






MySQL作为当前最流行的关系型数据库,在各个行业的系统中扮演着最重要的角色。随着大家对数据价值认可的逐步加深,数据的可靠性是最常被问到的一个问题。MySQL是如何保证数据可靠性的?京东智联云RDS-MySQL又做了哪些优化和新特性来保证用户数据的可靠性和一致性?本篇文章将为大家一一揭秘。
MySQL如何保证数据可靠性
MySQL的Innodb存储引擎支持ACID(原子性Atomicity,一致性Consistency,隔离性Isolation,持久性Durability)特性,正是因为保证了一致性和持久性,所以数据才是可靠的。很多关系型数据库为保障数据库的可靠性,同时最大限度地提升性能,采用了预写日志(Write-Ahead Logging)的方法,MySQL也不例外。它将数据变化先写入日志,然后立刻返回给客户端更新成功,真正的数据再异步更新到磁盘的数据文件。如果中间系统发生故障,只要日志在数据就不会丢失,这就保证了数据的可靠性。
MySQL写入的日志就是binlog和redo log文件,下面我们来介绍下两种日志的写入流程。
binlog写入机制
事务执行过程中,MySQL会将所有变更记录到binlog cache中,在事务commit的时候一起写入binlog文件中。
binlog cache是由参数binlog_cache_size控制,默认32KB,如果事务很大,变更内容超过了binlog cache,则会写到磁盘中。通过命令show global status like 'Binlog_cache_disk_use';可以查看binlog cache写入磁盘的次数,如果数量过多,建议调大binlog_cache_size参数值。
每个线程都会分配binlog cache,但是都共用一份binlog文件。流程图如下:
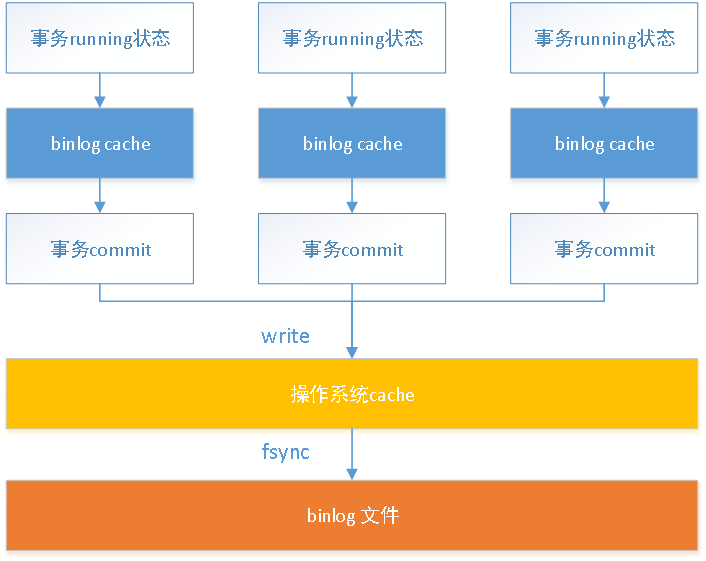
在写入到系统的日志文件中有两个步骤,write和fsync。wirte是写入操作系统的缓存,fsync是持久化到磁盘文件,这个操作会占用系统的IOPS,而它们操作的时机是通过参数sync_binlog控制。
l sync_binlog=0,事务提交时,只做write操作,由操作系统自己控制fsync操作。这个是最危险的,一旦操作系统宕机,binlog cache中的变更内容全部会丢失。
l sync_binlog=1,事务提交时,都会做write和fsync操作。安全性最高,但是性能损耗也是最大的。
l sync_binlog=N,事务提交时,会做write操作,累积N个事务时做fsync操作。一旦操作系统宕机,会丢失binlog cache中部分变更内容。
redo log写入机制
事务执行过程中,也是先写入内存redo log buffer中,然后再写入到磁盘文件。其中redo log buffer是所有线程共用的。与binlog写到文件一样,写redo log也有write和fsync两个操作,它们操作的实际是通过参数innodb_flush_log_at_trx_commit控制。
l innodb_flush_log_at_trx_commit=0,事务提交时,只将变更内容写到redo log buffer,由后台Master线程每秒write和fsync到磁盘文件。
l innodb_flush_log_at_trx_commit=1,事务提交时,执行write和fsync操作。这是最安全的配置。
l innodb_flush_log_at_trx_commit=2,事务提交时,只执行write操作,即只写到操作系统的缓存中,由后台Master线程每秒fsync到磁盘文件。
关于这个参数与数据可靠性之间的关系如下表所示:
innodb_flush_log_at_trx_commit
