







数据分析是以数据统计为基础的,而在数据统计之前,需要对收集到的数据进行清洗,得到有效的数据,以保证数据统计的准确性。本文以某医院的药品销售数据为例,对从数据清洗到计算出月均消费次数、月均消费金额和客单价这三个指标的过程进行详细描述,希望对学习使用Python进行数据统计的小伙伴有所参考。
一、数据清洗。数据清洗一般分为常规清洗与业务指标清洗。常规清洗包含变更列名、变更数据类型与空值处理。业务指标清洗是指根据对统计指标的理解所作的必要清洗,常见的有异常值处理和去重清洗这两种。
(一)常规清洗
1. 读取数据。数据文件是xlsx格式,放在本地D盘,此次读取的是Sheet1工作表,并将数据集命名为CYsalsDf。
fileNameStr = 'D:/朝阳医院2018年销售数据.xlsx'
xls = pd.ExcelFile(fileNameStr, dtype = 'object')
CYsalsDf = xls.parse('Sheet1', dtype = 'object')
运行之后报错了。不要着急,快速浏览报错信息,NameError告诉我们语句中的pd没有定义,初步判断应该是没有导入pandas库导致报错。
import pandas as pd导入pandas库之后,再运行读取文件的代码就正常了。
2. 查看数据表头。通过以下代码,我们知道文件表头包含7个字段,及数据前5行的字段内容,由此我们对数据有了初步的了解。
CYsalsDf.head()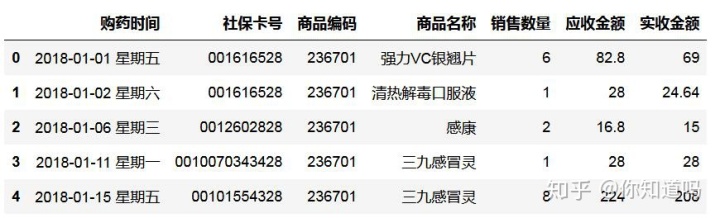
3. 变更列名。为了方便理解,我们把购药时间修改为销售时间。
colNameDict = {
'购药时间' : '销售时间'}
CYsalsDf.rename(columns = colNameDict, inplace = True)
4. 查看数据类型。数据字段全部是object类型,但根据我们的观察,销售数量、应收金额与实收金额这三个字段应该数值类型或者浮点数类型。
CYsalsDf.dtypes 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









