






分布式数据库下数据是如何进行水平切分的?
说明:之前对分布式数据库接触的比较少,近期学习了两周Gbase 8a MPP Cluster
,由于个人知识有限,只记录下对分布式数据库数据切分浅显的理解。
首先GBase 8a MPP Cluster
,全称:南大通用大规模分布式并行数据库集群系统,它是在
GBase 8a
列存储数据库基础上开发的一款
Shared Nothing
架构的分布式并行数据库集群。
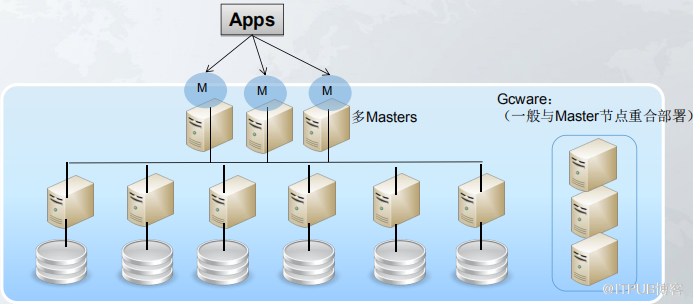
数据库环境如下:
管理节点
:192.168.38.10
、
192.168.38.20
计算节点:192.168.38.10
、
192.168.38.20
、
192.168.38.30
其中管理节点由多台服务器组成一个管理集群,计算节点由多台服务器组成一个计算集群。
[root@cjcos0
1
~]# gcadmin
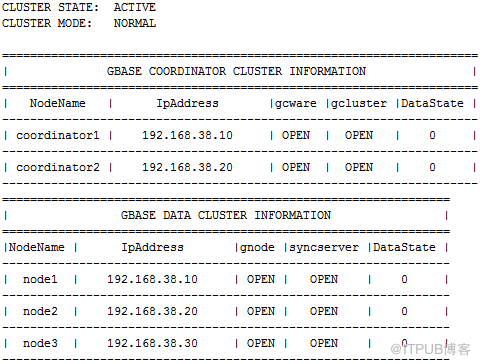
数据库分布情况如下:
每台计算节点服务器上有两个主分片,一个副本分片
[gbase@cjcos01 gcinstall]$ gcadmin showdistribution node

当然,主分片个数和备份分片个数可以根据实际情况进行调整,例如:
[gbase@cjcos01 gcinstall]$ gcadmin distribution gcChangeInfo.xml p
2
d
1
pattern
2
在如上这种架构和分片结构下,表数据是如何分布的?
例如有一张表
t1
,因为一共有
6
个分片,
t1
表的数据会被切分成
6
份,也就是
t1_n1,t1_n2,t1_n3,t1_n4,t1_n5,t1_n6
,按照上面的分布情况,会将
t1_n1,t1_n4
主分片数据存储在
192.168.38.10
服务器上,将
t1_n2,t1_n5
主分片数据存储在
192.168.38.20
服务器上,将
t1_n3,t1_n6
主分片数据存储在
192.168.38.20
服务器上。
某台计算节点服务器发生故障,如何实现故障转移?
例如
192.168.38.10
服务器故障,那么当有应用需要访问这台服务器上的
t1_n1
、
t1_n4
数据时,可以将查询指向
t1_n1
、
t1_n4
的副本数据里,既
192.168.38.20
副本集里的
t1_n1
、
t1_n4
,还可以通过将高可用模式改成负载均衡模式,将
192.168.38.10
主分片对应的副本分片指定分布到多台服务器上,降低木桶效应的产生。
在插入或加载数据时,这条数据应该存储到哪台服务器的哪个分片上?
具体新数据应该存储到哪个上,和表分布方式有关,常见分布表有随机分布表和HASH
分布表。
(1)
随机分布表
:
将数据平均分布到各个节点各个分片上,优点是看上去表的数据是被均匀打散到各个节点各个分片上的,减少了木桶效应的产生,但是在进行大表关联或
group by
等操作时,可能会因为拉复制表或
HASH
动态重分布导致性能下降。
(2)HASH
分布表
:
提前将表的某一列选为
HASH
分布列,对该列进行
HASH
运算生成
HASH
值,而在数据库内部提前创建好了一张
nodedatamap
表,这张表记录了具体的
HASH
值对应到哪个具体节点的分片上,而
nodedatamap
表的数据又是根据之前创建好的
distribution
分布生成的。这样会将
HASH
值相同的数据存放到一个分片上,优点是在进行大表关联或
group by
等操作时,可以实现静态减少拉复制表或
HASH
动态重分布操作,缺点是数据可能分布不均匀,一定要选取合适的
HASH
分布列。
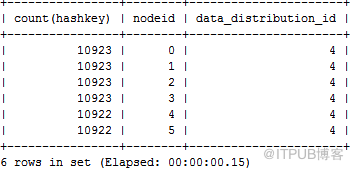
首先看下各个节点对应的HASH
值数量基本是相同的。
gbase> select count(hashkey),nodeid,data_distribution_id from gclusterdb.nodedatamap group by nodeid,data_distribution_id order by 2;
创建表
t1
和
t2
,实际看下数据是如何分布的。
gbase> create table t1(id int,name varchar(10)) distributed by ('id');
gbase> create table t2(id int,cname varchar(10)) distributed by ('id');
gbase> insert into t1 values(1,'A'),(2,'B'),(3,'C'),(4,'D'),(5,'E'),(7,
’
FFF
’
);
gbase> insert into t2 values(1,'AA'),(2,
’
XX
’
),(3,'BB'),(5,'CC'),(7,'DD'),(9,'EE');
先看下id=1,2,3,4,5,6,9
时对应的
hash
值是多少,应该存储在哪个分片上。
select
*
from
gbase.nodedatamap
where
hashkey=(crc32(
'1'
))
mod
65536
and
data_distribution_id=
4
;

