







概述
文章https://segmentfault.com/a/11... 中介绍了存储应该考虑的方向。本文详细介绍其中的mysq,主要是INNODB。整体架构,启动流程,一条语句的执行过程带你快速深入mysql源码。再从性能(缓存,数据结构),功能(ACID实现,索引)如何实现介绍了mysql中核心点。第二部分为分布式,介绍原生mysql的同步过程。第三部分是proxy,因为proxy多数会自研,只介绍proxy应该包含的功能。
关键词:innodb,MVCC,ACID实现,索引,主从同步,proxy
第一章 整体架构/流程
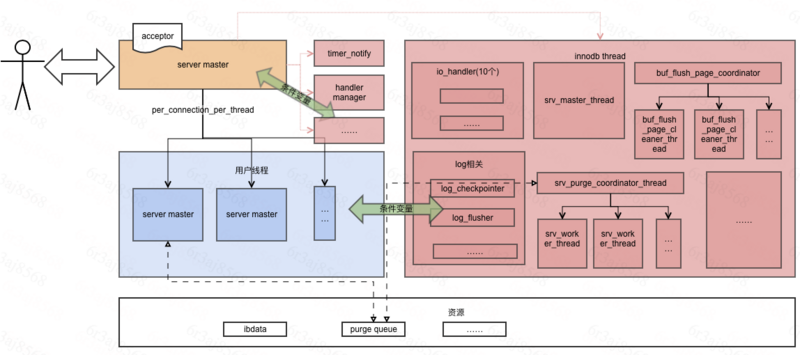
mysql为单进程多线程,因为元数据用Innodb保存,启动后除了mysql的处理连接请求/超时等还会启动Innodb的所有线程。
主流程:
主函数在sql/amin.cc中
调用Mysqld.cc中mysqld_main
1. 首先载入日志,信号注册,plugin_register
(mysql是插件式存储引擎设计,innodb,myisam等都是插件,在这里注册),核心为mysqld_socket_acceptor->connection_event_loop();
2. 监听处理循环poll。
process_new_connection处理handler有三种:线程池方式只用于商业,一个线程处理所有请求,一个连接一个线程(大多数选择Per_thread_connection_handler)。
3. 若thread_cache中有空闲直接获取,否则创建新的用户线程。进入用户线程的handle_connection
3.1 mysql网络通信一共有这几层:`THD` | Protocol | NET | VIO | SOCKET,protocol对数据的协议格式化,NET封装了net buf读写刷到网络的操作,VIO是对所有连接类型网络操作的一层封装(TCP/IP, Socket, Name Pipe, SSL, SHARED MEMORY),handle_connection初始化THD(线程),开始do_command (关于THD,有个很好的图:http://mysql.taobao.org/monthly/2016/07/04/)
3.2.do_command=>dispatch_comand=>mysql_parse=》【检查query_cache有缓存直接返回否则=》】parse_sql=》mysql_execute_cmd判断insert等调用mysql_insert,每条记录调用write_record,这个是各个引擎的基类,根据操作表类型调用引擎层的函数=》写binlog日志=》提交/回滚。注意大家可能都以为是有query_cache的。但是从8.0开启废弃了query_cache。第二正会讲一下
