






在我们之前所提出的算法中,不管是MC还是TD,一般都遵循广义策略迭代GPI,而在GPI中,为了求得最优策略,在策略提升的时候我们总是使得改进后的策略相对于估计的值函数是贪婪的,所谓贪婪就是最大化的操作。比如Q学习中我们让目标策略的动作为当前状态下动作值函数取得最大的动作。在Sarsa算法中同样也使用了最大化操作。而这个最大化操作会导致严重的正向偏差,我们称之为最大化偏差(maximization bias)。
怎么理解这个正向偏差呢?假设对于一个状态
例6.7:最大化偏差举例
考虑如下图所示的一个MDP问题:
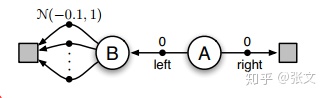
智能体总是从状态A开始,然后具有左右两个动作。向右立马进入终止态并且获得0的回报。向左进入状态B,在状态B有很多个动作,执行任何一个动作都会进入终止并且得到一个服从
对于这个问题,显然
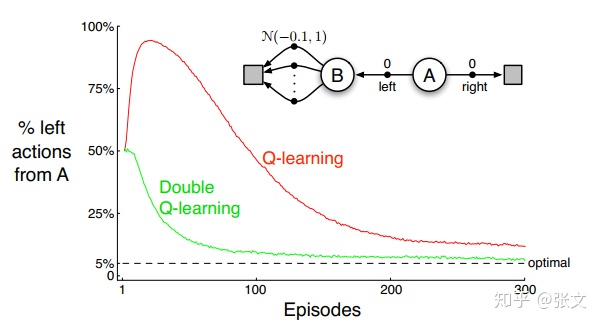
如上图所示,我们会发现在开始阶段,Q学习算法选择向左动作的概率竟然高达90%多,尽管最后收敛到最优。注意这里收敛的时候依然有5%的概率选择向左的动作,这是因为我们采用的是
既然出现这种正向偏差,有没有什么方法能够避免呢?看到上图你肯定知道方法是有的,而且就叫做double-Q学习,那么它的原理是什么呢?
如果我们在考察一下Q学习算法,为了得到更新目标
这种思想推广到Q学习算法,就是double-Q 学习,它的更新公式如下:
我们以0.5的概率使用上式更新
整个double Q学习算法伪代码如下:

这两节讲的Q学习算法和double-Q 学习算法都是表格式的。如果我们将其拓展到高维空间,然后用一个近似值函数来替代表格,而如果恰巧这个近似值函数的形式是一个神经网络,我们就得到了DQN和Double-DQN,他们的核心更新步骤是一模一样的。所以说创新也是基于经典。掌握好基础,融会贯通,再适当的做些变通,你就发现创新也不是那么难。我想这也是我坚持写这个笔记的原因。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









