 JavaScript洋葱模型设计与实现解析
JavaScript洋葱模型设计与实现解析








简介:JavaScript洋葱模型是一种通过高阶函数组织业务逻辑的设计模式,结构类似洋葱,层与层之间通过组合函数依次调用,提升代码的模块化、可维护性和可测试性。文章详解了如何使用函数组合实现洋葱结构,包括模块划分、状态管理、错误处理等内容,并结合示例代码讲解了从外到内再向外的执行流程,适合中高级前端开发者深入理解函数式编程在架构设计中的应用。
1. 洋葱模型架构简介
在现代前端架构设计中,洋葱模型(Onion Architecture)作为一种分层解耦、高内聚低耦合的架构模式,逐渐被广泛应用于构建可维护、可扩展的大型应用中。其核心思想是将应用逻辑层层包裹,像洋葱一样由外向内逐层递进,每一层仅与相邻层交互,确保系统的松耦合与高可测试性。
与传统的MVC或MVVM不同,洋葱模型将业务核心逻辑置于最内层,外层则负责处理诸如路由、数据库访问、UI渲染等基础设施。这种结构提升了代码的可移植性与可替换性,尤其适合长期演进的项目架构。在JavaScript生态系统中,洋葱模型常见于Node.js中间件框架(如Koa)中,为后续章节中函数式编程与中间件组合的实现提供了良好的架构基础。
2. JavaScript函数式编程基础
函数式编程(Functional Programming, FP)是现代JavaScript开发中不可或缺的编程范式之一。它强调将计算过程视为数学函数的求值过程,避免共享状态、可变数据和副作用。理解函数式编程的基础,对于掌握如洋葱模型这类现代架构设计至关重要。本章将从JavaScript语言的核心特性出发,系统讲解函数式编程的基础概念,包括函数作为一等公民、纯函数与副作用、不可变数据与状态管理、高阶函数与函数链式调用等内容,帮助读者建立函数式编程的思维方式,为后续深入理解洋葱模型架构打下坚实基础。
2.1 函数作为一等公民
JavaScript 中函数作为“一等公民”(First-class citizens)是其函数式编程能力的核心体现。函数不仅可以被赋值给变量、作为参数传递给其他函数、作为返回值从函数中返回,还能在对象中作为属性存在。
2.1.1 函数的定义与调用
JavaScript 中定义函数的方式有多种,包括函数声明、函数表达式、箭头函数等。
// 函数声明
function add(a, b) {
return a + b;
}
// 函数表达式
const multiply = function(a, b) {
return a * b;
};
// 箭头函数
const subtract = (a, b) => a - b;
// 调用
console.log(add(2, 3)); // 5
console.log(multiply(4, 2)); // 8
console.log(subtract(7, 3)); // 4
代码逻辑分析
- 第1~3行 :使用
function关键字定义了一个名为add的函数,接收两个参数a和b,返回它们的和。 - 第6~8行 :将函数赋值给变量
multiply,这种方式称为函数表达式。 - 第11~12行 :使用箭头函数定义
subtract,其语法更简洁,适用于简单的函数体。 - 第15~17行 :分别调用这三个函数并输出结果。
参数说明
-
a和b:均为数值类型,表示两个操作数。 - 返回值:根据操作返回对应的数值结果。
2.1.2 函数作为参数与返回值
函数可以作为参数传递给其他函数,也可以作为返回值返回,这是函数作为一等公民的典型特征。
// 函数作为参数
function executeOperation(a, b, operation) {
return operation(a, b);
}
const result1 = executeOperation(5, 3, add); // 8
const result2 = executeOperation(5, 3, multiply); // 15
// 函数作为返回值
function createMultiplier(factor) {
return function(number) {
return number * factor;
};
}
const double = createMultiplier(2);
const triple = createMultiplier(3);
console.log(double(5)); // 10
console.log(triple(5)); // 15
代码逻辑分析
- 第1~4行 :定义
executeOperation函数,接收两个操作数和一个操作函数operation,返回其执行结果。 - 第6~7行 :将
add和multiply函数作为参数传入executeOperation。 - 第10~13行 :定义
createMultiplier函数,返回一个新的函数,用于乘以指定的因子。 - 第15~16行 :通过调用
createMultiplier创建了两个新函数double和triple。 - 第18~19行 :调用
double和triple并输出结果。
参数说明
-
a、b:操作数,为数字类型。 -
operation:一个函数,接受两个参数并返回一个值。 -
factor:乘数因子,用于生成乘法函数。 -
number:被乘数,用于最终计算。
2.2 纯函数与副作用
函数式编程强调使用纯函数来构建应用程序。纯函数具有确定性、无副作用等特性,有助于提升代码的可测试性和可维护性。
2.2.1 纯函数的定义与特性
纯函数(Pure Function) 是指对于相同的输入始终返回相同的输出,并且不产生任何副作用的函数。
// 纯函数示例
function square(x) {
return x * x;
}
console.log(square(4)); // 16
console.log(square(4)); // 16
代码逻辑分析
- 第1~3行 :定义
square函数,接收一个数字x,返回其平方。 - 第5~6行 :两次调用
square(4),结果均为 16。
