






 AMD推出了基于CDNA架构的Instinct MI100计算卡,专为HPC高性能计算设计,性能最高提升7倍。这款卡集成120个计算单元,Matrix Core加速HPC和AI运算,支持PCIe 4.0,拥有高达10TFlops的FP64双精度性能,并与ROCm软件平台结合,提供强大的性能提升。
AMD推出了基于CDNA架构的Instinct MI100计算卡,专为HPC高性能计算设计,性能最高提升7倍。这款卡集成120个计算单元,Matrix Core加速HPC和AI运算,支持PCIe 4.0,拥有高达10TFlops的FP64双精度性能,并与ROCm软件平台结合,提供强大的性能提升。
在游戏领域,基于RDNA 2架构的Radeon RX 6000系列显卡已经开始闪亮登场。在高性能计算领域,基于CDNA全新架构的新一代计算卡Instinct MI100也终于登台了!
AMD Radeon Instinct系列计算卡已经发展了多款型号,但是在此之前,AMD GPU一直都是一套架构打天下,游戏、计算不分家,自然不利于不同方向的深度优化。

今年3月份,AMD宣布了首个专门针对数据中心高性能计算而设计的CDNA架构,从此与RDNA游戏架构分道扬镳。二者虽然还有一些共通点,但在设计、优化上已经泾渭分明,在各自领域的性能、能效也更高。
而在产品命名方面,AMD计算卡也放弃了Radeon字样,不再称呼Radeon Instinct,而是简单地叫做Instinct。
AMD Instinct可以说是专为HPC高性能计算而生的,志在推动超级计算机进入百亿亿次计算时代(ExaScale)。


回顾历史,21世纪的前10个年头属于万亿次计算时代(TeraScale),完全依赖CPU运算;最近10个年头属于千万亿次计算时代(PetaScale),GPU加速运算展露锋芒。
不过近两年,传统的GPU加速计算也已经初显疲态,性能增强曲线也缓了下来,必须实现全新的突破。



CDNA架构和MI100加速卡就是这样的突破性产品,也是AMD开拓新未来的新旗舰。
AMD Instinct MI100是其迄今为止性能最高的HPC GPU,FP64双精度浮点性能首次突破10TFlops(也就是每秒1亿亿次),并在架构设计上专门加入了Matrix Core(矩阵核心),用于加速HPC、AI运算,号称在混合精度和FP16半精度的AI负载上,性能提升接近7倍。
另外,新卡的外观设计也令人眼前一亮,更有质感的拉丝外壳,深灰色调,非常沉稳大气。

Instinct MI100计算卡采用台积电7nm工艺制造,集成120个计算单元、7680个流处理器,核心频率最高1502MHz,并专门加入了Matrix Core(矩阵核心),用于加速HPC、AI运算。
它整合封装了32GB HBM2显存,位宽4096-bit,频率1.2GHz,带宽1228.8GB/s,支持ECC。
该卡支持PCIe 4.0 x16,具备三条Infinity Fabric互连总线,峰值带宽92GB/s,总带宽276GB/s,相当于PCIe 4.0 x16的大约4倍,整卡热设计功耗300W,双8针辅助供电。


