






TDOA(Time Difference of Arrival,到达时间差)是一个在语音前端信号处理中很常见的名词,和它比较相像,也同样重要的还有一个DOA(Direction of Arrival,到达方向)。在麦克风拓扑结构已知的情况下,两者可以相互转换。TDOA表示不同通道之间语音信号的延迟程度,是一个相对的概念,一般用$\tau$表示。最简单的beamforming方法delay and sum中的delay针对的就是它。DOA表示信号源相对麦克风的到达角度,一般用$\theta$表示,如果是线阵的话,范围在0到180度之间。如下图所示,假设麦克风1和麦克风2之间的距离为$\delta$,DOA为$\theta_d$,声速$c$,那么$\tau_{12}$可以有简单的数学计算得到:
那么DOA/TDOA这个信息怎么用呢?个人觉得可以从下面几个角度理解:
如果目标声源只有一个,外加一些环境噪声,那么TDOA可以用来指导beamformer对该方向的信号进行增强。
如果存在多个说话人,且说话人的方位不同,比如圆桌会议这种,那么:估计的TDOA的数目可以认为是说话人的数量(speaker counting)
通过跟踪TDOA的变化,追踪特定的说话人
对同一段语音,对估计的DOA方向进行增强,增强说话人
当然现实可能不会这么理想,如果说话人距离较远,说话人方向重合,以及环境复杂(噪声,混响)情景下,都会使得估计方法失效或者beamformer不理想等等。鸡尾酒会问题确实是语音这块一个非常难啃的骨头。现在学术界比较流行的一种Blind的方法就是在不知道声源信息和阵列拓扑的情况下,通过一些先验,或者概率模型估计beamforming中的统计量进行计算,我做过的有CGMM,NN-mask+MVDR/GEV等等,在一些数据集上(比如CHiME4)也取得了很好的效果。
在这里我主要说一个最简单的TDOA估计方法,GCC-PHAT。
首先说一下互相关(CC,Cross-Correlation)。信号处理中,互相关可以用来描述两个信号之间的相似性。离散信号$x_k, y_k$的互相关函数定义为:
从上式可知,CC是相对延时$t$的一个函数,显然,可以取使得互相关系数最大的延时值作为TDOA的估计,即:
现在普遍认为,这种算法在实际中容易受到噪声和混响的影响,表现不是很稳定,因此引入了广义互相关的概念(GCC,Generalized Cross-Correlation)。和CC一样,TDOA通过获得最大化GCC函数的延迟值得到:
其中$\widehat{R}^{xy}_t $定义为generalized cross-spectrum的IDTFT:
$\gamma_f$为频域的权重方程,$\phi_f^{xy}$表示cross-spectrum,定义为$E[X_fY_f^*]$,$*$表示共轭。如果将$\gamma_f$定义为$\frac{1}{|\phi_f^{xy}|}$,那么这种估计方法称为为GCC-PHAT。PAHT表示phase transform,因为做了幅值的归一化之后,相当于只留下了相位信息。
语音信号处理中,我们通常在短时频域上进行。在每一帧上,进行一次$\widehat{R}^{xy}_\tau$计算,可以得到所谓的angular spectrogram:
其中$H_{tf} = X_{tf} \odot Y_{tf}^*$,$\overline{H_{tf}}$表示做幅值归一化。实际计算中,构建矩阵$\varOmega \in R^{\varTheta \times F}$,使得
之后计算矩阵乘法$\varPsi =\overline{H} \varOmega$即可。下面贴一段我写的可视化angular spectrogram的程序,旨在说明计算逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64#!/usr/bin/env python