数据库进程异常
操作系统异常
0
丢失最多1s的数据
丢失最多1s的数据
1
不丢数据
不丢数据
2
不丢数据
丢失最多1s的数据
参数sync_binlog=1与innodb_flush_log_at_trx_commit=1就是DBA常说的“双1”配置,也是线上环境数据最安全最可靠的配置。
再对比下binlog和redo log的不同之处:
binlog
redo log
记录者
MySQL server
Innodb引擎
记录时间
事务commit的时候
多种条件触发,随时记录
记录内容
逻辑日志
row格式或者statement格式
物理日志
数据页的变化,幂等的
两阶段提交
binlog和redo log是如何配合起到数据可靠性的作用呢,就不得不提到两阶段提交。它可以保证binlog和redo log的数据一致性。下图是事务提交时两个日志的记录流程:

如果在此过程中出现系统异常,每个状态下都是可以保证数据一致性的。
状态
处理
如果innodb已经commit,那binlog一定有该事务的event。
事务是一致性的,无需处理。
如果innodb已经prepare,binlog已经有记录该事务的event,但是innodb未commit。
前滚,innodb需要继续提交这些事务。
如果innodb已经preprare,binlog没有记录event,说明从库也没有复制这些event。
回滚。
如果innodb未完成prepare,binlog也应该没有记录event。
回滚。
innodb_suport_xa参数,这个参数控制是否打开两段式提交。默认开启,如果关闭了,事务则会以不同顺序的方式写入binlog。如果宕机恢复、xtarbackup恢复,都是会有数据不一致的风险。这个参数在MySQL5.7.10后就废弃了,必须开启。
MySQL集群数据的一致性
MySQL发展到现在,集群也从主备异步复制、半同步复制、group replication不断发展和演变。但是它们的核心基础都是binlog,可以说MySQL的数据复制都依赖于它,而集群间的数据一致性更是与binlog有关。主要有两个点需要特别注意。binlog的格式。statement、row和mixed。statement格式直接将SQL语句记录在binlog文件中,因为主从库是两个独立的服务,运行环境完全不同,所以会出现不一致的风险,比如执行delete from t limit 100。所以线上环境建议使用row格式。
数据延迟。当从库出现延迟,会造成集群数据不一致。从库延迟的原因很多,这里列举以下几个线上经常出现的延迟原因:
a) 大事务。binlog只有在事务commit时才会记录到文件,然后从库才能读取到数据变更,所以当有大事务的时候,主库提交后从库才开始执行。
b) 大并发。5.6和5.7版本都支持并行复制,但是并行度有限,当主库并发较高时,从库会出现延迟。
c) 表结构。主库表没有主键,binlog是row格式的,主库执大量行数的更新SQL时,从库会执行多次全表扫描,造成延迟。
d) 等待锁。从库一般会承担备份功能,使用xtrabackup进行备份会执行FLUSH NO_WRITE_TO_BINLOG TABLES和FLUSH TABLES WITH READ LOCK操作,在特殊情况下,这两个操作会堵塞复制的SQL线程,造成延迟。
e)
京东智联云RDS-MySQL数据安全的实现
京东智联云RDS-MySQL集群使用主从复制架构,为了保证用户存储数据可靠性和安全性,我们对关键流程做了一系列优化和改善工作。以用户数据安全为己任,以用户体验为中心。
集群环境物理环境
l 硬件,采用高性能的NVME硬盘,最新型号物理机配置。
l 网络,跨AZ机器的网络延迟在1.2ms以内,配置万兆网卡。软件环境
