






Mysql根据时间查询日期的优化技巧
例如查询昨日新注册用户,写法有如下两种:
EXPLAIN
select * from chess_user u where DATE_FORMAT(u.register_time,'%Y-%m-%d')='2018-01-25';
EXPLAIN
select * from chess_user u where u.register_time BETWEEN '2018-01-25 00:00:00' and '2018-01-25 23:59:59';
register_time字段是datetime类型,转换为日期再匹配,需要查询出所有行进行过滤。而第二种写法,可以利用在register_time字段上建立索引,查询极快!


附上日期转换函数
DECLARE yt varchar(10); #昨天
DECLARE yt_bt varchar(19); #昨天开始时间
DECLARE yt_et varchar(19); #昨天结束时间
#设置变量
SET yt=DATE_FORMAT(DATE_ADD(now(),INTERVAL -1 day),'%Y-%m-%d');
SET yt_bt=DATE_FORMAT(DATE_ADD(now(),INTERVAL -1 day),'%Y-%m-%d 00:00:00');
SET yt_et=DATE_FORMAT(DATE_ADD(now(),INTERVAL -1 day),'%Y-%m-%d 23:59:59');
总结
以上所述是小编给大家介绍的Mysql根据时间查询日期的优化技巧,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
mysql处理海量数据时的一些优化查询速度方法
简单谈谈MySQL优化利器-慢查询
MySQL多表链接查询核心优化
Mysql使用索引实现查询优化
Mysql查询语句优化技巧
mysql关联子查询的一种优化方法分析
时间: 2018-02-27
索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存)等等.这里的记录的优化技巧更适用于开发人员,都是从网络上收集和自己整理的,主要是查询语句上面的优化,其它层面的优化技巧在此不做记录. 查询的开销指标: 执行时间 检查的行数 返回的行数 建立索引的几个准则: (1).合理的建立索引能够加速数据读取效率,不合理的建立索引反而会拖慢数据库的响应速度. (2).索引越多,更新数据的速度越慢. (3).尽量在采用MyIsam作为引擎的时候使用索引(因为My
索引的目的在于提高查询效率,可以类比字典,如果要查"mysql"这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的. 1.索引的优点 假设你拥有三个未索引的表t1.t2和t3,每个表都分别包含数据列i1.i2和i3,并且每个表都包含了1000条数据行,其序号从1到1000.查找某些值匹配的数据行组合的查询可能如下所示: SELECT t1.i1, t2.i2, t3.i3 FROM t1, t2,

本文实例讲述了mysql关联子查询的一种优化方法.分享给大家供大家参考,具体如下: 很多时候,在mysql上实现的子查询的性能较差,这听起来实在有点难过.特别有时候,用到IN()子查询语句时,对于上了某种数量级的表来说,耗时多的难以估计.本人mysql知识所涉不深,只能慢慢摸透个中玄机了. 假设有这样的一个exists查询语句: select * from table1 where exists (select * from table2 where id>=30000 and table1.u
由于在参与的实际项目中发现当mysql表的数据量达到百万级时,普通SQL查询效率呈直线下降,而且如果where中的查询条件较多时,其查询速度简直无法容忍.曾经测试对一个包含400多万条记录(有索引)的表执行一条条件查询,其查询时间竟然高达40几秒,相信这么高的查询延时,任何用户都会抓狂.因此如何提高sql语句查询效率,显得十分重要.以下是网上流传比较广泛的30种SQL查询语句优化方法: 1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询
概述 在一般的项目开发中,对数据表的多表查询是必不可少的.而对于存在大量数据量的情况时(例如百万级数据量),我们就需要从数据库的各个方面来进行优化,本文就先从多表查询开始.其他优化操作,后续另外更新,敬请关注. 数据背景 现假设有一个中学学校,学校中的年级有一年级.二年级.三年级,每个年级有两个班级.分别为101.102.201.202.301.302. 现在我们要为这个学校建立一个考试成绩统计系统.为此,我们对数据库的设计画了如下ER图: 根据ER图,我们设计了数据表,结构如下: class
慢查询 首先,无论进行何种优化,开启慢查询都算是前置条件.慢查询机制,将记录过慢的查询语句(事件),从而为DB维护人员提供优化目标. 检查慢查询是否开启 通过show variables like 'slow_query_log'这条语句,可以找到慢查询的状态(On/Off). 开启慢查询 本文使用的MySQL版本:MariaDB - 10.1.19,请注意,不同版本的MySQL存在差异. 在[mysqld]下加入: [mysqld] port= 3306 slow-query-log=1 #
众所周知,InnoDB采用IOT(index organization table)即所谓的索引组织表,而叶子节点也就存放了所有的数据,这就意味着,数据总是按照某种顺序存储的.所以问题来了,如果是这样一个语句,执行起来应该是怎么样的呢?语句如下: select count(distinct a) from table1; 列a上有一个索引,那么按照简单的想法来讲,如何扫描呢?很简单,一条一条的扫描,这样一来,其实做了一次索引全扫描,效率很差.这种扫描方式会扫描到很多很多的重复的索引,这样说的话优
我们在设计表的时候,如果碰到需要设置int(整型)的时候,通常会按照惯例(大家都这样写)设置成int(11).那么这里为什么是11呢?代表的又是什么呢? 以前我一直以为这里是在限制int显示的宽度,后来仔细研究和通过上网查询发现,事实并不是那样的. 确切的来说,这里的"宽度"只是一个"预期值",它所代表的仅仅是你在设计数据表结构时,想让该列日后显示的值宽度为多少,但是具体存入值的宽度多少不会受任何影响. 当然,它的作用不仅如此,在存入数据的时候,还是有一定区别的,这