# coding=utf-8
# wujian@2018
import argparse
import glob
import numpy as np
import matplotlib.pyplot as plt
import utils
speech_speed = 340.29
distance_of_mic = 1
samp_frequency = 16000
def compute_stft(wave_path, frame_length, frame_shift):
wave_samp = utils.audio_read(wave_path)
return utils.stft(wave_samp, frame_length, frame_shift)
def compute_angspect(coherence, num_tdoa):
"""
coherence: num_bins x num_frames
return num_tdoa x num_frames
"""
# num_bins x num_toda
num_bins, num_frames = coherence.shape
max_tdoa = distance_of_mic / speech_speed
# from 0 to 180
est_tdoa = np.linspace(-max_tdoa, max_tdoa, num_tdoa)
sep_freq = np.linspace(0, samp_frequency / 2, num_bins)
# num_tdoa x num_bins
exp_part = np.outer(2j * np.pi * est_tdoa, sep_freq)
return np.dot(np.exp(exp_part), coherence).real
def run(args):
stft = [compute_stft(wave, args.frame_length, args.frame_shift) for wave in sorted(glob.glob(args.pattern))]
assert len(stft) == 2, 'Check pattern {} please'.format(args.pattern)
coherence = stft[0] * stft[1].conj() / (np.abs(stft[0]) * np.abs(stft[1]))
angspect = compute_angspect(coherence, args.num_tdoa)
angspect[angspect < 0] = 0
plt.subplot(211)
plt.ylabel('TDOA index')
plt.xlabel('Frame index')
plt.title('GCC-PATH Angular Spectrogram')
plt.imshow(angspect, cmap=plt.cm.binary, aspect='auto', origin='lower')
plt.subplot(212)
plt.ylabel('Frequency index')
plt.xlabel('Frame index')
plt.title('Log-Magnitude Spectrogram')
plt.imshow(np.log(np.abs(stft[0])), cmap=plt.cm.jet, aspect='auto', origin='lower')
plt.show()
