






笔者把自己这篇原本发布在github page上的文章迁移到了这里,原github page网址:https://iceflameworm.github.io/2019/12/04/pdfplumber-table-extraction-3/
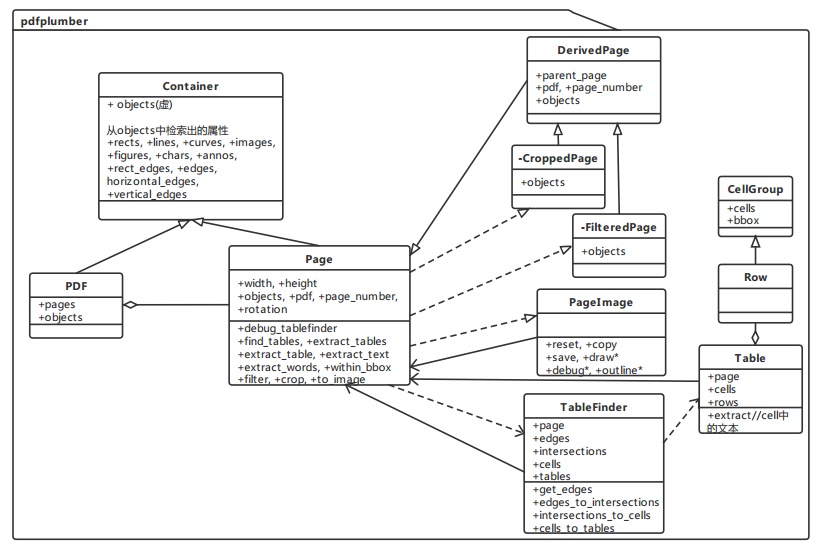
pdfplumber是一款完全用python开发的pdf解析库,对于线框完全的表格,pdfminer能给出比较好的抽取效果,但是对于线框不完全(包含无线框)的表格,其效果就差了不少。因为在实际项目所需处理的pdf文档中,线框完全及不完全的表格都比较多,所以为了能够理解pdfplumber实现表格抽取的原理和方法,找到改善、提升表格抽取效果的方法,这里对pdfplubmer的代码逻辑进行了梳理。由于所涉及的内容比较多,所以计划分为三部分进行整理:1. 介绍pdfplumber及其表格抽取流程, 2. 梳理pdfplumber表格线检测逻辑, 3. 梳理pdfplumber表格生成逻辑。本文是第三部分。
- 背景介绍
- 自底向上的方法
- 生成单元格
- 生成表格
- 存在的问题
背景介绍
最近在做一个表格信息抽取的项目,该项目需要从pdf文件中找到的目标表格,并把目标表格中需要的行和列给抽取出来。由于项目中pdf扫描件占比相对较少(不太到10%吧),所以目前主要把精力花在可编辑pdf文件的表格抽取上。
即便是可编辑的pdf文件,从中抽取表格也不是一件容易的事情,概括起来,难在以下几点:
- 与其说pdf是一种数据格式,不如说它是一组打印指令的集合,因为pdf文件保存的只是一条条打印指令,这些指令告诉pdf阅读器或打印机该在屏幕或者纸张的什么位置显示什么样的符号。与docx和html等格式的文件不同(docx和html通过标签的方式组织不同的逻辑结构,比如<table>, <w:tbl>, <p>, <w:p>等),pdf文件不包含任何逻辑结构的信息,比如段落、句子、单词、表格等等。在pdf文档中,即便在阅读器中能看到
table-like的东西,但是却无法直接有效地把这些视觉上table-like的东西所对应的数据给抽取出来。 - 除了不会保存逻辑结构信息之外,pdf往往也不会保存空格、制表符、回车等不可见字符,所以在pdf中无法像在docx中一样,通过制表符来定位不是用线框表示的表格。
为了从pdf中比较好的抽取表格,作者调研、尝试了许多开源的框架(不限于python开发的框架),包括微软开源的深度学习表格检测与识别模型TableBank。尝试了一圈下来,在基于python的框架中,pdfplumber和camelot的效果相对较好。对于线框完全的表格,二者都能给出比较好的抽取效果,但是对于线框不完全(包含无线框)的表格,二者的效果就差了不少。
因为在项目所需处理的pdf文档中,线框完全及不完全的表格都比较多,所以为了能够理解pdfplumber实现表格抽取的原理和方法,找到改善、提升表格抽取的方法,作者在这里对pdfplubmer的代码逻辑进行了梳理。由于所涉及的内容比较多,所以计划分为三部分进行整理,分别是:
- pdfplumber是怎么做表格抽取的(一):介绍pdfplumber及其表格抽取流程
- pdfplumber是怎么做表格抽取的(二):梳理pdfplumber表格线检测逻辑
- pdfplumber是怎么做表格抽取的(三):梳理pdfplumber表格生成逻辑
本文是第三部分。
自底向上的方法
在找到了可能的表格线以及这些线的交点之后,接下来就是根据线和交点找到并识别出可能存在的表格。pdfplumber采用了一种自底向上的方式,先根据线和交点找到可能存在的单元格,然后在把连通在一起的单元格组合成一个表格。
生成单元格
pdfplumber.table.TableFinder类调用同一模块下的intersections_to_cells函数,根据前面找到的线和交点找出可能存在的单元格。下面是intersections_to_cells函数的代码,据代码所示,生成单元格主要包含以下几步:
- 首先对所有交点按照自左向右、自上向下的方式排序。
- 找到以每个交点作为左上角的最小的单元格。因为对输入的交点进行了排序,所以返回的单元格应该也是相同的顺序排序的。
