






《智能语音》专题第二章:语音信号处理。此篇文章不会讲解傅里叶、模数、数模变化之类的技术性原理,重点在于讲解语音的场景、语音信号处理要做的事情,相关的技术手段,能够解决的问题等等。语音信号处理直接决定了语音交互入口的数据质量,我们想要有更加智能的产品,就需要对于语音信号有一定的了解,设计出真正能够落地的语音交互产品。JimmyChen:智能语音专题(一):智能语音交互的概念zhuanlan.zhihu.com
本专题之前章节参考:

人耳是天赋异禀的器官,而在语音产品中发挥“人耳”功效的是设备上的麦克风。当设备处于不同的场景中,麦克风无法做到像我们的耳朵这么灵敏,能够在鸡尾酒会效应当中自动的过滤噪声,并专注(增强)需要识别的人声。
声波通过空气传播到达了设备的麦克风上,在不同的场景(空间)会有不同的传播途径,发生折射、绕射、衍射、反射最终叠加在一起,被麦克风作为声音信号采集了进来。语音信号处理核心的作用就是识别采集的信号,增强需要识别的声音,抑制不需要识别的声音。
不同的声学场景对应不同的信号处理方案,对于语音空间的理解便于我们更好的定义声学场景,提升语音交互入口体验。
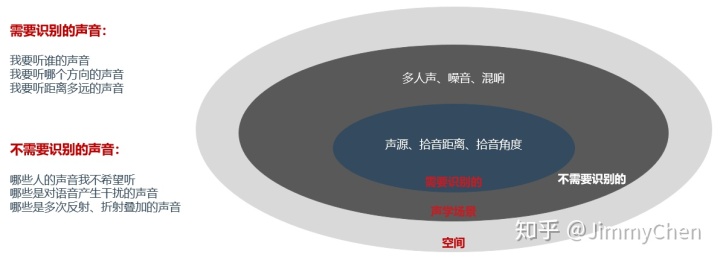
空间决定了声学场景,声学场景由需要识别的声音和不需要识别的声音组成。
需要识别的声音:
声源 – 我要听谁的声音
拾音角度 – 我要听哪个方向的声音
拾音距离 – 我要听距离多远的声音
不需要识别的声音:
多人声 – 哪些人的声音我不希望听
噪音 – 哪些是对语音产生干扰的声音
混响 – 哪些是多次反射、折射叠加的声音
空间的决定因素是多元的,声源(说话人)、设备、噪音源三者之间任何一个相对位置的变化,都会导致设备采集的声音发声变化,影响语音信号处理。在不同的环境中,我们要重点围绕相对位置(距离、角度)进行探讨,细化我们的声学场景。
以服务机器人为例,收音设备可能位于机场、餐厅、商场、酒店、营业厅、医院等等,在不同的环境中,我们重点要围绕着相对位置和噪音类型来探讨。

- 相对位置:以设备为中心,说话人应该在设备的哪个位置才能被听到,距离多少,角度多少;如果多个人在同一个角度,同一个区域怎么区分;噪音主要来自哪几个方向,大概有多少强度,是否应该抑制;在实际语音交互中,说话人和设备之间是否一定时间内相对静止,距离和角度,还有噪音有没有发生大的变化。
- 噪音类型:噪音非常的广泛,对于语音识别产生干扰的声音都可以称为噪音,不同的场景下,噪音的种类也是不同的;
人群噪音:人类的非语音声音、脚步声、咳嗽声、笑声、喝水声、呼吸、拍手、打喷嚏
环境噪音:门转动的声音、敲击声、行李箱拖动声、风声、雨声、汽车鸣笛声
空间变化:50平米的展厅,100平米的展厅,50平的玻璃会议室,是否堆满杂物,是否空旷,噪音是不同的。自噪音:设备自己发生的声音也需要关注,散热器的声音(风扇)、电流声、关节转动声音、播报声等。
