






 本文详细介绍了Oracle数据库的基本操作,包括创建与删除数据库、数据备份与还原,以及表的相关操作如创建、删除、重命名和字段管理。同时,也阐述了Hive的数据操作,包括创建和管理数据库、表的创建、数据加载与查询,以及表的分区和排序等。内容涵盖了数据库管理和数据处理的关键步骤。
本文详细介绍了Oracle数据库的基本操作,包括创建与删除数据库、数据备份与还原,以及表的相关操作如创建、删除、重命名和字段管理。同时,也阐述了Hive的数据操作,包括创建和管理数据库、表的创建、数据加载与查询,以及表的分区和排序等。内容涵盖了数据库管理和数据处理的关键步骤。
Oracle基本操作
库相关
- create database databasename – 创建库
- drop database dbname – 删除库
备份库
-
完全备份数据库 – exp demo/demo@orcl buffer = 1024 file = d: \back.dmp full = y
demo: 用户名、密码
buffer: 缓存大小
file: 具体的备份文件地址
full: 是否导出全部文件
ignore: 忽略错误,如果表已存在,则也是覆盖
-
将数据库中的system用户与sys用户的表导出 – exp demo/demo@orcl file=d:\backup1.dmp owner=(system,sys)
-
导出指定的表 – exp demo/demo@orcl file=d:\backup2.dmp tables=(teachers,students)
-
按过滤条件导出 – exp demo/demo@orcl file=d:\back.dmp tables(table1) query=" where filed1 like ‘fg%’"
-
备份远程数据库的数据库 – exp 用户名/密码@远程的IP:端口/实例 file=存放的位置:\文件名称.dmp full=y
还原库
- 完整还原 – imp 账号/密码 file=文件路径\文件名.dmp full=y log=路径
- 导入指定表 – imp 账号/密码 file=文件路径\文件名.dmp tables=(table1,table2)
- 还原到远程服务器 – imp 账号/密码 file=文件路径\文件名.dmp full=y
表相关
- 创建表 – create table 表名 (col1 type1 [primary key] [auto_increment],…)
- 使用旧表创建新表 – select * into table_new from table_old
- 仅适用于 oracle – create table tab_new as select col1,col2,… from table_old definition only
- 删除表 – frop table tablename
- 重命名表 – alter table 表明 rename to 新表名
- 增加字段 – alter table 表名 add (字段名 字段类型 默认值 是否为空);
- 修改字段 – alter table 表名 modify (字段名 字段类型 默认值 是否为空);
- 重命名字段 – alter table 表名 rename column 列名 to 新列名 – column 为关键字
- 删除字段 – alter table 表名 drop column 字段名;
- 添加主键 – alter table 表名 add promary key(col);
- 删除主键 – alter table 表名 drop primary key(col);
- 创建索引 – create [unique] index idxname on tabname(col…)
- 删除索引 – drop index indexname
- 创建视图 – create view viewname as select statement
- 删除视图 – drop viwe viwename
数据相关
-
数据查询 – select <列名> from <表名> [where <查询条件表达式>] [order by <排序的列名>] [asc或desc]
-
全字段插入数据 – insert into 表名 values(所有列的值)
-
部分字段插入数据 – insert into 表名(列名) values(对应的值)
-
根据条件更新部分数据 – update 表名 set 列名 = 新的值 [where 条件]
-
更新全部数据 – update 表名 set 列名 = 新的值
-
根据条件删除满足条件的记录 – delete from 表名 where 条件
-
删除表中所有记录 – delete from 表名
-
提交数据 – commit
-
回滚数据 – rollback
-
数据复制
- 表数据复制 – insert into table1 (select * from table2)
- 复制表结构 – create table table1 select * from table2 where 1 > 2
- 复制表结构和数据 – create table table1 select * from table2
- 复制指定字段 – create table table1 as select id,name from table2 where 1 > 1;
-
行列转换(Decode)
select id,name,
sum(decode(course,‘语文’,score)) 语文,
sum(decode(course,‘数学’,score)) 数学,
…
from student
group by id,name
-
行列转换(Case)
select id,name,
max(case when course=‘语文’ then score else 0 end) 语文,
max(case when course=‘数学’ then score else 0 end) 数学,
…
from student
group by id,name
-
行列转换(wmsys.wm_concat行转列函数)
select id,name,
wmsys.wm_concat(course || ‘;’ || score)
coursefrom student group by id,name -
行列转换函数(wm_concat)
select wm_concat(name),name from test – 默认都好隔开