纯函数特性
| 特性 | 描述 |
|---|---|
| 输入输出一致 | 对于相同的输入,总是返回相同的结果 |
| 无副作用 | 不修改外部状态或变量 |
| 无 I/O 操作 | 不进行网络请求、日志打印、DOM 操作等 |
2.2.2 副作用的理解与避免
副作用(Side Effect) 指函数在执行过程中对外部状态造成影响,如修改全局变量、修改输入参数、执行 I/O 操作等。
let count = 0;
// 有副作用的函数
function increment() {
count++;
}
increment();
console.log(count); // 1
代码逻辑分析
- 第1行 :定义全局变量
count。 - 第4~6行 :函数
increment修改了全局变量count,属于副作用。 - 第8~9行 :调用
increment并输出结果。
如何避免副作用
- 使用函数参数代替外部变量;
- 返回新值而非修改原有数据;
- 使用不可变数据结构(如 Immutable.js)。
2.3 不可变数据与状态管理
不可变数据(Immutable Data)是函数式编程中另一个关键概念。它强调数据一旦创建就不能被修改,任何修改操作都会返回新的数据副本。
2.3.1 Immutable数据的优势
| 优势 | 描述 |
|---|---|
| 可预测性 | 数据不会被意外修改,状态变化更可预测 |
| 易于调试 | 所有状态变更都通过函数返回新值,便于追踪 |
| 避免副作用 | 减少共享状态导致的副作用 |
| 性能优化 | 可利用结构共享(Structural Sharing)减少内存占用 |
const original = { name: "Alice", age: 25 };
const updated = { ...original, age: 26 };
console.log(original); // { name: 'Alice', age: 25 }
console.log(updated); // { name: 'Alice', age: 26 }
代码逻辑分析
- 第1行 :定义原始对象
original。 - 第2行 :使用扩展运算符
...创建新对象updated,更新age属性。 - 第4~5行 :输出原始对象和更新后的对象,两者互不影响。
2.3.2 使用const与let进行变量管理
在函数式编程中,变量一旦赋值就不应再被修改。 const 是实现不可变性的首选。
const user = { name: "Bob", score: 80 };
user.score = 90; // ❌ 虽然对象引用不变,但内容可变
// 更安全的方式:创建新对象
const newUser = { ...user, score: 90 };
建议使用方式
- 使用
const声明不可变变量; - 对象或数组更新时,使用展开语法、
map、filter等函数创建新值; - 避免直接修改原对象或数组。
2.4 高阶函数与函数链式调用
高阶函数(Higher-order Function)是指接收一个或多个函数作为参数,或返回一个函数作为结果的函数。JavaScript 提供了丰富的高阶函数支持,如 map 、 filter 、 reduce 等。
2.4.1 高阶函数的定义与应用
const numbers = [1, 2, 3, 4, 5];
// map:对每个元素执行函数并返回新数组
const squares = numbers.map(n => n * n); // [1, 4, 9, 16, 25]
// filter:筛选符合条件的元素
const evens = numbers.filter(n => n % 2 === 0); // [2, 4]
// reduce:将数组元素聚合为一个值
const sum = numbers.reduce((acc, n) => acc + n, 0); // 15
代码逻辑分析
- 第1行 :定义原始数组
numbers。 - 第4~5行 :使用
map对每个元素求平方,返回新数组。 - 第8~9行 :使用
filter筛选偶数。 - 第12~13行 :使用
reduce累加数组元素,初始值为0。
参数说明
-
n:当前数组元素; -
acc:累积器,保存每次操作的结果; - 第二个参数
0:reduce的初始值。
2.4.2 函数链式调用的基本原理
链式调用是指多个高阶函数串联调用,依次对数据进行处理。
const result = numbers
.filter(n => n > 2)
.map(n => n * 2)
.reduce((acc, n) => acc + n, 0);
console.log(result); // 42
代码逻辑分析
- 第1~4行 :链式调用
filter→map→reduce: - 过滤出大于2的元素:
[3, 4, 5] - 每个元素乘以2:
[6, 8, 10] - 累加得到总和:
6 + 8 + 10 = 24
链式调用流程图(mermaid)
graph TD
A[原始数组 [1,2,3,4,5]] --> B{filter(n > 2)}
B --> C[结果 [3,4,5]]
C --> D{map(n * 2)}
D --> E[结果 [6,8,10]]
E --> F{reduce(sum)}
F --> G[结果 24]
链式调用优势
- 代码简洁、逻辑清晰;
- 数据流动过程可视化;
- 每一步都是独立函数,便于测试和复用。
本章通过函数作为一等公民、纯函数与副作用、不可变数据与状态管理、高阶函数与链式调用等核心概念,系统讲解了 JavaScript 函数式编程的基础知识。这些概念不仅是函数式编程的核心思想,也为后续章节中洋葱模型的构建与理解提供了坚实的理论基础。下一章我们将深入探讨高阶函数与函数组合的实现方式,进一步提升代码的抽象与复用能力。
3. 高阶函数与函数组合实现
