






作为开发人员,我们经常需要设计数据库表,这个时候我们需要考虑使用字段使用哪种数据类型,以及默认值,字符集等等一些问题,我们今天就来探讨下字段为啥尽量设置为NOT NULL。
简介
如果一个字段设置为NOT NULL ,表明我们在写数据时,在没有默认值的情况下,不能写入一个空值 例如:
create table friends (
id int(3) not null,
name varchar(8) not null,
pass varchar(20) not null
);
INSERT INTO friends
VALUES (
NULL , 'simaopig', 'simaopig'
);
我们看下插入数据后的结果:
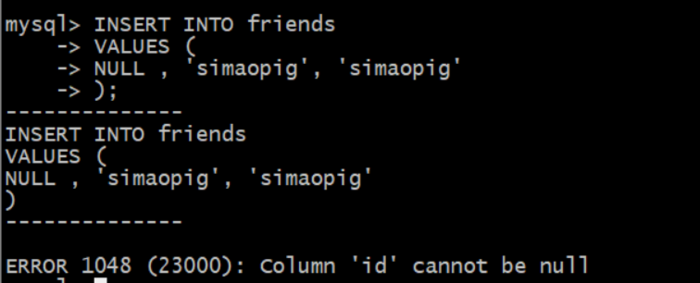
图一.png
我们发现报了一个错误:Column 'id' cannot be null,id不能为null。 当然,在列为auto_increment 或者timestamp时不会报错,我们来看下:
create table t2 (
id int(3) not null auto_increment,
days timestamp not null,
primary key(`id`)
);
insert into t2 values (NULL,NULL);
看下插入后的结果:
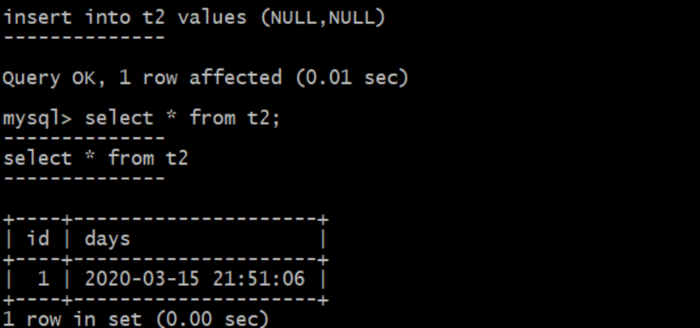
图二.png
发现可以正确插入,自增列会根据当前记录数插入对应的值,而timestamp在没有设置值的情况下会插入当前时间。
上面我们简单介绍了下关于not null ,相信大家对它也有一定的认识,接下来说下优化的问题。
字段优化
前面有说到过我们的字段尽量设置为NOT NULL,那针对这样做的原因,本人总结了以下几点。
我们的应用程序一般是不需要使用NULL值的。
如果查询中包含可为NULL的列,对MySQL来说更难优化,因为可为NULL的列会使索引、索引统计和值比较都更复杂。可为NULL的列会使用更多的存储空间,在MySQL里也需要做特殊处理。当可为NULL的列被索引时,每个索引记录需要一个额外的字节,在MyISAM里面甚至可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。
通常把可为NULL的列改为NOT NULL 带来的性能提升比较小,所以调优的时候没有必要再现有的schema中查找并修改掉这种情况,除非确定这会导致问题,但是如果计划在列上建索引,就应该尽量避免设计成可为NULL的列。
InnoDb 使用单独的位(bit)存储NULL值,所以对于稀疏数据(很多值为NULL,只有少数行的列有非NULL值)有很好的空间效率。但这一点不适用于MyISAM.
对于上面提到的几点,小伙伴们可能不是很理解,下面来做几个测试。
相关测试
1. 可为NULL的列对索引的影响
先创建两张表
staffs表; //name 设置为不能为空
CREATE TABLE staffs (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR (24) NOT NULL DEFAULT '' COMMENT '姓名',
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
pos VARCHAR (20) NOT NULL DEFAULT '' COMMENT '职位',
add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
KEY `idx_staffs_nameAgePos` (`name`)
) CHARSET utf8 COMMENT '员工记录表' ;
staffs1表;// name 默认为空
CREATE TABLE staffs1 (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR (24) COMMENT '姓名',
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
pos VARCHAR (20) NOT NULL DEFAULT '' COMMENT '职位',
add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
KEY `idx_staffs_nameAgePos` (`name`)
) CHARSET utf8 COMMENT '员工记录表1' ;
分别插入两条数据
insert into staffs values (1,'z3',22,'manager',NOW()),(2,'z4',23,'woker1',NOW());
insert into staffs1 values (1,'z3',22,'manager',NOW()),(2,'z4',23,'woker1',NOW());
那目前表里面是这个样子的:
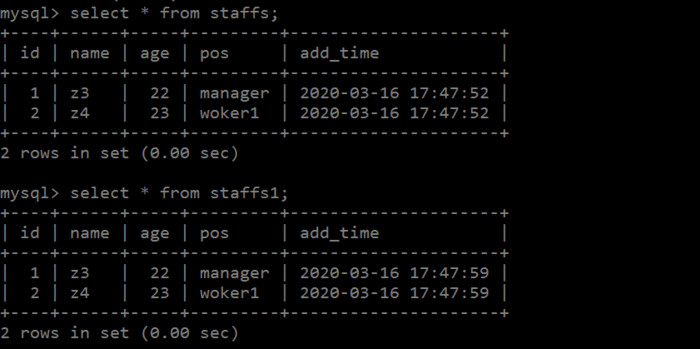
图三.png
下面我们来看下这条语句的执行计划:
explain select * from staffs where name = 'z4';
explain select * from staffs1 where name = 'z4';
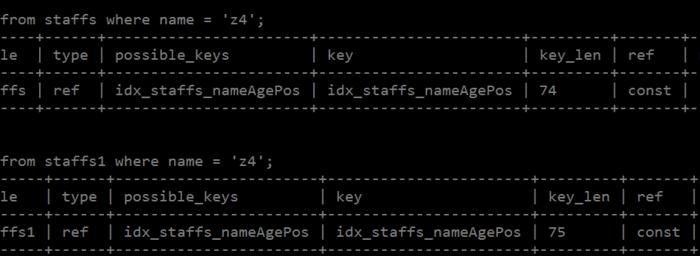
图4.png
上面这个图只截取了需要展示的部分,我们发现两个执行计划只有key_len(索引的长度)。也就是我们上面所说的:可为NULL的列被索引时会使用更多的存储空间。
2. 对统计的影响
先插入一条数据
insert into staffs1 values (3,NULL,24,'woker2',NOW());