select (wm_concat(name),’ , ’ , ’ | ') from test – , 被 |替换了

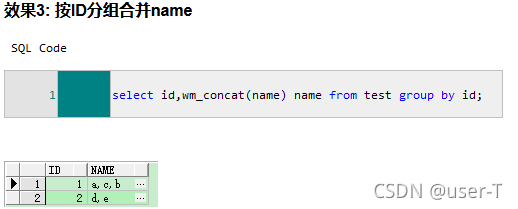
select id,wm_concat(name) name from test group by id – 按 id 分组合并name
 pivot (sum(nums) for name in (‘苹果’ 苹果 , ‘橘子’ 橘子 , ‘葡萄’ 葡萄 , ‘芒果’ 芒果));

pivot(聚合函数 for 列名 in (类型) ),其中 in(’’)中可以指定别名,in中还可以指定子查询,比如 select distinct code from customers
hive基本操作
库相关
- 创建数据库 – create database 库名
- 查看数据库 – show databases
- 切换数据库 – use 库名
- 删除数据库 – drop database if exists 库名
表相关
-
创建外部表 – create external table if not exit 表名 (
id int ,
name string,
age string
)
表创建完成之后,会在 HDFS 上的 /usr/hive/warehouse 目录创建相应的文件
-
创建分区表 – create table 表名 (
id int,
name string
)partitioned by (country string) row format delimited fields terminated by " ";
-
查看所有表 – show tables
-
查看表信息 – desc 表名
-
查看拓展描述信息 – describe formatted 表名
-
删除表 – drop table 表名
外部表删除之后,其在 HDFS 上存储的文件并不会被删除
-
表加载数据 – load data local inpath ‘路径’ into table 表名
-
导入数据(指定分区) – load data local inpath ‘路径’ into table 表名 partition(country=‘china’);
使用 load 命令导入数据,导入 HDFS 内的文件不需要在前面加 local
-
查看数据 – select * from 表名
-
添加分片 – alter table 表名 add partition(country=“American”);
-
创建分块表 – create table 表名(字段 字段类型) clustered by (字段,一般为id) into 4 buckets row format delimited fields terminated by ’ , ’ stored as textfile;
-
创建临时表 – create table 表名 (字段名 字段类型) row format delimited fields terminated by ’ , ’
-
导入数据到临时表(insert-select方式导入) – insert into 表名 select * from 其他表
-
分区且有序 – insert into 表名 select * from 其他表 cluster by (字段名, 一般为id) into 表名 sort by (字段名,一般为id)
cluster by 已经有了sort by 的含义
表操作
-
查询表数据 – select * from 表名
order by 对输入做全局排序,因此只有一个 reduce,会导致当输入规模较大时,需要比较长的计算时间
sort by 不是全局排序,其数据进入 reduce 前完成排序,因此,如果使用 sort by进行排序,且设置 mapred.reduce.tasks>1,则 sort by 只保证每个 reduce 有序,不保证所有都有序
distributed by 根据 distributed by 指定的内容,将数据分到不同的 reduce,分发算法为 hash 散列
cluster by 除了具有 cluster by 的功能之外,还会对该字段进行排序
分桶和sort字段为同一个字段时,cluster by = distributed by + sort by
-
将查询结果保存到一个新的 hive 表内 – create table 表名 as select * from 其他表
-
将查询结果保存到一个存在的 hive 表内 – insert table 表名 as select * from 其他表
-
导出到目录文件(local) – insert overwrite local directory ‘路径’ select * from 表名
sort by
-
将查询结果保存到一个新的 hive 表内 – create table 表名 as select * from 其他表
-
将查询结果保存到一个存在的 hive 表内 – insert table 表名 as select * from 其他表
-
导出到目录文件(local) – insert overwrite local directory ‘路径’ select * from 表名
-
导出到目录文件(HDFS) – insert overwrite directory ‘路径’ select * from 表名
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









