






说这四种网格搜索、随机搜索、贝叶斯优化和Hyperband
一、网格搜索(Grid Search)
网格搜索是暴力搜索,在给定超参搜索空间内,尝试所有超参组合,最后搜索出最优的超参组合。sklearn已实现该方法,使用样例如下:
sklearn.model_selection.GridSearchCV[1]的重要参数说明:
- estimator: scikit-learn模型。
- param_grid: 超参搜索空间,即超参数字典。
- scoring: 在交叉验证中使用的评估策略。
- n_jobs: 并行任务数,-1为使用所有CPU。
- cv: 决定采用几折交叉验证。
二、随机搜索(Randomized Search)
随机搜索是在搜索空间中采样出超参组合,然后选出采样组合中最优的超参组合。随机搜索的好处如下图所示:
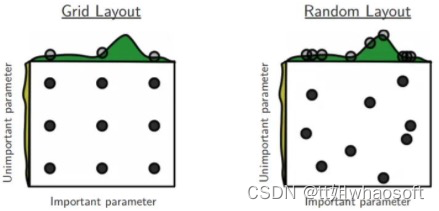
图1: 网格搜索和随机搜索的对比[2]
解释图1,如果目前我们要搜索两个参数,但参数A重要而另一个参数B并没有想象中重要,网格搜索9个参数组合(A, B),而由于模型更依赖于重要参数A,所以只有3个参数值是真正参与到最优参数的搜索工作中。反观随机搜索,随机采样9种超参组合,在重要参数A上会有9个参数值参与到搜索工作中,所以,在某些参数对模型影响较小时,使用随机搜索能让我们有更多的探索空间。
同样地,sklearn实现了随机搜索[3],样例代码如下:
相比于网格搜索,sklearn随机搜索中主要改变的参数是param_distributions,负责提供超参值分布范围。
三、贝叶斯优化(Bayesian Optimization)
我写本文的目的主要是冲着贝叶斯优化来的,一直有所耳闻却未深入了解,所以我就来查漏补缺了。以下内容主要基于Duane Rich在《How does Bayesian optimization work?》[4]的回答。
调优的目的是要找到一组最优的超参组合,能使目标函数f达到全局最小值。
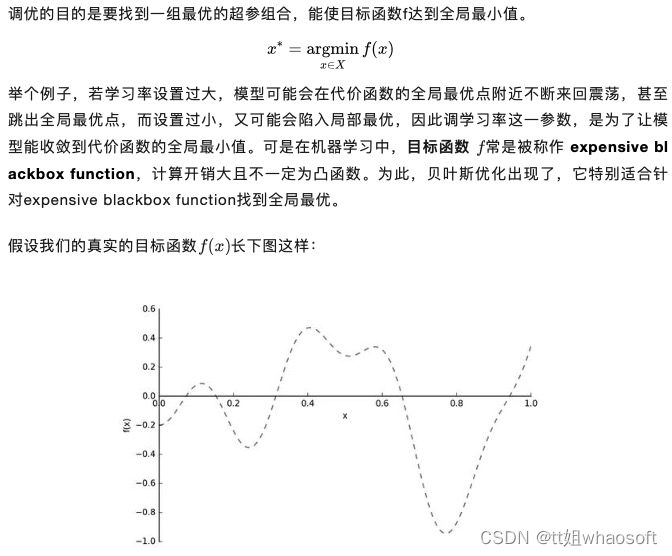
图2: 目标函数f(x)[4]
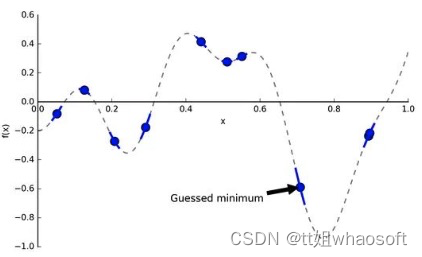

