






第一个:执行时机的差异
1.
array = [1, 8, 15]
g = (x for x in array if array.count(x) > 0)
array = [2, 8, 22]
Output:
>>> print(list(g))
[8]
2.
array_1 = [1,2,3,4]
g1 = (x for x in array_1)
array_1 = [1,2,3,4,5]
array_2 = [1,2,3,4]
g2 = (x for x in array_2)
array_2[:] = [1,2,3,4,5]
Output:
>>> print(list(g1))
[1,2,3,4]
>>> print(list(g2))
[1,2,3,4,5]
说明
在生成器表达式中, in 子句在声明时执行, 而条件子句则是在运行时执行.
所以在运行前, array 已经被重新赋值为 [2, 8, 22], 因此对于之前的 1, 8 和 15, 只有 count(8) 的结果是大于 0的, 所以生成器只会生成 8.
第二部分中 g1 和 g2 的输出差异则是由于变量 array_1 和 array_2 被重新赋值的方式导致的.
在第一种情况下, array_1 被绑定到新对象 [1,2,3,4,5], 因为 in 子句是在声明时被执行的, 所以它仍然引用旧对象 [1,2,3,4](并没有被销毁).
在第二种情况下, 对 array_2 的切片赋值将相同的旧对象 [1,2,3,4] 原地更新为 [1,2,3,4,5]. 因此 g2 和 array_2 仍然引用同一个对象(这个对象现在已经更新为 [1,2,3,4,5]).
第二个:出人意料的is
下面是一个在互联网上非常有名的例子.
>>> a = 256
>>> b = 256
>>> a is b
True
>>> a = 257
>>> b = 257
>>> a is b
False
>>> a = 257; b = 257
>>> a is b
True
说明:
is 和 == 的区别
is 运算符检查两个运算对象是否引用自同一对象 (即, 它检查两个运算对象是否相同).
== 运算符比较两个运算对象的值是否相等.
因此 is 代表引用相同, == 代表值相等. 下面的例子可以很好的说明这点,>>> [] == []
True
>>> [] is [] # 这两个空列表位于不同的内存地址.
False
256 是一个已经存在的对象, 而 257 不是
当你启动Python 的时候, 数值为 -5 到 256 的对象就已经被分配好了. 这些数字因为经常被使用, 所以会被提前准备好.
Python 通过这种创建小整数池的方式来避免小整数频繁的申请和销毁内存空间.
当前的实现为-5到256之间的所有整数保留一个整数对象数组, 当你创建了一个该范围内的整数时, 你只需要返回现有对象的引用. 所以改变1的值是有可能的. 我怀疑这种行为在Python中是未定义行为. :-)
>>> id(256)
10922528
>>> a = 256
>>> b = 256
>>> id(a)
10922528
>>> id(b)
10922528
>>> id(257)
140084850247312
>>> x = 257
>>> y = 257
>>> id(x)
140084850247440
>>> id(y)
140084850247344
这里解释器并没有智能到能在执行 y = 257 时意识到我们已经创建了一个整数 257, 所以它在内存中又新建了另一个对象.
当 a 和 b 在同一行中使用相同的值初始化时,会指向同一个对象.
>>> a, b = 257, 257
>>> id(a)
140640774013296
>>> id(b)
140640774013296
>>> a = 257
>>> b = 257
>>> id(a)
140640774013392
>>> id(b)
140640774013488
当 a 和 b 在同一行中被设置为 257 时, Python 解释器会创建一个新对象, 然后同时引用第二个变量. 如果你在不同的行上进行, 它就不会 "知道" 已经存在一个 257 对象了.
这是一种特别为交互式环境做的编译器优化. 当你在实时解释器中输入两行的时候, 他们会单独编译, 因此也会单独进行优化. 如果你在 .py 文件中尝试这个例子, 则不会看到相同的行为, 因为文件是一次性编译的.
第三个:影子数组
# 我们先初始化一个变量row
row = [""]*3 #row i['', '', '']
# 并创建一个变量board
board = [row]*3
Output:
>>> board
[['', '', ''], ['', '', ''], ['', '', '']]
>>> board[0]
['', '', '']
>>> board[0][0]
''
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['X', '', ''], ['X', '', '']]
我们有没有赋值过3个 "X" 呢?