在现代前端开发中,函数式编程的影响力日益增强。高阶函数作为函数式编程的核心概念之一,不仅提高了代码的抽象能力,也为函数组合提供了基础。本章将深入探讨高阶函数在数据处理与异步编程中的典型应用场景,并系统讲解函数组合的概念、实现方式,以及如何构建可复用的基础组合函数库。
函数组合(Function Composition)是一种将多个函数按顺序组合成一个新函数的技术,它使得代码更简洁、逻辑更清晰,同时也更易于测试和维护。我们将通过具体的代码示例,分析函数组合如何与洋葱模型(Onion Model)架构契合,从而实现高效的中间件处理流程。
3.1 高阶函数的典型应用场景
高阶函数是指能够接收函数作为参数或返回函数的函数。在JavaScript中, map 、 filter 、 reduce 等数组方法是典型的高阶函数,它们广泛应用于数据处理流程。此外,在异步编程中,回调函数的封装与链式调用也依赖于高阶函数的能力。
3.1.1 数据处理中的map、filter与reduce
在处理数组数据时,我们经常使用 map 、 filter 和 reduce 方法。这些方法不仅简化了代码结构,也使得数据操作更具声明式风格。
示例代码:
const numbers = [1, 2, 3, 4, 5];
// 使用 map 计算平方
const squares = numbers.map(n => n * n);
console.log(squares); // [1, 4, 9, 16, 25]
// 使用 filter 过滤偶数
const evens = numbers.filter(n => n % 2 === 0);
console.log(evens); // [2, 4]
// 使用 reduce 求和
const sum = numbers.reduce((acc, curr) => acc + curr, 0);
console.log(sum); // 15
代码逐行分析:
-
map:将数组中的每个元素通过一个函数处理后返回新数组。 -
filter:根据函数返回值为true的元素筛选出新数组。 -
reduce:通过累积器逐个处理数组元素,最终返回一个汇总结果。
优势分析:
- 可读性强 :使用函数式方法让代码更具表达力。
- 可组合性高 :这些函数可以链式调用,形成数据处理流水线。
- 易于测试 :每个函数独立且无副作用,便于单元测试。
示例:链式调用
const result = numbers
.map(n => n * n)
.filter(n => n > 10)
.reduce((acc, curr) => acc + curr, 0);
console.log(result); // 41 (16 + 25)
表格:常用高阶函数对比
| 方法名 | 作用 | 是否返回新数组 | 是否改变原数组 |
|---|---|---|---|
| map | 映射转换 | ✅ | ❌ |
| filter | 过滤符合条件元素 | ✅ | ❌ |
| reduce | 累计处理 | ❌ | ❌ |
3.1.2 异步编程中的回调封装
在异步编程中,函数经常作为回调被传递。我们可以使用高阶函数来封装这些回调逻辑,提升代码复用性和可维护性。
示例:封装异步请求
function fetchData(url, callback) {
setTimeout(() => {
const data = `Response from ${url}`;
callback(data);
}, 1000);
}
function processResponse(data) {
console.log(`Processing: ${data}`);
}
fetchData('https://api.example.com', processResponse);
代码逻辑分析:
-
fetchData是一个高阶函数,接收一个URL和一个回调函数。 - 在异步操作完成后,调用
callback(data)将结果传递给processResponse。 -
processResponse是一个独立的处理函数,用于解耦数据获取与数据处理。
使用 Promise 封装回调:
function fetchDataAsync(url) {
return new Promise((resolve, reject) => {
setTimeout(() => {
const data = `Response from ${url}`;
resolve(data);
}, 1000);
});
}
fetchDataAsync('https://api.example.com')
.then(data => {
console.log(`Processing: ${data}`);
});
优势分析:
- 结构清晰 :将异步操作封装为 Promise 或 async/await 形式,提升可读性。
- 错误处理统一 :可通过
.catch()统一处理异常。 - 组合能力强 :异步函数也可通过链式调用进行组合。
3.2 函数组合的概念与意义
函数组合(Function Composition)是一种将多个函数按顺序组合执行的技术,常用于构建数据处理流水线。其核心思想是:将函数 A 的输出作为函数 B 的输入,从而形成一个新函数。
3.2.1 组合函数的基本定义
函数组合的数学表达式为: compose(f, g) = f(g(x)) 。在 JavaScript 中,我们可以手动实现一个组合函数。
示例代码:
function compose(f, g) {
return function(x) {
return f(g(x));
};
}
function addOne(x) {
return x + 1;
}
function square(x) {
return x * x;
}
const composed = compose(addOne, square);
console.log(composed(3)); // (3^2) + 1 = 10
代码逐行分析:
-
compose函数接收两个函数f和g。 - 返回一个新的函数,该函数接收一个参数
x,先调用g(x),再将结果传给f。 -