图5.png
我们来测试几个操作:
count(*);
count(name);
count(distinct(name));
看下执行结果:
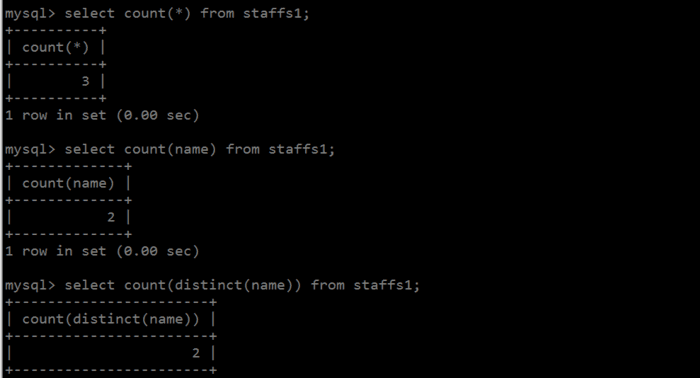
图6.png
我们发现当统计的时候count(name)和count(distinct(name))会省略值为NULL的行。
总结:
当我们的字段是经常需要使用的字段,那我们尽量设置为NOT NULL,因为当这个字段可为空的时候,并且也插入了一些空值的时候,会对程序效率和正确性产生一定的负面影响。
这里就简单展示几个例子,如有补充的,欢迎在下面给我留言。














 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