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Command to compute angular spectrogram using GCC-PHAT methods")
parser.add_argument('pattern', type=str, help='location of 2-channel wave files')
parser.add_argument('--num-of-tdoa', type=int, default=128, dest="num_toda",
help='Number of todas to estimate')
parser.add_argument('--frame-shift', type=int, default=256, dest="frame_shift",
help='Frame shift in number of samples')
parser.add_argument('--frame_length', type=int, default=1024, dest="frame_length",
help='Frame length in number of samples')
args = parser.parse_args()
run(args)
注:程序无法完整运行,utils.py我未给出。
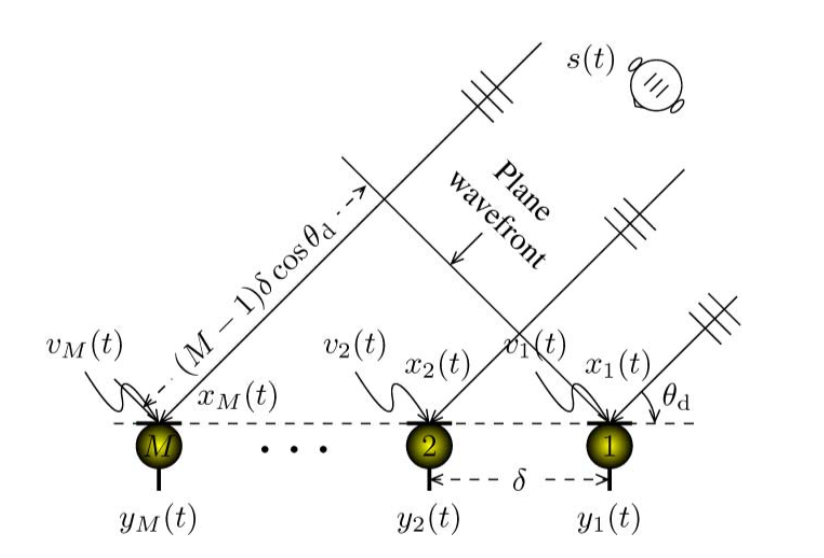
在一些比较理想或者simulate的数据下,这种方法work的很好,这部分例子可以参见“Blind Speech Separation and Enhancement With GCC-NMF ”这系列论文以及github。实际的数据中,表现还是差强人意的,我在实录的数据上只在部分条件下(比如说话人距离麦克风较近等等)可以提供较为准确的TDOA估计信息。比如下面几种情况:
上图中的angular spectrum中在index-80的位置,在时间轴上出现几段较为明显的峰值,由此可以得到以下信息:
峰值出现的所在的index即为估计的最佳TDOA索引。
峰值不连续处表示该说话人尚未说话(起到类似VAD的作用)。
峰值所对应的index分布向着90处移动,说明该说话人可能相对麦克风在移动。
如果在不同index处,同时出现峰值,那么就说明存在多个说话人,比如下面这种情况,可以认为在这段语音中,可能存在三个说话人。
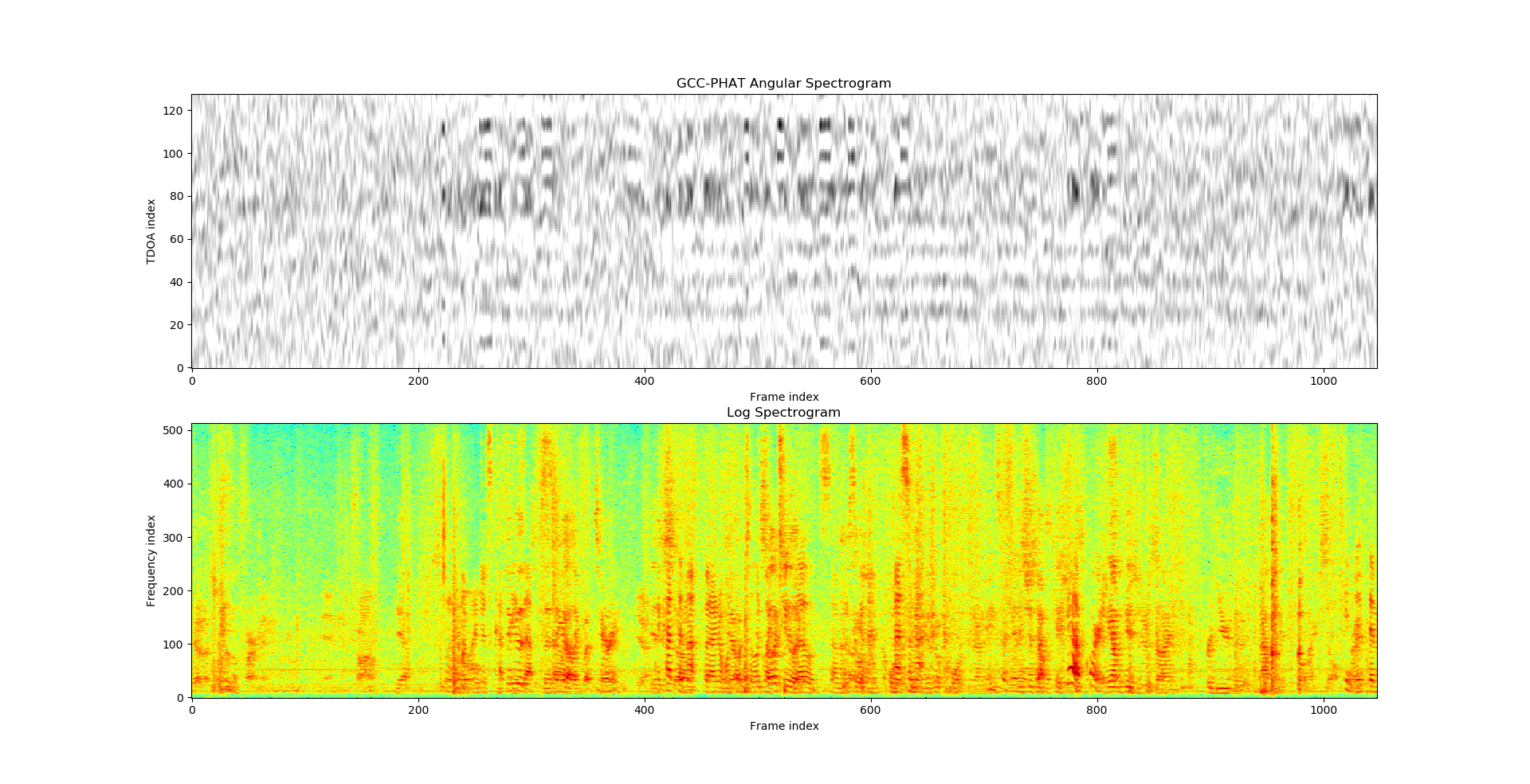
GCC-PHAT方法的局限性还表现在仅仅只能依据两路信号进行估计。如果现在有多路麦克风,那么就需要在原有算法的基础上进行改进。这部分由于我还没有具体的实践,暂时无法继续深入。
之前也提到过,Blind的方法目前已经摆脱对具体TDOA/DOA的依赖的,以MVDR beamformer为例子,往往会用noise的协相关矩阵的最大特征值作为steer vector的估计。而在传统的信号处理中,TDOA是形成steer vector不可或缺的一个因素,假如已经计算出相对延迟序列$\tau_1, \tau_2, \cdots, \tau_{N-1}$,那么steer vector为:
在beamformer设计中很重要的一个东西是beam pattern,在我们做Blind Source Separation/Enhancement的时候,往往会忽视这个分析手段,只看重最终的WER,在后面我会开一篇文章,介绍使用TDOA进行beamformer,以及使用beam pattern进行分析的方法。什么时候更呢……等哪天准备工作做得充分了吧。















 2157
2157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