composed(3)实际执行addOne(square(3))。
优势分析:
- 逻辑清晰 :组合函数使得函数执行顺序一目了然。
- 可重用性强 :每个函数独立,可被多次复用。
- 易于测试 :每个函数都是纯函数,便于单元测试。
3.2.2 组合函数与洋葱模型的契合点
洋葱模型的核心在于 中间件的层层嵌套 ,每个中间件处理一部分逻辑,并将控制权传递给下一层。这种结构非常适合使用函数组合来实现。
流程图:洋葱模型中的函数组合
graph TD
A[请求] --> B[中间件1]
B --> C[中间件2]
C --> D[中间件3]
D --> E[响应]
E --> D
D --> C
C --> B
B --> A
说明:
- 每个中间件是一个高阶函数,接收
next函数作为参数。 - 中间件可以决定是否调用
next(),从而控制流程。 - 函数组合可以模拟这种执行顺序,实现中间件的自动串联。
3.3 函数组合的实现方式
函数组合可以通过多种方式实现,最常见的是利用 Array.reduce 和 Array.reduceRight 来实现从右到左或从左到右的组合顺序。
3.3.1 使用 reduce 实现函数组合
示例代码:
function compose(...funcs) {
return (x) => funcs.reduceRight((acc, fn) => fn(acc), x);
}
function trim(str) {
return str.trim();
}
function toUpper(str) {
return str.toUpperCase();
}
function addPrefix(str) {
return 'PREFIX: ' + str;
}
const process = compose(trim, toUpper, addPrefix);
console.log(process(' hello ')); // PREFIX: HELLO
代码逐行分析:
-
compose接收任意数量的函数,返回一个新函数。 - 使用
reduceRight从右向左执行函数组合。 -
addPrefix(' hello ')→toUpper('PREFIX: hello ')→trim('PREFIX: HELLO')。
优势分析:
- 顺序可控 :
reduceRight确保函数从右向左执行。 - 可扩展性强 :支持任意数量函数的组合。
3.3.2 组合顺序与执行流程分析
在洋葱模型中,函数组合的顺序至关重要。通常有两种方式:
- 从左到右 :使用
reduce。 - 从右到左 :使用
reduceRight。
示例对比:
// 从右到左(推荐用于洋葱模型)
function composeRight(...funcs) {
return (x) => funcs.reduceRight((acc, fn) => fn(acc), x);
}
// 从左到右
function composeLeft(...funcs) {
return (x) => funcs.reduce((acc, fn) => fn(acc), x);
}
const processRight = composeRight(trim, toUpper, addPrefix);
const processLeft = composeLeft(addPrefix, toUpper, trim);
console.log(processRight(' hello ')); // PREFIX: HELLO
console.log(processLeft(' hello ')); // PREFIX: HELLO
表格:组合顺序对比
| 组合方式 | 执行顺序 | 示例顺序 |
|---|---|---|
| composeRight | 从右到左 | addPrefix → toUpper → trim |
| composeLeft | 从左到右 | addPrefix ← toUpper ← trim |
3.4 实践:构建基础组合函数库
为了提升开发效率,我们可以构建一个基础的组合函数库,支持常见的函数组合操作。
3.4.1 搭建可复用的高阶函数模块
我们可以将常用的函数组合逻辑封装为模块,供多个项目复用。
示例: compose.js
export function compose(...funcs) {
return (x) => funcs.reduceRight((acc, fn) => fn(acc), x);
}
export function pipe(...funcs) {
return (x) => funcs.reduce((acc, fn) => fn(acc), x);
}
export function logger(fn) {
return (...args) => {
console.log(`Calling ${fn.name} with args:`, args);
const result = fn(...args);
console.log(`Result of ${fn.name}:`, result);
return result;
};
}
使用方式:
import { compose, pipe, logger } from './compose';
const addOne = x => x + 1;
const double = x => x * 2;
const composed = compose(logger(double), logger(addOne));
console.log(composed(5)); // Calling addOne with args: [5], Result: 6, Calling double with args: [6], Result: 12
3.4.2 在项目中引入组合函数
在实际项目中,组合函数常用于中间件、数据处理、状态转换等场景。
示例:中间件组合
function middleware1(next) {
return () => {
console.log('Middleware 1 before');