摘要 面试时,交流有关mysql索引问题时,发现有些人能够涛涛不绝的说出B+树和B树,平衡二叉树的区别,却说不出B+树和hash索引的区别.这种一看就知道是死记硬背,没有理解索引的本质.本文旨在剖析这背后的原理,欢迎留言探讨 问题 如果对以下问题感到困惑或一知半解,请继续看下去,相信本文一定会对你有帮助 mysql 索引如何实现 mysql 索引结构B+树与hash有何区别.分别适用于什么场景 数据库的索引还能有其他实现吗 redis跳表是如何实现的 跳表和B+树,LSM树有和区别呢 解析 首先
简介 MySQL通过复制(Replication)实现存储系统的高可用.目前,MySQL支持的复制方式有: 异步复制(Asynchronous Replication):原理最简单,性能最好.但是主备之间数据不一致的概率很大. 半同步复制(Semi-synchronous Replication):相比异步复制,半同步复制牺牲了一定的性能,提升了主备之间数据的一致性(有一些情况还是会出现主备数据不一致). 组复制(Group Replication):基于Paxos算法实现分布式数据复制的强一致
我有一张这样的产品零件表: 部分 part_id part_type product_id -------------------------------------- 1 A 1 2 B 1 3 A 2 4 B 2 5 A 3 6 B 3 我想要一个返回如下表格的查询: product_id part_A_id part_B_id ---------------------------------------- 1 1 2 2 3 4 3 5 6 在实际实施中,将有数百万个产品部件 最佳答案
检索性能从快到慢的是(此处是听人说的): 第一:tinyint,smallint,mediumint,int,bigint 第二:char,varchar 第三:NULL 解释(转载): 整数类型 1.TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT,分别用8,16,24,32,64存 2.整数都有UNSIGNED可选属性 (拿tinyint字段来举例,unsigned后,字段的取值范围是0-255,而signed的范围是-128 - 127. 那么如果我们在明确不需要
一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善.这篇文章主要谈谈MySQL数据库在发展周期中所面临的问题及优化方案,暂且抛开前端应用不说,大致分为以下五个阶段: 阶段一:数据库表设计 项目立项后,开发部门根据产品部门需求开发项目. 开发工程师在开发项目初期会对表结构设计.对于数据库来说,表结构设计很重要,如果设计不当,会直接影响到用户访问网站速度,用户体验不好!这种情况具体影响因素有很多,例如慢查询(低效的查询语句).没有适当建立索引.
1.COUNT(*)和COUNT(COL) COUNT(*)通常是对主键进行索引扫描,而COUNT(COL)就不一定了,另外前者是统计表中的所有符合的纪录总数,而后者是计算表中所有符合的COL的纪录数.还有有区别的. 优化总结,对于MyISAM表来说: 1.任何情况下SELECT COUNT(*) FROM tablename是最优选择: 2.尽量减少SELECT COUNT(*) FROMtablename WHERE COL = 'value' 这种查询: 3.杜绝SELECT COUNT(
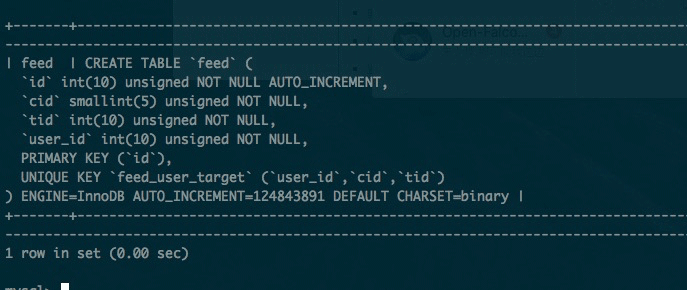
前言: 收到疯狂的慢查询及请求超时报警,通过metrics分析出来自mysql请求的异常,cli -> show proceslist 看到很多慢查询. 先前该sql是没有的,后面因为数据量的增长才出现了这问题. 虽然feeds表大到一个亿,但因为feeds流信息有近期热的特征,所以不是因为 innodb_buffer_pool_size 低效引起的io频繁. 后来经过进一步explain执行计划分析得出了原因,mysql查询优化器选择了他认为高效的索引. mysql查询优化器大多数情况是靠谱的















 2533
2533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