这块卡的特殊之处还在于顶部设置了桥接金手指,通过桥接器可以将四块卡绑定在一起,而搭配双路的AMD霄龙处理器,可以实现八卡并行。



类似之前的计算卡,甚至是R9 Fury X、Vega 64/56这样的游戏卡,Instinct MI110也是将GPU芯片、HBM芯片整合封装在了一起,不过如今的HBM2单颗容量已达8GB。
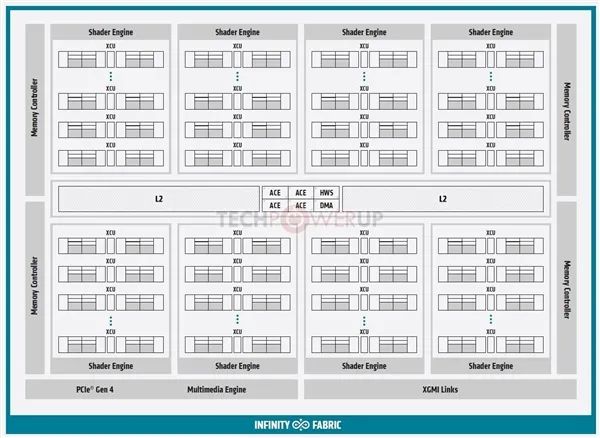
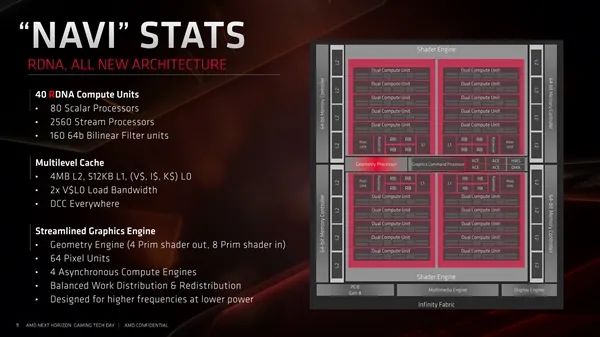
对比CDNA(上)、RDNA(下)架构图,可以发现二者整体框架有些相似之处,但各种单元模块和布局已经截然不同。
Infinity Fabric互连总线、显存控制器、PCIe 4.0控制器、多媒体引擎、着色器引擎、ACE异步计算引擎等等都还在(当然也不完全一样了),而和图形渲染输出相关的都没了,比如图形指令处理器、几何处理器、光栅器、显示引擎、原语单元等等,同时增加了XGMI连接控制器用于多卡互连,一二级缓存也完全不同。
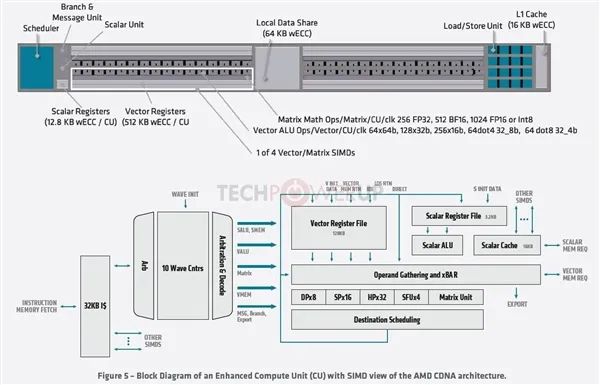
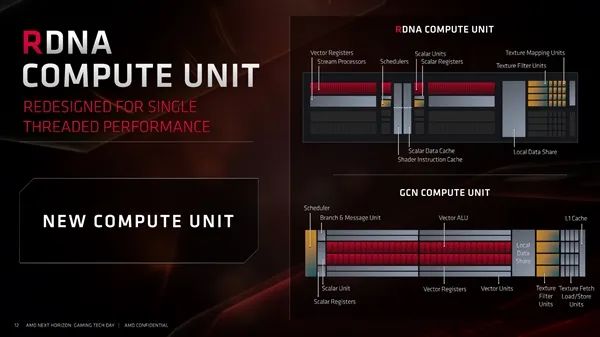
作为AMD GPU的最基本模块,计算单元(CU)也完全不同了,现在叫做增强型计算单元(XCU),组成模块包括调度器、分支与信息单元、12.8KB ECC标量单元、512KB ECC标量寄存器、矢量寄存器、矢量ALU操作单元、矩阵数据操作单元、四个矢量/矩阵SIMD单元、64KB ECC本地数据共享单元、载入/存储单元、16KB ECC一级缓存等等。
显然,这一些都是为计算服务的,而用于图形的着色器、纹理相关单元自然都不见了,即便有些单元名字一样,规格和作用也不同了。