next();
console.log('Middleware 1 after');
};
}
function middleware2(next) {
return () => {
console.log('Middleware 2 before');
next();
console.log('Middleware 2 after');
};
}
function final() {
console.log('Final handler');
}
const composed = compose(middleware1, middleware2)(final);
composed();
// 输出:
// Middleware 1 before
// Middleware 2 before
// Final handler
// Middleware 2 after
// Middleware 1 after
说明:
- 每个中间件接收
next函数作为参数。 - 调用
next()将控制权交给下一个中间件。 - 最终调用
final()处理请求。 - 组合顺序决定了洋葱模型的执行流程。
本章深入探讨了高阶函数的应用场景、函数组合的实现方式及其与洋葱模型架构的契合点。通过具体的代码示例和流程图分析,我们理解了如何构建可复用的组合函数库,并将其应用于项目中。这些知识将为后续构建完整的洋葱模型框架奠定坚实基础。
4. compose函数的编写与调用顺序
在洋葱模型架构中,函数组合(function composition)是构建中间件执行流程的核心机制之一。 compose 函数是这一机制的实现载体,它通过控制函数的执行顺序,实现了中间件“从外向内”再“从内向外”的双向执行路径。本章将深入探讨 compose 函数的实现原理、其在洋葱模型中的作用、调试与优化方法,并最终指导你实现一个完整的洋葱模型框架。
4.1 compose函数的原理剖析
compose 是一种函数组合技术,它将多个函数按从右到左的顺序依次执行,前一个函数的输出作为下一个函数的输入。这种顺序正好与洋葱模型中中间件的执行路径相匹配。
4.1.1 函数执行顺序的控制
在 JavaScript 中,我们可以通过 Array.reduceRight 来实现 compose 函数的顺序控制。它的执行顺序是:从右到左依次调用函数。这与洋葱模型中中间件的“进入”和“返回”顺序非常契合。
示例代码:
const compose = (...funcs) => (arg) =>
funcs.reduceRight((acc, func) => func(acc), arg);
逐行分析:
-
...funcs:使用扩展运算符接收任意数量的函数作为参数,组成一个函数数组。 -
(arg):最终返回的函数接受一个初始参数arg。 -
funcs.reduceRight((acc, func) => func(acc), arg): -
reduceRight方法从数组的右端开始处理,逐个将函数调用结果传递给下一个函数。 -
acc是累积值,初始为arg,之后为上一个函数的返回值。 -
func(acc):当前函数以acc为参数执行。
示例调用:
const add = (x) => x + 1;
const multiply = (x) => x * 2;
const composed = compose(add, multiply);
console.log(composed(3)); // 输出:7
执行流程解析:
-
multiply(3)→6 -
add(6)→7
因此,最终输出为 7 ,函数执行顺序是 multiply → add 。
4.1.2 利用Array.reduceRight实现组合
reduceRight 是实现 compose 的关键方法,它确保了函数的调用顺序是从右到左。这与洋葱模型中“先进入外层中间件,再逐步深入”的逻辑完全一致。
使用表格对比不同组合方式:
| 函数组合方式 | 函数执行顺序 | 对应中间件路径 |
|---|---|---|
| compose | 从右到左 | 进入洋葱外层 → 逐步深入 |
| pipe | 从左到右 | 从内向外 → 不符合洋葱模型 |
示例:使用 pipe 实现
const pipe = (...funcs) => (arg) =>
funcs.reduce((acc, func) => func(acc), arg);
const piped = pipe(multiply, add);
console.log(piped(3)); // 输出:7,执行顺序 multiply → add
虽然输出相同,但 pipe 的执行顺序与洋葱模型不一致,因此在洋葱模型中应优先使用 compose 。
4.2 洋葱模型中的中间件执行流程
洋葱模型之所以得名,是因为其执行流程类似于“剥洋葱”的过程:请求进入时依次经过每一层中间件(外层 → 内层),再依次返回(内层 → 外层)。这种双向执行机制依赖于 compose 函数的正确实现。
4.2.1 中间件的定义与注册
中间件是一个函数,通常接收 ctx (上下文)和 next (下一个中间件)两个参数。 next 是一个函数,调用它表示将控制权交给下一个中间件。
示例中间件定义:
const logger = (ctx, next) => {
console.log('进入 logger');
next();
console.log('离开 logger');
};
const auth = (ctx, next) => {
console.log('进入 auth');
next();
console.log('离开 auth');
};
注册中间件:
const middleware = [logger, auth];
4.2.2 请求与响应的双向传递机制
在洋葱模型中,中间件的执行分为两个阶段:
- 进入阶段 :依次执行每个中间件的前半部分(调用
next()之前)。 - 返回阶段 :依次执行每个中间件的后半部分(调用
next()之后)。
流程图(使用 mermaid):