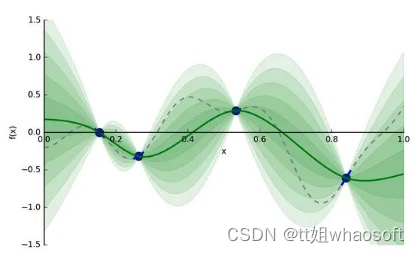
绿色实线就是GP猜的代理模型,绿色条带是输出分布的标准差(即为Uncertainty) 。我们有了代理模型,后续我们去找下一个合适的超参值,就能带入到计算开销相对较小的代理模型中,评估给定超参值的情况。
现在,我们来思考回之前提到的问题:"如何找到下一个合适的点?",这个问题本质是在问:“哪里有全局最小的点?”,为了解决这个问题,我们要关注两个地方:
(1) 已开发区域: 在绿色实线上最低的超参点。因为很可能它附近存在全局最优点。
(2) 未探索区域: 绿色实线上还未被探索的区域。比如图4,相比于0.15-0.25区间,0.65-0.75区间更具有探索价值(即该区间Uncertainty更大)。探索该区域有利于减少我们猜测的方差。
为了实现以上探索和开发的平衡(exploration-exploitation trade-off) ,贝叶斯优化使用了采集函数(acquisition function) ,它能平衡好全局最小值的探索和开发。采集函数有很多选择,其中最常见的是expectated of improvement(EI)[5] ,我们先看一个utility function
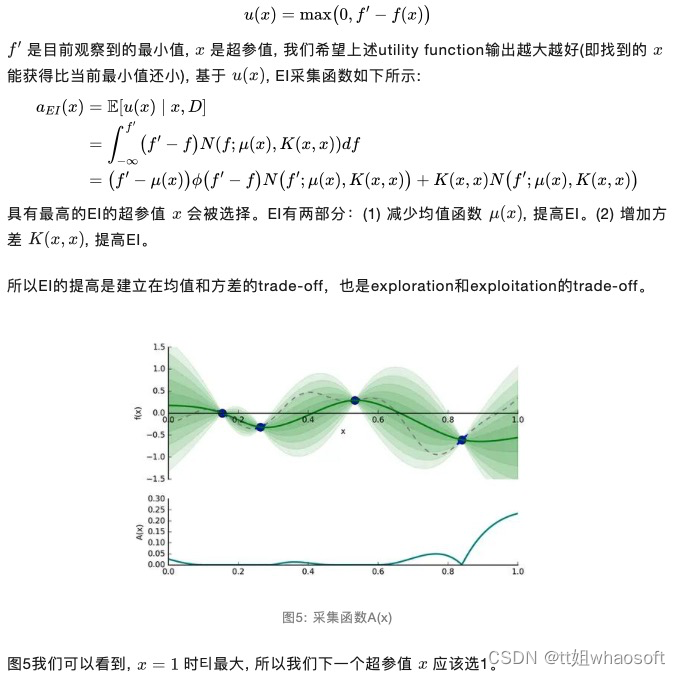
讲到这里,我们来看下完整的贝叶斯优化步骤是怎样的:

图6: 贝叶斯优化-SMBO
SMBO是简洁版的贝叶斯优化,伪代码如图6所示,具体如下:

四、Hyperband
除了格子搜索、随机搜索和贝叶斯优化,还有其它自动调参方式。例如Hyperband optimization[8],Hyperband本质上是随机搜索的一种变种,它使用早停策略和Sccessive Halving算法去分配资源,结果是Hyperband能评估更多的超参组合,同时在给定的资源预算下,比贝叶斯方法收敛更快,下图展示了Hyperband的早停和资源分配:
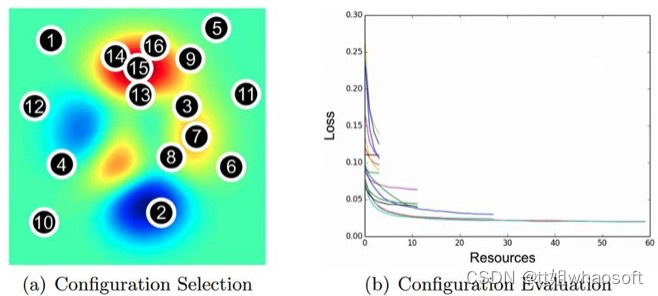
在Hyperband之后,还出现了BOHB,它混合了贝叶斯优化和Hyperband。Hyperband和BOHB的开源代码可参考HpBandSter库[9],这里不展开细讲。
五、总结
上面我们用Iris鸢尾花数据集试了不同的超参自动调优方法,发现贝叶斯优化和随机搜索都比格子搜索好。从一些论文反映,贝叶斯优化是更香的,但是贝叶斯优化好像在实践中用的不是那么多,网上也有很多分享者,像Nagesh Singh Chauhan,说的那样:
As a general rule of thumb, any time you want to optimize tuning hyperparameters, think Grid Search and Randomized Search! [10]
Hyperparameter Optimization for Machine Learning Models - Nagesh Singh Chauhan
为什么呢?我想原因是贝叶斯的开销太大了,前面有提到,在每次循环选超参值的时候,贝叶斯优化都需要将 带入昂贵的目标函数 中,去得到输出值y,当目标函数特别复杂时,这种情况的评估开销是很大的,更何况随着搜索空间和搜索次数的变大,计算会越发昂贵。在知乎《为什么基于贝叶斯优化的自动调参没有大范围使用?》[11]中,很多知乎主也给出了很认真的回复,建议有兴趣的朋友移步阅读。
写这篇文章的过程中,我主要学到了2点,一是随机搜索在某些时候会比格子搜索好,二是了解贝叶斯优化的机理。这里,谈谈我比赛和个人实践中的体会,我很少会花过多时间在超参的调优上,因为它带来的收益是有限的,很多时候比起压榨模型来说,思考和挖掘数据特征能带来更多的收益,所以我想这也是为什么上面说:在任何想要调优超参时,先用格子搜索或随机搜索吧。
参考资料
[1] sklearn.model_selection.GridSearchCV, 官方文档: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
[2] Bergstra, J., & Bengio, Y. (2012). Random search for hyper-parameter optimization. Journal of machine learning research, 13(2).
[3] sklearn.model_selection.RandomizedSearchCV, 官方文档: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html#sklearn.model_selection.RandomizedSearchCV
[4] Quora: How does Bayesian optimization work? - Duane Rich, 回答: https://www.quora.com/How-does-Bayesian-optimization-work
[5] Bayesian Optimization (2018). - Cse.wustl.edu. 课程Note: https://www.cse.wustl.edu/~garnett/cse515t/spring_2015/files/lecture_notes/12.pdf
[6] Hyperopt: Distributed Hyperparameter Optimization, 代码: https://github.com/hyperopt/hyperopt#getting-started
[7] Bergstra, J., Bardenet, R., Bengio, Y., & Kégl, B. (2011, December). Algorithms for hyper-parameter optimization. In 25th annual conference on neural information processing systems (NIPS 2011) (Vol. 24). Neural Information Processing Systems Foundation.
[8] Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., & Talwalkar, A. (2017). Hyperband: A novel bandit-based approach to hyperparameter optimization. The Journal of Machine Learning Research, 18(1), 6765-6816.
[9] HpBandSter开源代码库, 代码: https://github.com/automl/HpBandSte
[10] Hyperparameter Optimization for Machine Learning Models - Nagesh Singh Chauhan, 文章: [https://www.kdnuggets.com/2020/05/hyperparameter-optimization-machine-learning-models.html
[11] 为什么基于贝叶斯优化的自动调参没有大范围使用?- 知乎, 问答: https://www.zhihu.com/question/33711002
完事哈哈 请大佬指正















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