select
*
from
gbase.nodedatamap
where
hashkey=(crc32(
'2'
))
mod
65536
and
data_distribution_id=
4
;

select
*
from
gbase.nodedatamap
where
hashkey=(crc32(
'3'
))
mod
65536
and
data_distribution_id=
4
;

select
*
from
gbase.nodedatamap
where
hashkey=(crc32(
'4'
))
mod
65536
and
data_distribution_id=
4
;

select
*
from
gbase.nodedatamap
where
hashkey=(crc32(
'5'
))
mod
65536
and
data_distribution_id=
4
;

select
*
from
gbase.nodedatamap
where
hashkey=(crc32(
'7'
))
mod
65536
and
data_distribution_id=
4
;

select
*
from
gbase.nodedatamap
where
hashkey=(crc32(
'
9
'
))
mod
65536
and
data_distribution_id=
4
;


可知:id=1,2,3,4,5,7,9
数据分别分布在
nodeid4,5,4,3,4,0,2(segments 5,6,5,4,5,1,3)
上,例如
id=1,3,5
存储在
192.168.38.20
服务器是上
t1
、
t2
的第
5
个分片上,既
t1_n5
、
t2_n5
表上。
以单机模式连接到192.168.31.20
,验证一下上面的理论是否正确。
[gbase@cjcos02 ~]$ gncli
gbase> show tables;

其中
n2,n5
是主分片数据,
n1,n4
是备份分片。
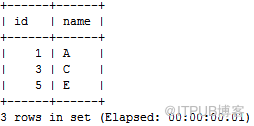
查看
id=1,3,5
确实分布到了
t1
表第
5
个分片上,既
t1_n5;
gbase> select * from t1_n5;
gbase> select * from t2_n5;
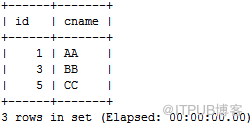
同理,我们知道,
t1
和
t2
表
id
数据分布如下:
ip=192.168.31.10
p=192.168.31.20
p=192.168.31.30
id=1
t1_n5,t2_n5
id=2
t1_n6,t2_n6
id=3
t1_n5,t2_n5
id=4
t1_n4
id=5
t1_n5,t2_n5
id=7
t1_n1,t2_n1
id=9
t1_n3,t2_n3
可以看到,t1
和
t2
表的数据通过
HASH
算法存储到了
192.168.31.10,20,30
三台服务器上,每个服务器节点下有
2
个分片,既
1
张表数据理论上被分成
6
份存储到
3
台服务器上。例如
t1
表被切分成
t1_n1,t1_n2,t1_n3,t1_n4,t1_n5,t1_n6
,数据是按照
nodedatamap
表里
hash
值和分片对应关系对应写入到各个分片上的,从而实现了表数据的水平切分。
具体过程:
1
先根据实际情况,通过
gcadmin distribution
命令定义了每个节点上的主分片和副本分片的个数和分布,以及负载或高可用模式等,
2
使用
initnodedatamap
命令,同时根据第一步制定的分布规则,将hash
值和分片对应关系写入到
nodedatamap
表里。
3 HASH
分布表在写入数据时,根据
nodedatamap
表里hash
值和分布对应关系,将数据写入到指定节点的指定分片上。
那么在分布式数据库下,SQL
优化需要考虑哪些因素呢?
在分布式数据库下,
多表
join
操作,
group by
,
order by
是如何实现的?
下一节在具体说明下优化相关内容。
欢迎关注我的微信公众号"IT小Chen",共同学习,共同成长!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