定义清楚声学场景之后,那我们怎么进行具体的信号处理操作了,或者说怎么将我们定义好的空间、角度、距离、噪音等等信息告知我们的设备然后进行对应的增强或抑制呢。
这时候我们就需要麦克风阵列的介入,传统的单麦克风是无法获得声学信号的空间信息的,但是将多个麦克风通过阵列的方式组合分布,因为不同麦克风收到声波的差异性延时,我们就能够计算出整个音频的空间信息。麦克风阵列通过多个麦克风将空间对应的分割,理论上,麦克风越多,空间分割越细,信号处理的准确率和精度就越高。
麦克风阵列通常分为:线性方案、环形方案、球形方案,不规则形状,根据不同的行业和需求,进行不同的选择。(以下示意图为二维空间,真实世界是一个三维空间,不同的阵列算法空间分割方式不同)。
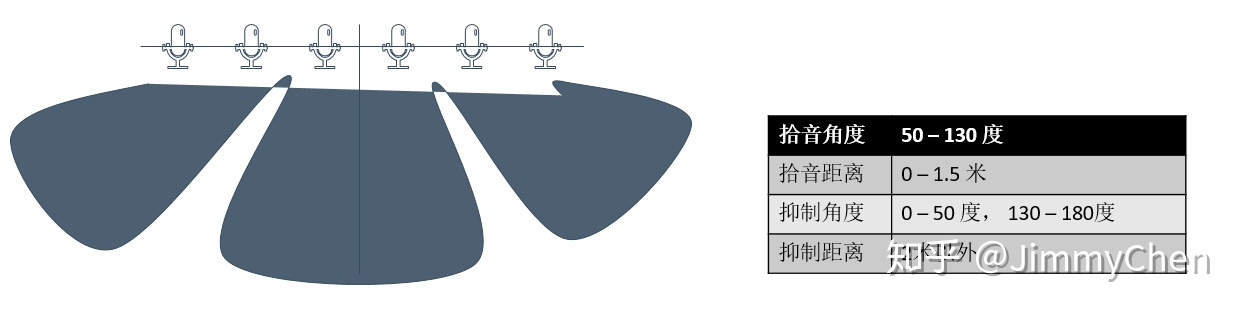
目前的麦克风阵列厂商为了适配不同的场景提高复用率,通常同一款产品默认都支持多种拾音模式。我们在做麦克风阵列选型时,除了满足语音交互时的声学场景规格,也应当调研该麦阵是否还支持更多可扩展的拾音模式。例如,某款麦阵的拾音规格:
支持唤醒拾音模式、定向拾音模式和全向拾音模式(也称之为通话模式)三种唤醒
模式。唤醒拾音模式即每次说话前需对麦克风进行唤醒,之后麦克风才可以拾取声源所
在方向上的声音;定向拾音模式即开发者可随时指定特定的麦克风进行拾音,使设备达
到跟踪声源进行拾音的效果,主要适用于机器人等场景;全向拾音模式即麦克风阵列无
需唤醒,可拾取任意方向上声源的声音,可适用于通话、会议等场景。
很多服务机器人除了进行语音识别,通常还需要支持双向对讲和人工坐席等模式,例如近期大大量上岗的问诊机器人,医生可以远程通过机器人查看隔离病房的病人状态进行音视频通话,能够视觉和听觉感知整个外部环境,远程遥控机器人行走等等需求。语音识别是要做定向拾音,抑制环境噪音;而通话和会议则是要全向拾音,尽可能听到所有的声音,本质上是两个互斥的需求,所以就一定要麦克风阵列能够同时支持至少两路的不同拾音模式。
上面部分强调的是设备(麦克风阵列)所处于的外部空间,接下来我们还要强调下设备的内部空间(腔体)。声音在传播到麦克风的时候,也会在腔体中不断的反射,一个小小的腔体空间同样会对语音信号质量产生影响,对于设备的腔体设计,需要有基本要求。
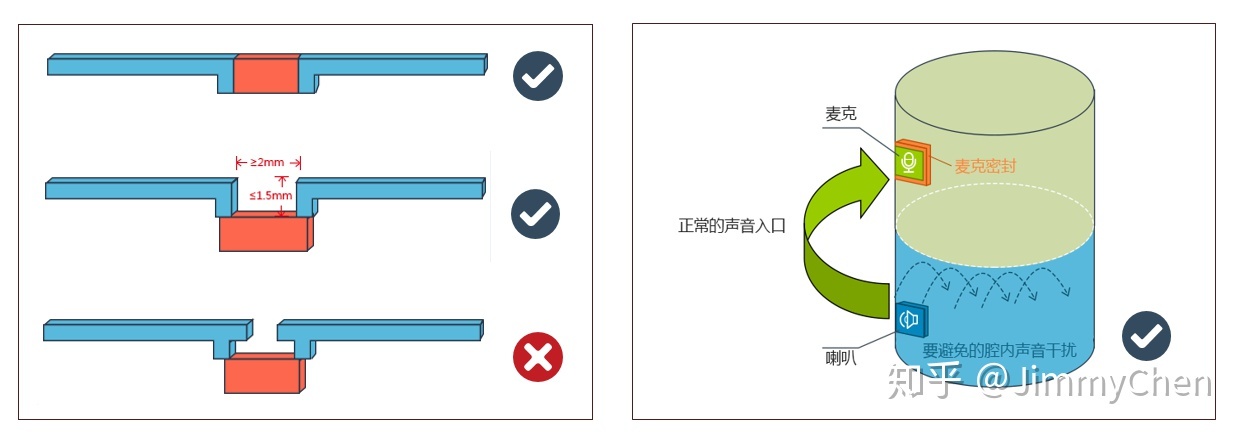
麦克风阵列厂商通常会要求提供需要集成设备的腔体设计,优化拾音算法,同时对于产品的结构设计也会提一些集成要求,以期达到最好的语音效果(产品经理应当多同麦阵供应商、硬件和结构沟通,确保最佳效果)。
1. 人声能直达每个麦克,避免掩蔽效应,即产品正常使用场景下,保证声源的直达声(非反射声)到达每个麦克的机会是均等的;
2. 声音到达麦克风的路径尽可能短、宽(增加一些缓存胶垫,避免麦克风震动),麦克能直接在表面最好;