graph TD
A[请求开始] --> B[logger 进入]
B --> C[auth 进入]
C --> D[核心处理]
D --> E[auth 返回]
E --> F[logger 返回]
F --> G[响应结束]
实现洋葱模型执行逻辑:
const composeMiddlewares = (middlewares) => {
return (ctx) => {
const dispatch = (i) => {
const fn = middlewares[i];
if (!fn) return Promise.resolve();
return Promise.resolve(fn(ctx, () => dispatch(i + 1)));
};
return dispatch(0);
};
};
逐行解读:
-
dispatch(i):递归调用中间件,传入当前索引i。 -
fn(ctx, () => dispatch(i + 1)):执行当前中间件函数,next就是() => dispatch(i + 1)。 - 使用
Promise.resolve()确保所有中间件都返回 Promise,支持异步处理。
调用示例:
const ctx = {};
const middlewareStack = composeMiddlewares(middleware);
middlewareStack(ctx).then(() => {
console.log('执行完成');
});
输出结果:
进入 logger
进入 auth
离开 auth
离开 logger
执行完成
4.3 compose函数的调试与优化
尽管 compose 函数功能强大,但在实际使用中仍可能遇到调试困难、性能瓶颈等问题。本节将介绍如何对 compose 函数进行调试和优化。
4.3.1 调试函数执行顺序
在调试中间件执行顺序时,可以使用 console.log 或断点调试来观察执行路径。
示例:带调试信息的 compose 函数
const composeWithDebug = (...funcs) => (arg) => {
console.log('初始参数:', arg);
return funcs.reduceRight((acc, func, index) => {
const result = func(acc);
console.log(`第 ${funcs.length - index} 层函数执行结果:`, result);
return result;
}, arg);
};
调用示例:
const add = (x) => x + 1;
const multiply = (x) => x * 2;
const composed = composeWithDebug(add, multiply);
composed(3);
输出:
初始参数: 3
第 1 层函数执行结果: 6
第 2 层函数执行结果: 7
4.3.2 提高执行效率的优化策略
- 避免重复计算 :将中间结果缓存,避免重复执行相同函数。
- 使用 memoization :对于纯函数,可使用记忆化技术提升性能。
- 异步支持优化 :统一返回 Promise,避免回调地狱。
- 函数扁平化 :减少嵌套调用层级,提升堆栈性能。
示例:异步优化版 compose
const asyncCompose = (...funcs) => async (arg) => {
return await funcs.reduceRight(async (acc, func) => {
const result = await func(await acc);
return result;
}, arg);
};
逐行解释:
- 使用
async/await支持异步函数。 -
await acc:确保前一个函数执行完成后再执行当前函数。 -
await func(...):支持异步中间件。
4.4 实现一个完整的洋葱模型框架
在掌握了 compose 函数和中间件执行流程之后,我们可以构建一个完整的洋葱模型框架。
4.4.1 构建洋葱模型的核心逻辑
我们将创建一个 Koa 风格的洋葱模型框架,支持中间件注册与执行。
核心类定义:
class Onion {
constructor() {
this.middlewares = [];
}
use(fn) {
this.middlewares.push(fn);
}
createContext(req, res) {
return { req, res, state: {} };
}
compose(middlewares) {
return (ctx) => {
const dispatch = (i) => {
const fn = middlewares[i];
if (!fn) return Promise.resolve();
return Promise.resolve(fn(ctx, () => dispatch(i + 1)));
};
return dispatch(0);
};
}
listen(port) {
const server = (req, res) => {
const ctx = this.createContext(req, res);
const handler = this.compose(this.middlewares);
handler(ctx).then(() => {
res.end('处理完成');
}).catch((err) => {
console.error('处理出错:', err);
res.end('出错了');
});
};
require('http').createServer(server).listen(port);
}
}
4.4.2 将中间件注入框架中
使用示例:
const app = new Onion();
app.use(async (ctx, next) => {
console.log('中间件1 进入');
await next();
console.log('中间件1 返回');
