







问题1:
代码清单1-1的编程方法很有问题。即使在循环中调用的SQL语句是高度优化的,程序的执行还是会消耗大量时间。假设查询customers表的SQL语句消耗0.1秒,INSERT语句也消耗0.1秒,那么在循环中每次执行就要0.2秒。如果游标c1取出了100 000行,那么总时间就是100 000乘以0.2秒,即20 000秒,也就是大约5.5小时。很难去优化这个程序的结构。基于显而易见的理由,TomKyte把这种处理方式定义为慢之又慢的处理(slow-by-slow
processing)。
问题2:
代码清单1-1的代码还有一个固有的问题。从PL/SQL的循环中调用的SQL语句会反复在PL/SQL引擎和SQL引擎之间切换执行,这种两个环境之间的切换称作上下文切换。上下文切换增加了程序运行的时间,并增加不必要的CPU开销。你应当通过消除或减少这种两个环境之间的切换来减少上下文切换的次数。一般应当禁止逐行处理,更好的编程实践是把代码清单1-1的程序转换成一个SQL语句。代码清单1-2重写了代码,完全避免了PL/SQL
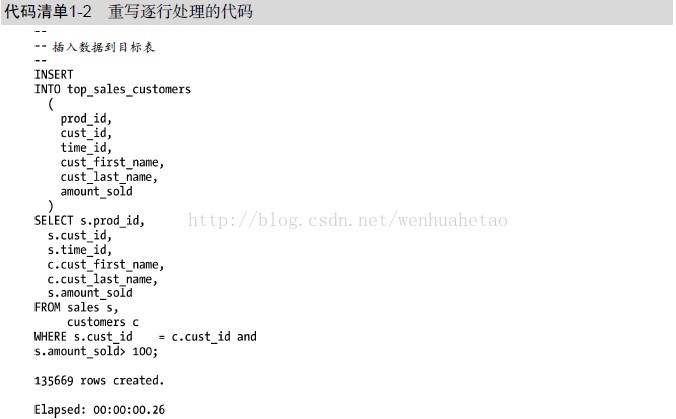
代码清单1-2除了解决逐行处理的缺陷以外,还有更多的优势。重写后的SQL语句可以使用并行执行来调优,使用多个并行执行进程可以大幅地减少执行时间。并且,代码变得简明且可读性强。
2.嵌套的逐行处理
在代码清单1-3中,c1、c2和c3是嵌套游标。游标c1是顶级游标,从表t1取得数据,c2是开放游标,传递从游标c1取得的值,c3也是开放游标,传递游标c2取得的值。有一个UPDATE语句对游标c3返回的每一行执行一次。尽管UPDATE语句已经优化为执行一次只要0.01秒,但程序的性能还是会由于深度嵌套游标而难以忍受的。假设游标c1、c2和c3分别返回20、50和100行,那么上述代码需要循环100 000行,程序的总执行时间超过了1000秒。对这类程序的调优通常需要完全重写它。
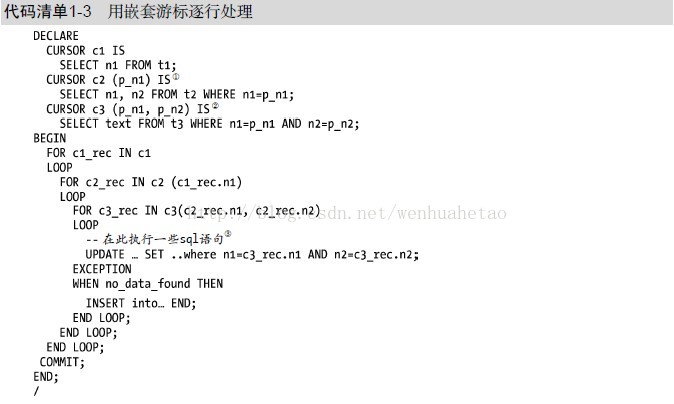
代码清单1-3中代码的另一个问题在于先执行一个UPDATE语句。如果UPDATE 语句产生了
no_data_found异常④,那么再执行一个INSERT语句。这种类型的问题可以利用MERGE语句从PL/SQL
转到SQL引擎处理。
从概念上讲,代码清单1-3中的三重循环表示表t1、t2和t3之间的等值连接。代码清单1-4展示
了根据上述逻辑改写的使用表别名t的SQL语句。UPDATE和INSERT逻辑的结合用MERGE语句代替,
MERGE语法提供了更新存在的行和插入不存在的行的功能。