3. 声音路径内不要存在任何空腔,对于紧贴面壳安装方式,震膜和壳体内壁不要有缝隙(完全封闭);
4. 避免结构内声音传播,即喇叭的声音不能在结构内泄露到麦克,只能通过结构外的空气传播到麦克,建议喇叭和麦克风放在不同腔体内或选用性能好的密封材料对腔体内麦克部分进行密封;
5. 特别注意,除了要注意麦克风和扬声器之间的距离,麦克风与麦克风之间的距离,还有麦克风阵列的麦克风是要固定在同一个水平面上的,这一点也是非常重要的;
大家是否还记得在第一章节讲到语音交互流程时,信号处理的声音除了各个麦克风采集到的原始信号,还有一个回路信号,这个具体指的什么?

回路信号用作进行回声消除(AEC Acoustic Echo Cancellation),以之前提到的用户问话“明天出门要带伞吗”为例,我们的设备正在播报,用户同时说“后天呢”设备采集到的音频信号有哪些?
1. 语音“后天呢”的音频
2. 正在播报“成都明天晴,气温5-10℃,不要带伞哦”的音频
3. “成都明天晴,气温5-10℃,不要带伞哦”的音频回声 *N
4. 环境噪音、脚步声、机器轰鸣声、喧闹声
这里需要回顾一个物理现象“声音(声波)的反射”及“混响”。混响,简单的描述就是,“发出的声音”在一个空间中,会不断反射(不止一次),然后还会和其他的声音混和在一起,再被麦克风采集回来;查看采集上来的声音,会发现,会有很多次“发出的声音”的“回声”,人耳要区分清楚原声和回声,两组声音之间需要有150ms左右的间隔,小于这个间隔,人耳虽然无法区分出来,是这些回声是存在的,而且会干扰我们“信号处理”。
这些声音信号混合在一起,其中1-3都是语音,设备到底应该把哪个声音提取出来?处理不好就是“乱说话,不听话”:设备听到了自己的声音,然后开始不断的自问自答,往复循环下去;设备只听到自己的声音,说话人反而听不到。而AEC则是在信号处理中将设备“发出的声音”进行消除,依赖于设备给出一个参考的回路语音信号。
要做好回声消除,保障以下两点很重要。
- 信号真实性:有的音箱类产品,在设计上,会有一个硬件EQ模块,“EQ”从本质上来说,是对音频的二次处理。播放的信号会经过原有的硬件进行EQ处理,再播放出来,这个时候,回路信号就和真正播放出来的音频信号不一致了,便失去了“真实性”,那么AEC效果可能就会大打折扣。
- 扬声器位置:声音的空间给彻底改变了,不同的空间,声音的传播模型都不完全一样。很多设备最开始在实验室调试AEC效果不错,但是放到客户那演示,接了个外放或者换了一个空旷的玻璃会议室,整体效果可能会变差。例如,智能机顶盒可能存在类似的问题,盒子自己是不发声的,是由电视来发声的,盒子和电视扬声器的摆放位置不同,可能对于语音的效果都会有强弱不等的影响。
说完了外部空间和内部空间,再说说噪音部分。目前的麦克风阵列算法中通常基于深度学习多层神经网络训练,只要能够较为清晰的定义清楚声学场景,主要的噪音源,都能够比较好的抑制各种环境噪音或者设备本体噪音。