说明:
当我们初始化 row 变量时, 下面这张图展示了内存中的情况。
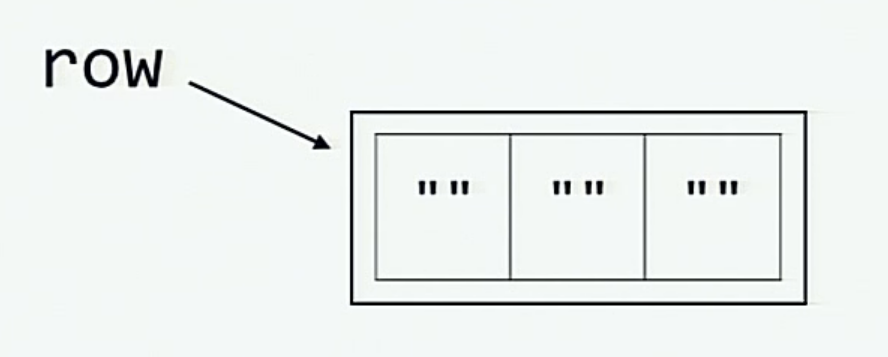
而当通过对 row 做乘法来初始化 board 时, 内存中的情况则如下图所示 (每个元素 board[0], board[1] 和 board[2] 都和 row 一样引用了同一列表.)
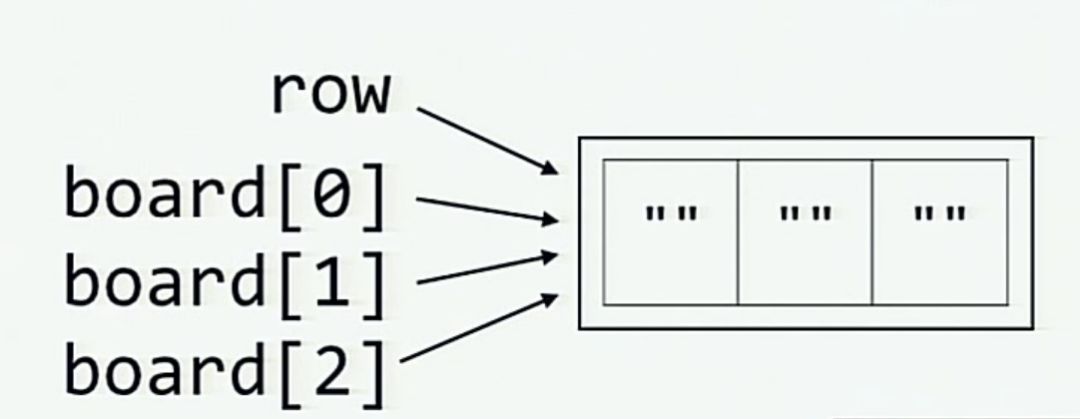
我们可以通过不使用变量 row 生成 board 来避免这种情况. (这个issue提出了这个需求.)
>>> board = [['']*3 for _ in range(3)]
>>> board[0][0] = "X"
>>> board
[['X', '', ''], ['', '', ''], ['', '', '']]
第四个:混乱的输出
#python学习群592539176
funcs = []
results = []
for x in range(7):
def some_func():
return x
funcs.append(some_func)
results.append(some_func()) # 注意这里函数被执行了
funcs_results = [func() for func in funcs]
Output:
>>> results
[0, 1, 2, 3, 4, 5, 6]
>>> funcs_results
[6, 6, 6, 6, 6, 6, 6]
即使每次在迭代中将 some_func 加入 funcs 前的 x 值都不相同, 所有的函数还是都返回6.
再换个例子
>>> powers_of_x = [lambda x: x**i for i in range(10)]
>>> [f(2) for f in powers_of_x]
[512, 512, 512, 512, 512, 512, 512, 512, 512, 512]
说明:
当在循环内部定义一个函数时, 如果该函数在其主体中使用了循环变量, 则闭包函数将与循环变量绑定, 而不是它的值. 因此, 所有的函数都是使用最后分配给变量的值来进行计算的.
可以通过将循环变量作为命名变量传递给函数来获得预期的结果. 为什么这样可行? 因为这会在函数内再次定义一个局部变量.#python学习群592539176
funcs = []
for x in range(7):
def some_func(x=x):
return x
funcs.append(some_func)
Output:
>>> funcs_results = [func() for func in funcs]
>>> funcs_results
[0, 1, 2, 3, 4, 5, 6]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