def intersections_to_cells(intersections):
"""
Given a list of points (`intersections`), return all retangular "cells" those points describe.
`intersections` should be a dictionary with (x0, top) tuples as keys,
and a list of edge objects as values. The edge objects should correspond
to the edges that touch the intersection.
"""
def edge_connects(p1, p2):
def edges_to_set(edges):
return set(map(utils.obj_to_bbox, edges))
if p1[0] == p2[0]:
common = edges_to_set(intersections[p1]["v"])
.intersection(edges_to_set(intersections[p2]["v"]))
if len(common): return True
if p1[1] == p2[1]:
common = edges_to_set(intersections[p1]["h"])
.intersection(edges_to_set(intersections[p2]["h"]))
if len(common): return True
return False
points = list(sorted(intersections.keys()))
n_points = len(points)
def find_smallest_cell(points, i):
if i == n_points - 1: return None
pt = points[i]
rest = points[i+1:]
# Get all the points directly below and directly right
below = [ x for x in rest if x[0] == pt[0] ]
right = [ x for x in rest if x[1] == pt[1] ]
for below_pt in below:
if not edge_connects(pt, below_pt): continue
for right_pt in right:
if not edge_connects(pt, right_pt): continue
bottom_right = (right_pt[0], below_pt[1])
if ((bottom_right in intersections) and
edge_connects(bottom_right, right_pt) and
edge_connects(bottom_right, below_pt)):
return (
pt[0],
pt[1],
bottom_right[0],
bottom_right[1]
)
cell_gen = (find_smallest_cell(points, i) for i in range(len(points)))
return list(filter(None, cell_gen))生成表格
pdfplumber.table.TableFinder类调用同一模块下的cells_to_tables函数,根据前面找到的单元格,把连通的单元格合并到一起生成对应的表格。下面是cells_to_tables函数的代码,需要注意的是,入参cells也是按照自左向右、自上向下排过序的。
def cells_to_tables(cells):
"""
Given a list of bounding boxes (`cells`), return a list of tables that hold those those cells most simply (and contiguously).