4. 除了用户线程和主线程,在启动时,还创建了timer_notify线程。由于为了解决DDL无法做到atomic等,从MySQL8.0开始取消了FRM文件及其他server层的元数据文件(frm, par, trn, trg, isl,db.opt),所有的元数据都用InnoDB引擎进行存储, 另外一些诸如权限表之类的系统表也改用InnoDB引擎。因此在加载这些表时,创建了innodb用到的一系列线程。
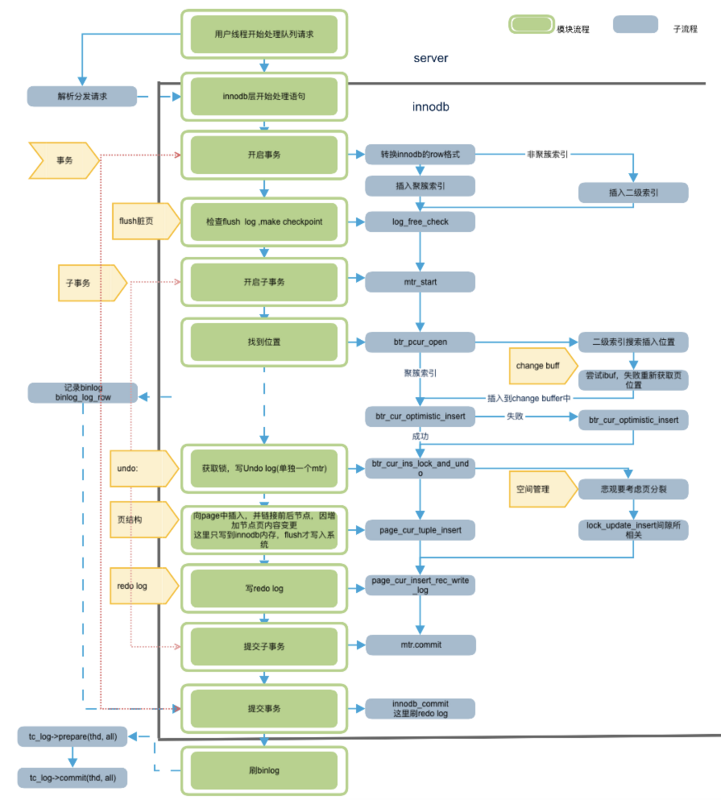
从插入流程开始
整体流程图如下:
必须有这些步骤的原因:
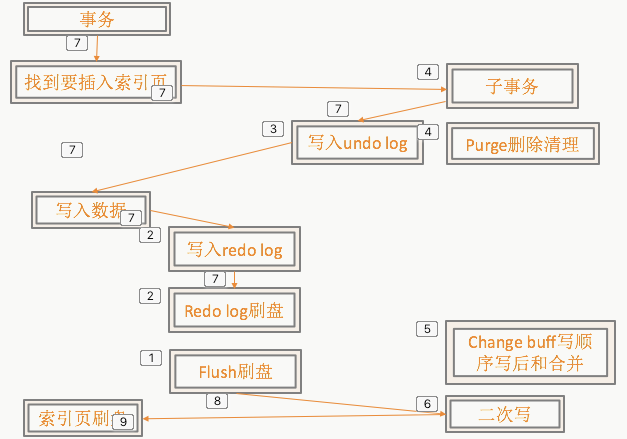
[1]为了快,所有数据先写入内存,再刷脏
[2]为了防止数据页写过程中崩溃数据的持久性=》先写redo保证重启后可以恢复。日志写不成功不操作,日志是顺序写,内容少,可以同步等。(最好是物理重做)。
[3]异常回滚=》物理回滚反解复杂,需要一个逻辑日志。
基于undo log又实现了MVCC
unlog等也要保证操作持久化原子化。
[4]为了删除不每次整理页,只标记,为了真正删除/undo不需要的清除=》purge
[5]flush对一个pageid多次操作合并在一起减少随机操作=》二级索引非唯一change buff
[6]Flush过程中一个页部分写成功就崩溃,无法正确后恢复=》二次写
[7]为完整的主链路。
[8]为异步的刷盘链路
详细步骤:
外层 handle_connection=>do_commannd=>dispatch_command=>mysql_parse=>mysql_execute_commannd=>sql_cmd_dml::execute=> execute_inner while{对每条记录执行write_record} =>ha_write_row【返回到这里不出错记录binlog】,调用引擎table->file->ha_write_row(table->record[0])
引擎层:
row_insert_for_mysql_using_ins_graph开始,有开启事务的操作,trx_start_low。
首先,需要分配回滚段,因为会修改数据,就需要找地方把老版本的数据给记录下来,其次,需要通过全局事务id产生器产生一个事务id,最后,把读写事务加入到全局读写事务链表(trx_sys->rw_trx_list),把事务id加入到活跃读写事务数组中(trx_sys->descriptors)