计算性能方面,FMA64/FP64双精度为11.5TFlops(每秒1.15亿亿次),FMA32/FP32单精度为23.1TFlops(每秒2.31亿亿次),FP32 Matrix单精度矩阵计算为46.1TFlops(每秒4.61亿亿次),FP16 Matrix半精度矩阵计算为184.6TFlops(每秒18.46亿亿次),Bfloat16浮点为92.3TFlops(每秒9.23亿亿次)。
这些数字是什么概念呢?
就拿11.5TFlops的双精度性能来说,2000年排名世界第一的超级计算机ASCI White,这个指标也不过12.3TFlops,但却是付出了600万瓦的功耗、106吨的身材才获得的,Instinct MI100却只要300瓦、1.16千克。
换言之,如今的一块卡,就相当于20年前的一个大规模计算集群!

AMD上代计算卡Instinct MI50采用的还是Vega 20核心,60个计算单元,3840个流处理器,32GB HBM2显存带宽1TB/s,Infinity Fabric总线带宽92GB/s,功耗300W。
Instinct MI100的核心规模翻了一番,显存带宽提升了超过20%,Infinity Fabric带宽提升了整整2倍,但是功耗却完全没变(工艺应当也还是7nm),新架构的能效可见一斑。
新卡的性能更是不可同日而语,FP64双精度、FP32单精度性能均提升74%,FP32矩阵性能提升接近2.5倍,AI负载性能更是几乎7倍的飞跃。

对比NVIDIA安培架构的最新计算卡A100,AMD也给出了一些对比数据,FP32单精度性能领先18.5%,FP64双精度性能领先18.6%,AI与机器学习性能更是领先两倍多,而且功耗低了足足100W。

在美国能源部旗下的橡树岭国家实验室,AMD MI100计算卡已经在支撑多项百亿亿次科研项目,涉及NAMD分子动力学模拟、CHOLLA星系形成研究、PIConGPU激光放射癌症疗法、GESTS流体动力学等等诸多前沿科技。

AMD Instinct MI100计算卡还有一个绝佳搭档,那就是AMD自家的霄龙数据中心处理器,慧与、戴尔、超威、技嘉等多家行业巨头都有提供这种双A方案。

当然了,只有硬件,是做不成高性能计算的,AMD同时一直在推进一站式软件解决方案ROCm。
从2016年初入江湖的1.x版本,2018年奠定基础的2.0版本,到2019年专注于机器学习的3.0版本,再到如今最新的4.0版本,AMD ROCm已经打造成了一整套针对机器学习、高性能计算的百亿亿次级开发方案,规划中的各项功能特性也基本都已经实现。

软件优化的力量无疑是巨大的,可以充分释放硬件潜力,比如说上代MI50,搭配ROCm 3.0的话性能相比于搭配ROCm 2.0可以提升3-4倍,而最新的MI100、ROCm 4.0联合,更是可以轻松带来5-8倍的性能提升。

AMD ROCm生态的进步速度非常快,已经有众多领域的头部厂商采纳和支持,而且它沿袭了AMD一贯的原则,那就是完全开源开放,非常方便代码迁移,比如说HACC(宇宙学)只用了一个下午,SPECFEM3D(地震学)半天就搞定,CHOLLA(天体物理学)花了几天,QUDA(量子物理学)也不过21天。