语音信号处理基于麦克风阵列将音频信号进行二次加工,通常涉及多个处理能力。单一场景,单一声源、单一噪音可能表现良好,但是我们通常都要处理各种组合场景,需要大量的特殊案例,大量测试。整个调试过程被称为Tuning,这是50%的科学 + 50%的艺术,找到平衡点。
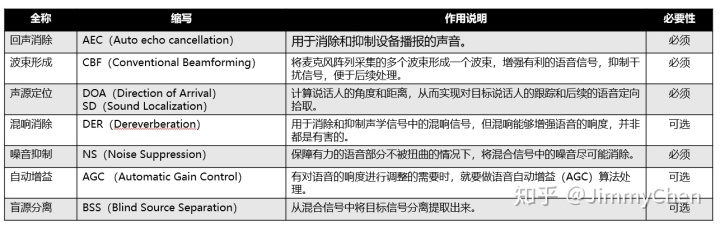
我们在用微信发送语音时,首先要“按住说话”开始说话代表语音“开头”,完毕之后“松开结束”代表语音“结尾”,最后微信会将你的语音发送给对方。而我们语音设备只要上电,一般都需要长时监听,需要我们的麦克风阵列一直处理收到的音频信号,音频信号中有语音信号,也有各种各样的空白音频信号。语音信号处理中,我们如何判断音频中哪一段才是真正的语音,需要进行识别。
Voice Activity Detection 语音活性检测(VAD)也被称为语音端点检测,基本原理是判断一个区间内的音频(区间被称为一个“语音帧”),是有效语音,还是无效语音。通过连续的检测多帧,就能判断出语音的“开头”(从无效到有效)和“结尾”(从有效到无效),完成语音的切割。VAD的准确性和语音信噪比正相关,安静的环境准确性更高,也是为何需要麦阵降噪处理后的信号再做VAD。
语音的“开头“相对好判断,但是语音的”结尾”怎么判断了?我们都知道,日常交流的时候,通常的方式是等对方把话说完。VAD也是采用同样的方式,当“有效语音”完成之后,等一小段时间确认后续确实没有新的“有效语音”了,那之前的“有效语音”就是语音的结尾。
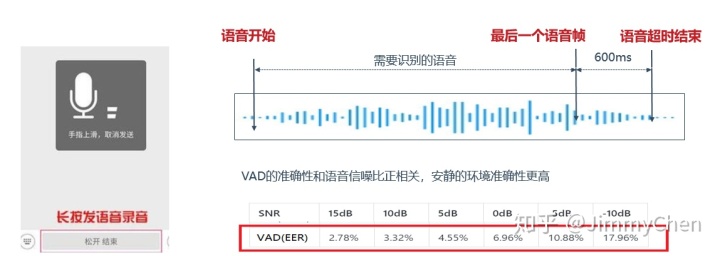
这个等待时间被称为VAD超时,行业一般情况下VAD超时时间为450-800ms,比如讯飞的VAD超时默认为800ms。VAD时间过长,会导致语音交互的时延变长,影响体验;相反VAD时间过短,会导致我们的语速稍慢时语音就被截断了,同样的影响交互体验。如果我们有办法知道用户的下一句话会说什么,在不同的应用场景中,VAD超时可以根据具体业务进行设定。比如做导航、音乐控制等等快速简短的指令时,超时可以设置为600ms,而做语音听写,发送短信之类的业务,超时时间应当尽量长一些,800ms甚至以上。
补充一个概念,叫做语音交互的预判性。语音交互同传统的界面图形交互不同,GUI强视觉的能够明确的引导甚至限制用户做哪些操作,但是VUI是弱视觉完全开放的,我们无法限制用户怎么同设备对话,给出什么样的语音请求。所以我们要想办法通过问答句式或者界面引导用户给出语音请求,这样能够显著的提高交互效率和体验,后面语音交互设计环节可以深入介绍。
通过以上步骤,我们完成了语音的信号处理,保障最终进行识别的音频是:经过增强的,抑制噪音后的,需要识别的,完整用户语音。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