在InnoDB看来所有的事务在启动时候都是只读状态,只有接受到修改数据的SQL后(InnoDB接收到才行。因为在start transaction read only模式下,DML/DDL都被Serve层挡掉了)才调用trx_set_rw_mode函数把只读事务提升为读写事务。
之后开始事务内部处理。图中所示,细节很多,先不写了。
第二章 性能
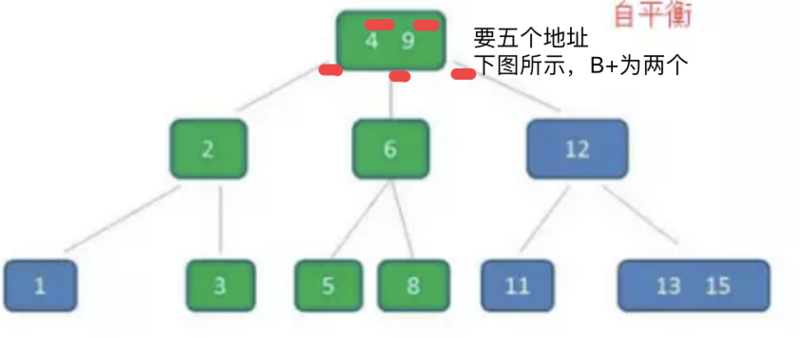
磁盘,B+树
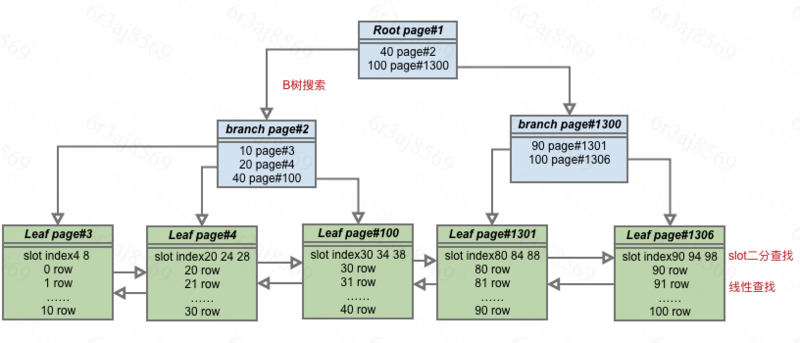
准确的B+比B为何更适合?
区别两点,一个是B树搜索是可以止于非页节点的,包含数据(包含数据在磁盘中页的位置),且数据只出现在树中一次。另一点是叶子节点有双向链表。第一点使得节点可以包含更多路(因为不存数据在磁盘中页的位置,只包含下一层的指针页位置,B树这两个都要包含),层高会更少;只能到页节点搜索结束,性能稳定。第二点为了扫描和范围索引。
内存buffer
所有数据页。都走这套。包括undo等
name
desc
buf_pool_t::page_hash
page_hash用于存储已经或正在读入内存的page。根据快速查找。当不在page hash时,才会去尝试从文件读取
buf_pool_t::LRU
LRU上维持了所有从磁盘读入的数据页,该LRU上又在链表尾部开始大约3/8处将链表划分为两部分,新读入的page被加入到这个位置;当我们设置了innodb_old_blocks_time,若两次访问page的时间超过该阀值,则将其挪动到LRU头部;这就避免了类似一次性的全表扫描操作导致buffer pool污染
buf_pool_t::free
存储了当前空闲可分配的block
buf_pool_t::flush_list
存储了被修改过的page,根据oldest_modification(即载入内存后第一次修改该page时的Redo LSN)排序
buf_pool_t::flush_rbt
在崩溃恢复阶段在flush list上建立的红黑数,用于将apply redo后的page快速的插入到flush list上,以保证其有序
buf_pool_t::unzip_LRU
压缩表上解压后的page被存储到unzip_LRU。 buf_block_t::frame存储解压后的数据,buf_block_t::page->zip.data指向原始压缩数据。
buf_poo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