与此同时,NVIDIA这边也推出了自己的A100 80GB加速卡。虽然AMD把性能夺回去了,但是A100 80GB的HBM2e显存也是史无前例了。
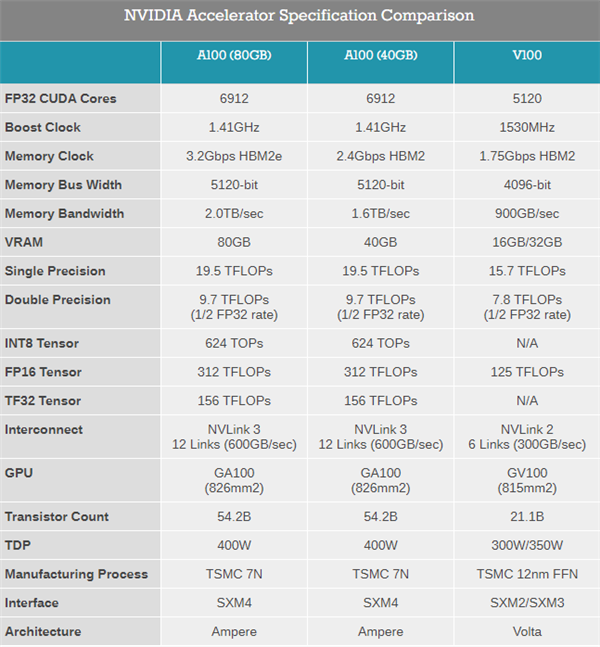
NVIDIA今年3月份发布了安培架构的A100加速卡(名字中没有Tesla了),升级了7nm工艺和Ampere安培架构,集成542亿晶体管,826mm2核心面积,使用了40GB HBM2显存,带宽1.6TB/s。
 图片来自Anandtech网站
图片来自Anandtech网站
现在的A100 80GB加速卡在GPU芯片上没变化,依然是A100核心,6912个CUDA核心,加速频率1.41GHz,FP32性能19.5TFLOPS,FP64性能9.7TFLOPS,INT8性能624TOPS,TDP 400W。
变化的主要是显存,之前是40GB,HBM2规格的,带宽1.6TB/s,现在升级到了80GB,显存类型也变成了更先进的HBM2e,频率从2.4Gbps提升到3.2Gbps,使得带宽从1.6TB/s提升到2TB/s。

对游戏卡来说,这样的显存容量肯定是浪费了,但是在高性能计算、AI等领域,显存很容易成为瓶颈,所以翻倍到80GB之后,A100 80GB显卡可以提供更高的性能,NVIDIA官方信息称它的性能少则提升25%,多则提升200%,特别是在AI训练中,同时能效也提升了25%。
在A100 80GB加速卡发布之后,现在的A100 40GB版依然会继续销售。

此外,还有全新的DGX Station A100工作站,配备了4个A100 80GB显存,还上了压缩机制冷。
上半年发布A100加速卡之后,NVIDIA推出了基于A100的DGX A100,这算是个mini超算了,最多可配备8路A100加速卡,而现在的DGX A100 640GB系统是它的升级版,显存容量可达640GB HBM2e。
升级之后的DGX A100 640超算性能提升也跟A100 80GB加速卡一样,AI大模型训练中提升最为明显,性能增加了200%,其他应用中性能提升25%到100%不等。
DGX A100 640GB超算的价格没公布,会提供给之前的客户升级选择。

还有一款新品是DGX Station A100,是A100家族中首款、也是唯一一款面向工作站的机器,配备了4块A100 80GB加速卡,320GB HBM2e显存,支持NVLink 3.0,带宽超过200GB/s。
其他方面,DGX Station A100使用的还是AMD的64核EPYC处理器,支持PCIe 4.0,内存可达512GB,1.92TB NVMe系统盘,M.2规格,数据盘最多可达7.68TB,U.2规格。
网络方面,DGX Station A100支持2个10Gbe万兆网卡,还支持4个mini DP输出4K,同时还有1个1Gbe千兆网卡用于远程管理。
当然,DGX Station A100最重要的升级是散热系统,之前的DGX使用的是水冷而已,这次DGX Station A100上了压缩机制冷,可以更好地控制温度,噪音也会降低,毕竟工作站跟DGX A100超算的使用环境不同,噪音还是有点影响的。
DGX A100 640GB、DGX Station A100的价格都没公布,不过现在已经量产上市了,并且已经用于部分超算,比如英国的Cambridge-1就用50台DGX A100 640GB超算,其他商业性销售要到明年1月份,2月份会扩大规模。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