});
app.use(async (ctx, next) => {
console.log('中间件2 进入');
await next();
console.log('中间件2 返回');
});
app.listen(3000);
输出结果:
中间件1 进入
中间件2 进入
中间件2 返回
中间件1 返回
通过本章的学习,我们已经掌握了 compose 函数的实现原理、中间件的执行机制、调试与优化技巧,并最终构建了一个完整的洋葱模型框架。这些内容为后续章节中业务逻辑分层设计与状态管理打下了坚实的基础。
5. 业务逻辑分层设计
在现代软件架构设计中,业务逻辑的分层设计是确保系统可维护性、可扩展性和可测试性的关键。洋葱模型(Onion Architecture)通过分层抽象的方式,将不同职责的模块进行隔离,形成一种由外到内、逐层依赖的结构。本章将深入探讨如何在洋葱模型中实现业务逻辑的分层设计,包括分层设计的基本原则、各层的职责划分、典型实践案例以及层与层之间的解耦策略。
5.1 分层设计的基本原则
分层设计的核心在于“ 关注点分离 ”和“ 模块化 ”,即通过将不同的功能模块按照职责划分到不同的层级,实现系统的解耦和模块化管理。
5.1.1 关注点分离与模块化
关注点分离是指将一个复杂系统中的不同职责划分为独立的模块或层,每个模块只处理与其职责相关的任务。例如:
- 路由层 :负责接收 HTTP 请求并转发给业务层;
- 业务逻辑层 :处理核心业务规则;
- 数据访问层 :负责与数据库交互,执行 CRUD 操作;
- 基础设施层 :提供底层服务支持,如日志、缓存、消息队列等。
模块化则强调每个模块应具备高内聚、低耦合的特性。通过接口抽象和依赖注入机制,可以实现模块之间的松耦合。
5.1.2 各层之间的通信方式
在洋葱模型中,层与层之间的通信通常是 单向依赖 的,即外层依赖于内层,而内层不应直接依赖外层。例如:
- 外层(如控制器)调用中间层(业务逻辑)的方法;
- 中间层调用内层(数据访问)的方法;
- 内层不应直接引用外层的类或方法。
实现这种通信方式的关键在于使用 接口抽象 和 依赖注入(DI) 。例如,我们可以定义一个 IUserRepository 接口供业务层调用,而具体的实现(如 UserRepository )由基础设施层提供。
5.2 洋葱模型中的层结构设计
洋葱模型的核心结构由多个层级组成,每一层都围绕着核心业务逻辑展开,像洋葱一样层层包裹。典型的洋葱模型包括:
- 外层 :路由与请求处理;
- 中间层 :业务逻辑处理;
- 内层 :数据访问与持久化;
- 核心层 :领域模型和核心业务规则。
5.2.1 外层(路由与请求处理)
外层是系统与外界交互的入口,通常负责接收 HTTP 请求、解析参数、调用业务层,并返回响应。该层应尽量保持轻量,避免包含复杂业务逻辑。
示例代码:Express 路由处理
const express = require('express');
const router = express.Router();
const { login } = require('../services/authService');
router.post('/login', async (req, res) => {
const { username, password } = req.body;
try {
const token = await login(username, password);
res.json({ token });
} catch (err) {
res.status(400).json({ error: err.message });
}
});
module.exports = router;
逻辑分析:
- 该代码使用 Express 定义了一个 /login 接口;
- 接收请求参数后调用 login 服务方法;
- 成功返回 token,失败返回错误信息;
- 路由层不处理业务逻辑,仅负责请求转发。
5.2.2 中间层(业务逻辑处理)
中间层是整个系统的核心,包含了业务规则、流程控制和数据处理逻辑。这一层通常会定义服务类和服务接口,用于处理具体的业务需求。
示例代码:用户登录业务逻辑
const userRepository = require('../repositories/userRepository');
async function login(username, password) {
const user = await userRepository.findByUsername(username);
if (!user || user.password !== password) {
throw new Error('Invalid credentials');
}
return generateToken(user);
}
function generateToken(user) {
// 生成 JWT Token
return 'mocked_jwt_token';
}
module.exports = { login };
逻辑分析:
- login 函数负责验证用户身份;
- 调用 userRepository 获取用户数据;
- 验证通过后调用 generateToken 方法生成 token;
- 所有业务逻辑集中于该层,便于测试与维护。
5.2.3 内层(数据访问与持久化)
内层负责与数据库或其他持久化机制交互,通常包括数据的增删改查操作。这一层应保持对业务逻辑的透明,仅提供数据访问能力。
示例代码:用户数据访问层
const db = require('../db');
function findByUsername(username) {
return db.users.find(user => user.username === username);
}
module.exports = { findByUsername };
逻辑分析:
- 使用 db.users 模拟数据库;
- 提供 findByUsername 方法供上层调用;