"""
def bbox_to_corners(bbox):
x0, top, x1, bottom = bbox
return list(itertools.product((x0, x1), (top, bottom)))
cells = [ {
"available": True,
"bbox": bbox,
"corners": bbox_to_corners(bbox)
} for bbox in cells ]
# Iterate through the cells found above, and assign them
# to contiguous tables
def init_new_table():
return { "corners": set([]), "cells": [] }
def assign_cell(cell, table):
table["corners"] = table["corners"].union(set(cell["corners"]))
table["cells"].append(cell["bbox"])
cell["available"] = False
n_cells = len(cells)
n_assigned = 0
tables = []
current_table = init_new_table()
while True:
initial_cell_count = len(current_table["cells"])
for i, cell in enumerate(filter(itemgetter("available"), cells)):
if len(current_table["cells"]) == 0:
assign_cell(cell, current_table)
n_assigned += 1
else:
corner_count = sum(c in current_table["corners"]
for c in cell["corners"])
if corner_count > 0 and cell["available"]:
assign_cell(cell, current_table)
n_assigned += 1
if n_assigned == n_cells:
break
if len(current_table["cells"]) == initial_cell_count:
tables.append(current_table)
current_table = init_new_table()
if len(current_table["cells"]):
tables.append(current_table)
_sorted = sorted(tables, key=lambda t: min(t["corners"]))
filtered = [ t["cells"] for t in _sorted if len(t["cells"]) > 1 ]
return filtered据代码所示,生成表格主要包含以下几步:
- 对单元格的bbox进行处理,生成四个角的坐标
- 根据可用单元格四个角的坐标判断单元是否属于当前正在生成的表格。
- 当单元格与当前正在生成的表格相交时,把该单元格加入到当前表格中,以后该单元格就不再可用了。
- 当没有单元格可以加入到当前生成的表格的时候,保存该表格,并把当前正在生成的表格设成空表格,判断剩下可用的单元能够加入到当前表格中。
- 当所有单元格都加入到某一表格之后,停止这一过程。
- 按照表格的左上角坐标进行排序。
- 过滤掉那些过小的表格。
- 把剩下的表格封装到
pdfplumber.table.Table类的实例对象,Table类中的extract方法可以根据表格、单元格以及字符的位置,抽取出位于表格及其各个单元格内部的文本,最后以行的形式返回出来。
下面就是Talbe类的代码
class Table(object):
def __init__(self, page, cells):
self.page = page
self.cells = cells
self.bbox = (
min(map(itemgetter(0), cells)),
min(map(itemgetter(1), cells)),
max(map(itemgetter(2), cells)),
max(map(itemgetter(3), cells)),
)
def rows(self):
_sorted = sorted(self.cells, key=itemgetter(1, 0))
xs = list(sorted(set(map(itemgetter(0), self.cells))))
rows = []
for y, row_cells in itertools.groupby(_sorted, itemgetter(1)):
xdict = dict((cell[0], cell) for cell in row_cells)
row = Row([ xdict.get(x) for x in xs ])
rows.append(row)
return rows
def extract(self,
x_tolerance=utils.DEFAULT_X_TOLERANCE,
y_tolerance=utils.DEFAULT_Y_TOLERANCE):
chars = self.page.chars
table_arr = []
def char_in_bbox(char, bbox):
v_mid = (char["top"] + char["bottom"]) / 2
h_mid = (char["x0"] + char["x1"]) / 2
x0, top, x1, bottom = bbox
return (
(h_mid >= x0) and
(h_mid < x1) and
(v_mid >= top) and
(v_mid < bottom)
)
for row in self.rows:
arr = []
row_chars = [ char for char in chars
if char_in_bbox(char, row.bbox) ]
for cell in row.cells:
if cell == None:
cell_text = None
else:
cell_chars = [ char for char in row_chars
if char_in_bbox(char, cell) ]
if len(cell_chars):
cell_text = utils.extract_text(cell_chars,
x_tolerance=x_tolerance,
y_tolerance=y_tolerance).strip()
else:
cell_text = ""
arr.append(cell_text)
table_arr.append(arr)
return table_arr存在的问题
最后了,提一下在使用pdfplumber过程中遇到的问题吧,应该会随着使用的深入不断补充,如果不懒的话 ^_^
- 在用文本对齐的方式猜测可能存在的不可见的表格线的时候,整个过程是在整个页面上展开的,不会排除那些某一坐标对齐,但是相隔比较远的文本块,这样会导致:
- 在pdfplumber找到的左对齐、右对齐以及居中对齐的文本块中,某些文本块在竖直距离上相隔比较远,直观上或经验上讲,这些文本块虽然在水平位置上是对齐的,但是却不应该位于同一格表格的某一列中。
好了,都写完啦 ^_^















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









