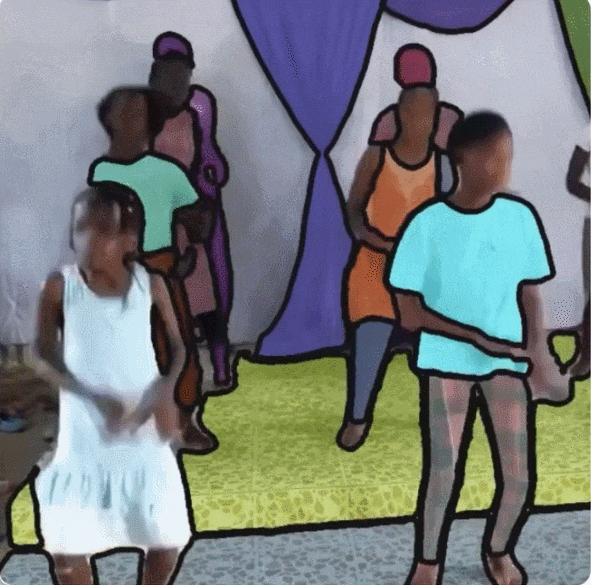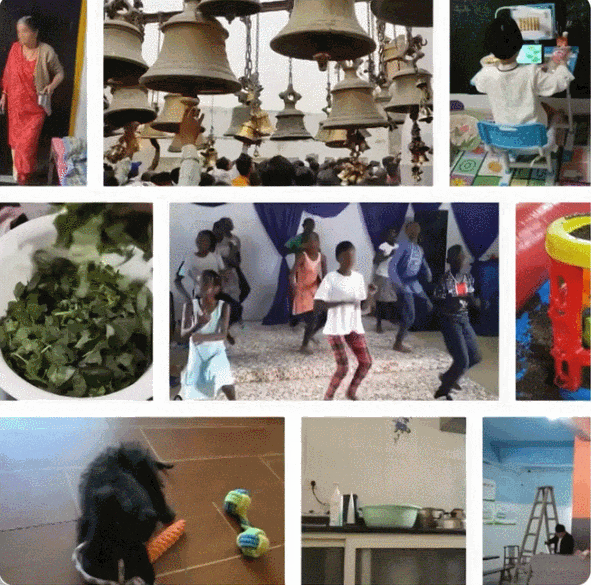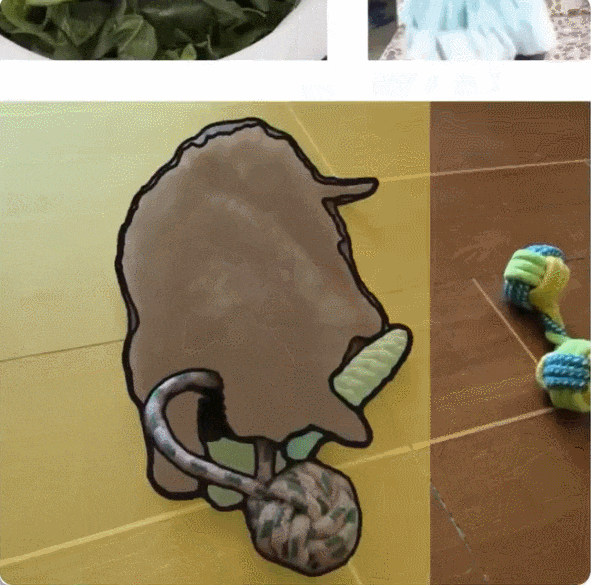
SA-V 数据集中的视频
如下图所示,SA-V 中的视频覆盖 47 个国家, 并由不同的参与者拍摄,图 a 可得,与 DAVIS、MOSE 和 YouTubeVOS 掩码大小分布相比,SA-V 小于 0.1 的归一化掩码面积 (normalized mask area) 超过 88%。
数据集分布(a)掩码片段大小分布 (b)视频的地理多样性 ©录制视频工作者的自我报告人口统计
研究人员根据视频作者及其地理位置对 SA-V 数据集进行划分,确保数据中的相似对象有最小重叠 (minimal overlap)。 为了创建 SA-V 验证集和 SA-V 测试集,在选择视频时,研究人员聚焦具有挑战性的场景,要求标注者识别快速移动、被其他物体遮挡、具有消失/重现模式的目标。最终,SA-V 验证集中有 293 个 masklets 和 155 个视频,SA-V 测试集中有 278 个掩码片段和 150 个视频。此外,研究人员还使用内部可用的授权视频数据进一步扩充训练集。
SA-V 视频分割数据集直接下载:
https://go.hyper.ai/e1Tth
以上就是 HyperAI超神经本期为大家推荐的数据集,如果大家看到优质的数据集资源,也欢迎留言或投稿告诉我们哦!
更多高质量数据集下载:
https://go.hyper.ai/P5Mtc















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