l 数据面,参考京东高并发、高可靠的业务系统优化经验,京东智联云对RDS操作系统配置、MySQL参数配置做了一些列优化,保证数据库集群数据的可靠性。
l 控制面,针对集群的延迟,有多组延迟监控、报警;针对不同延迟原因,会触发不同的优化逻辑,自动降低延迟。
高可用切换
当物理机出现问题或者做数据迁移时,都会涉及MySQL集群的高可用操作,因为MySQL集群的复制特点,有可能会出现数据丢失的情况。京东智联云RDS-MySQL在切换时是要保证用户数据一致性优先的,在判断集群数据完全可靠的情况下,再做切换操作,保证用户的数据不丢失,不写花。
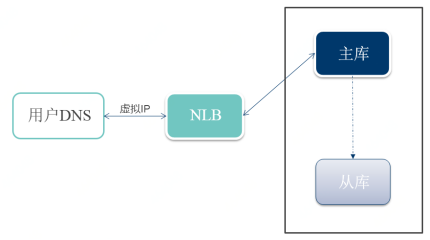
主备切换逻辑图
MySQL高可用切换流程的复杂性,不在切换的过程,而是触发切换条件的判断,下面介绍下RDS-MySQL自动高可用切换的判断流程。哨兵服务检查数据库和操作系统状态,发现实例服务异常,则触发多组哨兵服务的数据库服务检查和投票机制,确认服务真实不可用再进行切换流程。
主库实时上报GTID信息,如果发生自动高可用,即主库服务不可用时,首先会对比从库的Retrieved_Gtid_Set值,确保从库的IO thread已经拉取了主库全部的binlog内容。
然后再对比从库的Retrieved_Gtid_Set和Executed_Gtid_Set范围值,保证从库拉取的binlog全部应用完成。
高可用流程切换完成后,会对集群数据做一致性校验,并触发建立新从库的流程。
备份恢复
数据库备份是数据安全的最重要屏障,当出现极端情况下,集群所有节点的数据都不可用,就需要依赖备份保证数据的可靠性和安全性。我们对RDS-MySQL的备份、恢复流程做了一系列优化,保证用户系统在灾备时恢复时间尽量短,恢复数据尽可能最新。每日全量备份,实时binlog备份;
所有备份上传到对象存储,多备份保存,多区域存放;
定期做备份数据的有效性验证;
高可用、扩容、删除等重要流程强制做数据库的数据备份;
支持软删除功能,单库表恢复功能。
用户案例
京东智联云RDS-MySQL的用户在使用过程中,出现过很多数据可靠性相关的案例,下面举一些典型案例来分享:
案例1. 大事务造成从库延迟
问题
由于用户并发较大,集群从库出现延迟。
发现
从库对于用户是不可见的,所以从库延迟用户是无需感知的。
通过后台的监控系统,触发从库延迟报警,运维人员才发现这个问题。
解决
后台任务会扫描所有报警信息,当扫描到延迟报警后,会结合该实例的其他信息定位故障原因,然后自动调整集群数据库配置,达到降低延迟的目的。延迟报警解除后,恢复集群配置。
意义
RDS-MySQL部分报警已经实现了“负载异常检测”、“自动诊断”、“线上配置优化”、“优化效果跟踪”的闭环处理。
可帮助用户快速、安全、准确地处理集群数据安全隐患。
案例2. 用户误删除表
问题
用户因为人为误操作,导致删除了线上系统的部分数据。
发现
用户提工单,想快速恢复删除表的数据到指定时间点。
解决
控制台提供单库、单表按时间点快速恢复的功能。技术服务人员直接反馈给用户该功能的使用文档。用户通过自助操作,完成对删除数据的恢复操作。
意义
RDS-MySQL将备份和恢复功能用到极致,两类备份方式对应多种恢复流程,方便用户快速、安全地实现恢复数据库需求。
RDS-MySQL恢复流程支持:根据时间点创建
根据时间点单库、单表本地恢复
根据备份创建和本地覆盖恢复
通过上述内容,想必大家已经对MySQL是如何保证数据可靠性有了初步了解,如果还想进一步体验体验MySQL 服务,请点击【阅读原文】链接体验试用。
原文链接:














 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









