






 本文介绍了如何在AMOS中进行验证性因素分析(CFA),强调了聚合效度和区别效度的概念,并详细阐述了绘制潜变量图的过程。从SPSS启动AMOS,设置潜在变量和观察变量,调整方向,插入值,建立协方差,计算组合效度(CR)和平均方差抽取(AVE),并关注适配度指标如CMIN、RMSEA和AIC。
本文介绍了如何在AMOS中进行验证性因素分析(CFA),强调了聚合效度和区别效度的概念,并详细阐述了绘制潜变量图的过程。从SPSS启动AMOS,设置潜在变量和观察变量,调整方向,插入值,建立协方差,计算组合效度(CR)和平均方差抽取(AVE),并关注适配度指标如CMIN、RMSEA和AIC。
* 没有数据缺失时选用极大似然估计法(Maximum Likelihood Estimates)
有数据确实时选用Full Information Maximum Likelihood (Arbuckle, Marcoulides, & Schumacker, 1996)
验证性因素分析(Confirmatory Factor Analysis)
EFA是简历量表或问卷的建构效度
CFA是检验此建构效度的适切性和真实性(观察变量与潜在变量间的关系)
聚合效度(Convergent validity):测量同一特质构念的测量指标会落在同一个因素构念上(.50~ .95)
区别效度(Discriminant validity):两个因素构念间是有区别的(相关显著不等于1)

开始:
首先在SPSS里面打开amos

当当当AMOS界面出现
之后开始画图

点上红色框框里的图标,开始画潜变量,
例如 社会性成就目标 (social achievement goals)
包括 DEP (social development goal)
DAP (social demonstration-approach goal)
DAV (social demonstration-avoidance goal)
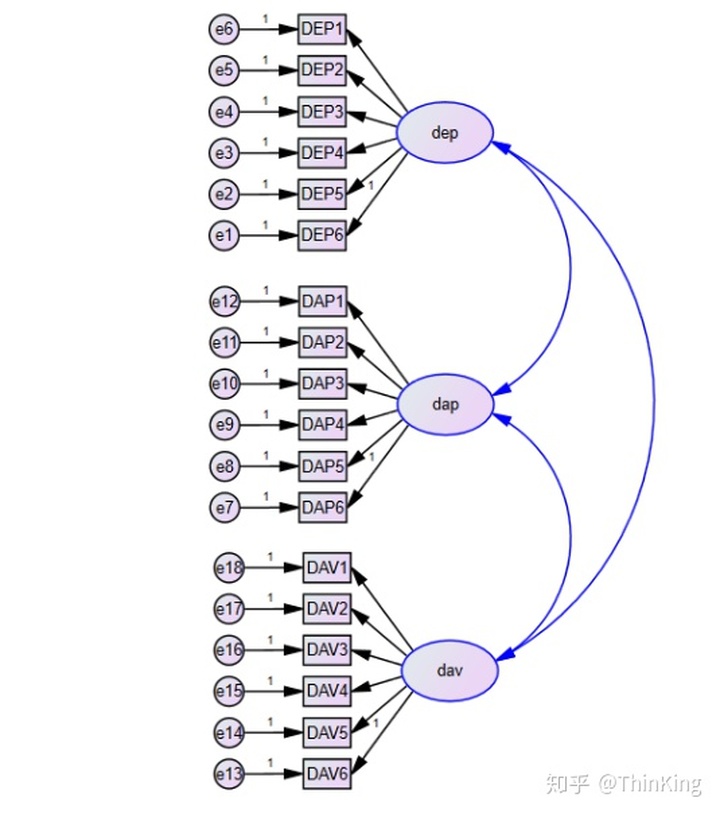
每个variable都有6个观察变量,所以所绘试图如下:

调整他们的方向,设置每一个潜在变量的名称和插入观察变量的值
- 如果不是在SPSS中打开的AMOS的话,还的把所用数据文件打开,如下图所示。

设置每一个潜在变量的名称(双击红色圈圈的潜在变量)
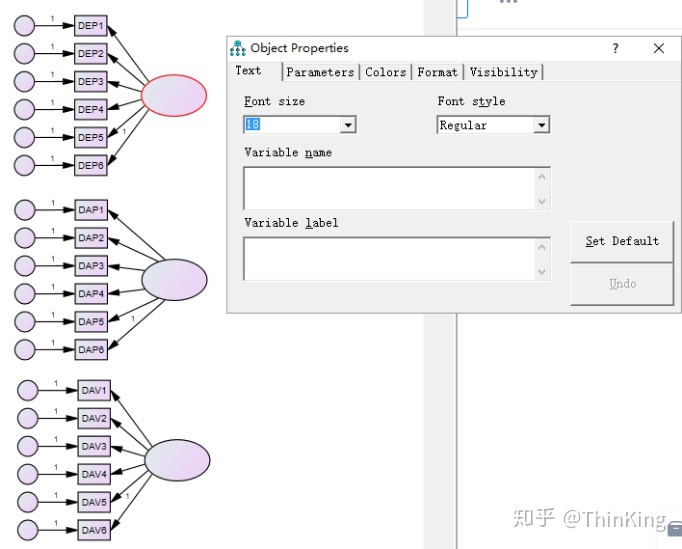
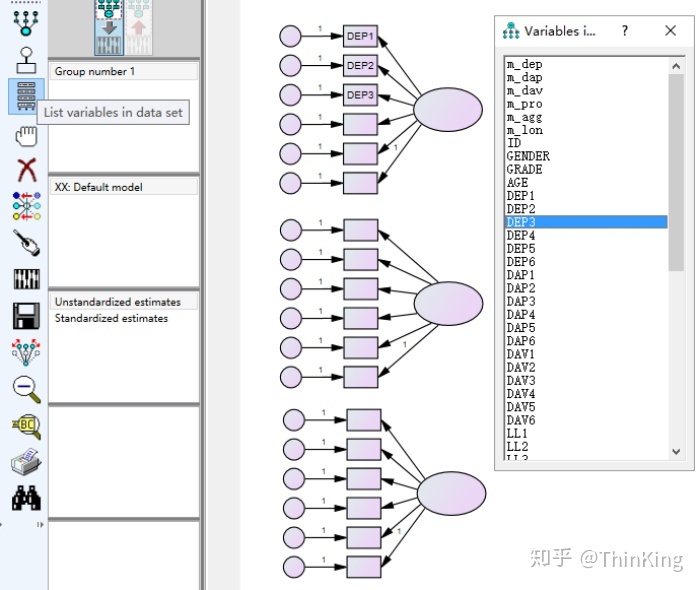
之后 插入观察变量的值
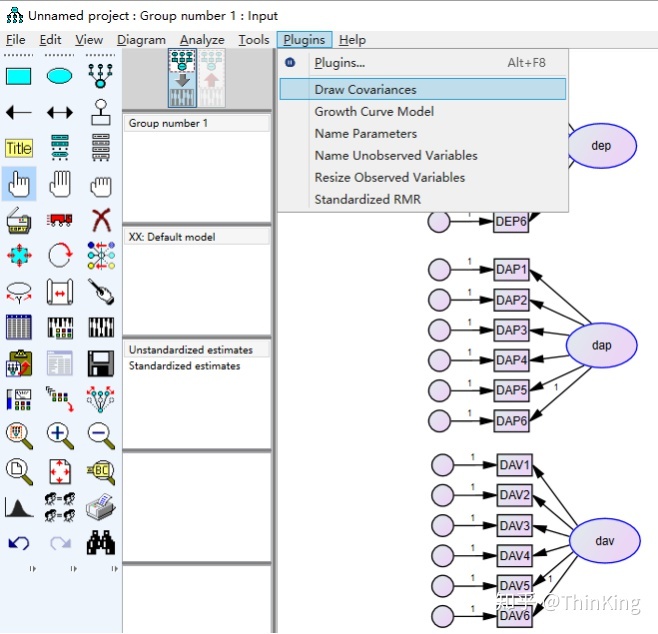
在所有潜在变量之间画covariances
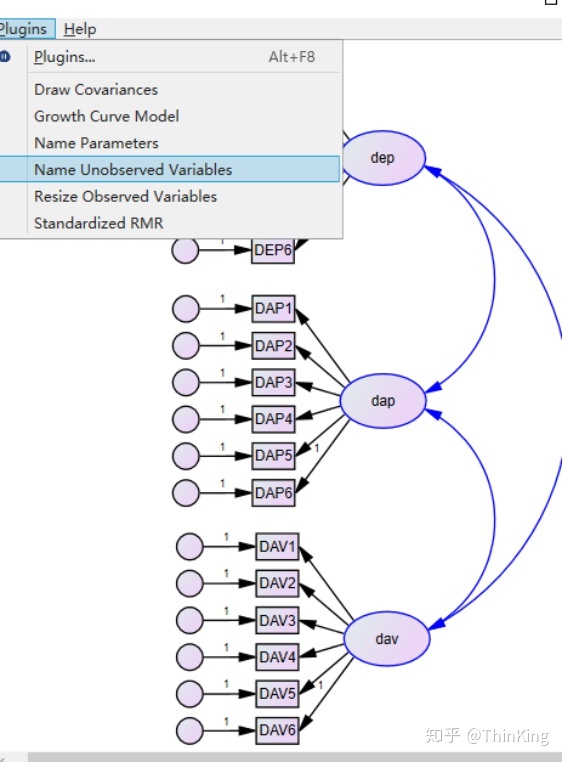
命名空白残差
当当当
所谓的基本图形完成
现在开始分析吧
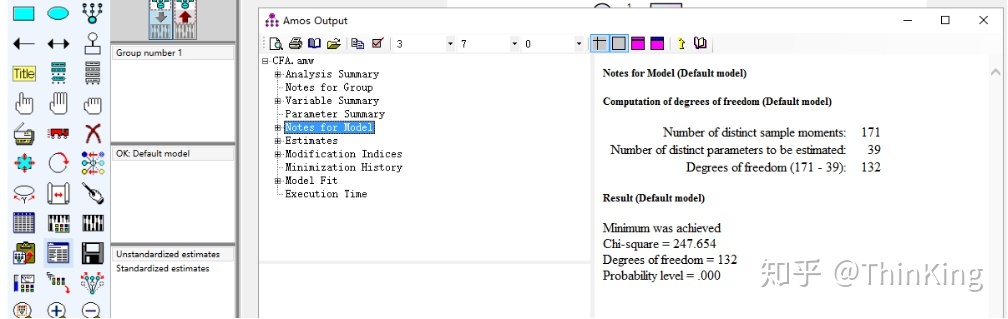
结果就出来啦
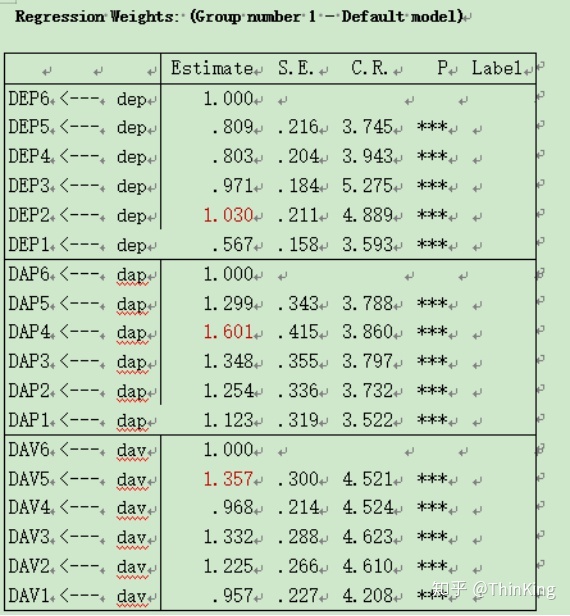
之后就找数值吧
在estimate里面regression weights
如: DEP1~6 estimate 数值出现最大数值是1.030,那么这个时候就要把DEP->DEP2的那条线regression weights 设置为1;DAP,DAV的情况如同DEP进行就可以啦。
改完之后的结果分析
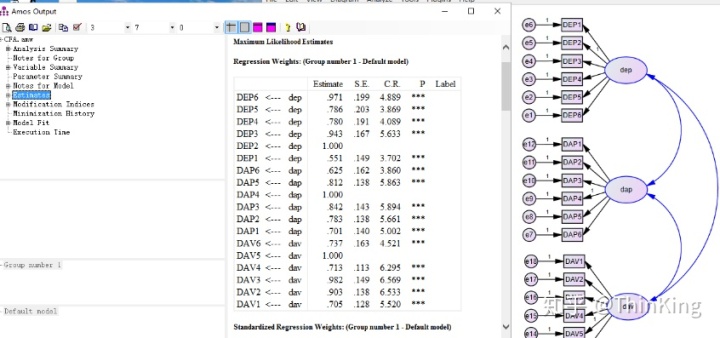
Estimates参数估计值

CR:组合效度
因素负量Factor loading =
Error Variance = 1-CR
AVE > 0.5
* EXCEL 算法文档CR & AVE.xls
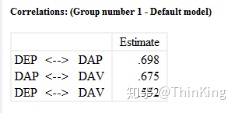
* Correlations 三组因素间相关系数均在.75以上,显示出这三个因素间可能有另一个更高阶的共同因素存在。此时采用斜交CFA模型较为适宜。

* 均为正数
如果出现负数,此时CFA测量模型应重新界定。
适配度(Model Fit Summary)
CMIN

* 预设模型(Default model),饱和模型(Saturated model),独立模型(Independence model)都会提供参数,但我们一般都以预设模型列的参数为准。
Baseline Comparisons
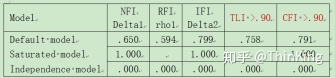
RMSEA

AIC
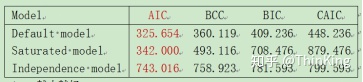
* AIC越小越好
AIC 的参数 default model< saturated model < independence model
Arbuckle, J. L., Marcoulides, G. A., & Schumacker, R. E. (1996). Full information estimation in the presence of incomplete data. Advanced structural equation modeling: Issues and techniques, 243, 277.
未完继续ing~~

















 6106
6106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