不要在PL/SQL语言中编写深度嵌套游标的代码。审查这类代码的逻辑,看是否能用SQL语句来代替。
3.查找式查询
查找式查询(lookup query)一般用于填充某些变量或执行数据的合法验证。但在循环中执行查找式查询会导致性能问题。在代码清单1-5中,高亮显示的部分就是使用查找式查询来得到country_name值。程序对游标c1中的每一行都要执行一个查询来取得country_name的值。当从游标c1中取得的行数增加时,执行查找式查询的次数也增加了,这导致代码的效率低下。
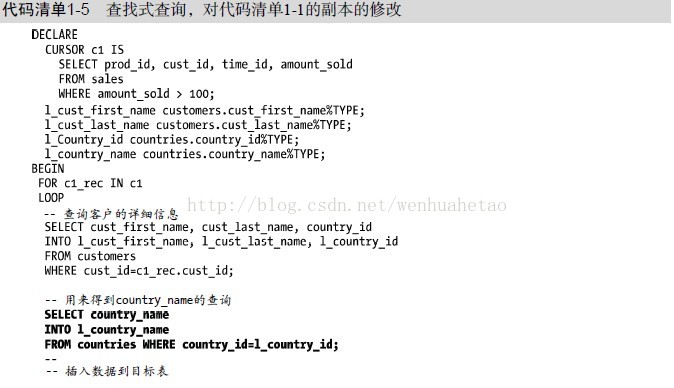

代码清单1-5的代码是过分简化的,对country_name的查找式查询实际上可以重写为主游标c1本身中的一个连接。第一步,应将查找式查询修改为连接,可是在实际的应用程序中,并不一定可以实现这种改写。如果无法利用改写代码来减少查找式查询的执行次数,那么还有另一个选择。你可以定义一个关联数组来缓存查找式查询的结果,以便在随后的执行中重用这个数组,这样也能有效地减少查找式查询的执行。代码清单1-6演示了数组缓存技术。不必再在游标c1返回的每一行中执行查询来得到country_name,而是用一个名为l_country_names的关联数组来存储本例中的country_id
和country_name键—值对。关联数组和索引类似,任意给定的值都可以通过一个键值来访问。在执行查找式查询前,通过EXISTS操作对一个数组中是否存在一个匹配country_id键值的元素做一个存在性验证,如果数组中存在这么一个元素,那么country_name就从数组中获取而不需
要执行查找式查询。如果没有这样的元素,那么就执行查找式查询,并且把查到的结果作为一个新元素存入数组。你还需要理解,这种技术非常适用于不同的键值很少的语句,在本例中,当country_id列的唯一值个数越少时,查找式查询的执行次数可能也越少。如使用示例模式,执行查找式查询的次数最多是23,因为country_id列只有23个不同的值。


注意 关联数组所需内存是在数据库服务器中专用服务器进程的PGA(Program Global Area,程序全局区)中分配的,如果数千个连接都要把程序的中间结果缓存到数组中,那么内存的占用将会大幅增加。你应当掌握每个进程的内存使用增加情况,并设计数据库服务器以适应内存的增长。
oracle pl/sql 实战学习 -避免误用
标签:oracle plsql 性能 语言 sql

本条技术文章来源于互联网,如果无意侵犯您的权益请点击此处反馈版权投诉
本文系统来源:http://blog.csdn.net/wenhuahetao/article/details/45966307















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