- 数据访问逻辑集中于该层,与业务逻辑分离。
5.3 分层设计的实践案例
为了更好地理解洋葱模型的分层设计,我们以用户登录流程为例,展示各层之间的协作方式。
5.3.1 用户登录流程中的分层处理
用户登录流程涉及多个层级的协作,如下图所示:
graph TD
A[HTTP Request] --> B[路由层]
B --> C[业务逻辑层]
C --> D[数据访问层]
D --> E[数据库]
E --> D
D --> C
C --> B
B --> A
流程说明:
1. 用户发送登录请求(HTTP POST);
2. 路由层接收请求并调用业务逻辑层;
3. 业务逻辑层调用数据访问层查询用户信息;
4. 数据访问层访问数据库并返回结果;
5. 业务逻辑层验证信息后生成 token;
6. 路由层返回 token 给客户端。
5.3.2 日志记录与权限验证的实现
日志记录和权限验证通常作为中间件或拦截器嵌入洋葱模型的外层或中间层。
示例代码:权限验证中间件
function authMiddleware(req, res, next) {
const token = req.headers['authorization'];
if (!token) {
return res.status(401).json({ error: 'Unauthorized' });
}
// 解析 token,验证权限
const user = verifyToken(token);
req.user = user;
next();
}
function verifyToken(token) {
// 模拟 token 解析
return { id: 1, username: 'admin' };
}
module.exports = authMiddleware;
逻辑分析:
- 中间件拦截请求,验证 token 是否存在;
- 如果验证通过,将用户信息挂载到 req.user ;
- 后续路由可以访问该用户信息进行权限判断;
- 权限验证作为独立模块,与业务逻辑解耦。
5.4 层与层之间的解耦策略
良好的解耦策略是构建高可维护性系统的关键。在洋葱模型中,常见的解耦手段包括接口抽象、依赖注入以及中间件机制。
5.4.1 接口抽象与依赖注入
通过定义接口抽象,我们可以实现模块之间的松耦合。例如:
// 接口定义
class IUserRepository {
findByUsername(username) {
throw new Error('Method not implemented');
}
}
// 实现类
class UserRepository extends IUserRepository {
findByUsername(username) {
return db.users.find(user => user.username === username);
}
}
module.exports = { UserRepository };
逻辑分析:
- IUserRepository 是接口,定义了数据访问方法;
- UserRepository 是具体实现类;
- 业务逻辑层通过接口调用方法,而不依赖具体实现;
- 可通过依赖注入容器注入具体实现。
依赖注入示例:
class AuthService {
constructor(userRepository) {
this.userRepository = userRepository;
}
async login(username, password) {
const user = await this.userRepository.findByUsername(username);
if (!user || user.password !== password) {
throw new Error('Invalid credentials');
}
return generateToken(user);
}
}
逻辑分析:
- AuthService 通过构造函数注入 userRepository ;
- 业务逻辑层不关心具体的数据访问实现;
- 提高代码可测试性和可维护性。
5.4.2 使用中间件进行层间通信
中间件机制是洋葱模型中常用的通信方式,尤其是在处理 HTTP 请求时。通过中间件链,我们可以实现日志记录、权限校验、异常处理等功能。
中间件执行流程示意图:
graph LR
A[请求进入] --> B[日志中间件]
B --> C[权限验证中间件]
C --> D[业务处理中间件]
D --> E[响应返回]
逻辑说明:
- 请求依次经过多个中间件;
- 每个中间件完成特定功能后调用 next() ;
- 响应从内层向外层逐层返回;
- 中间件之间通过 req 和 res 对象通信。
小结
本章深入探讨了洋葱模型中业务逻辑的分层设计原则与实现方式。通过合理的分层设计,我们可以实现系统的模块化、低耦合和高内聚。外层负责请求处理,中间层处理业务逻辑,内层负责数据访问,各层之间通过接口抽象和依赖注入进行通信。结合实际案例(如用户登录流程)和中间件机制,我们展示了如何在实际项目中应用这些设计原则。
下一章将围绕状态传递与更新机制展开,进一步探讨洋葱模型如何在复杂业务场景中处理状态的流动与更新。
6. 状态传递与更新机制
6.1 状态管理的基本概念
在现代前端架构中, 状态管理 是构建可维护、可扩展应用的核心机制之一。在洋葱模型中,状态的管理和传递贯穿整个中间件链条,决定了请求的处理流程和响应结果。
6.1.1 全局状态与局部状态的区别
| 类型 | 描述 |
|---|---|
| 全局状态 | 应用生命周期内共享的状态,例如用户登录信息、主题设置等 |
| 局部状态 | 仅在当前请求或模块中有效的状态,如请求参数、临时计算结果等 |
在洋葱模型中, 全局状态 通常由顶层上下文(如Koa的 ctx 对象)统一管理,而 局部状态 则通过中间件逐层传递与修改。
6.1.2 状态的生命周期管理
状态的生命周期从请求开始时创建,贯穿所有中间件,并在响应结束后释放或更新。洋葱模型通过中间件链的 双向传递机制 实现状态的上下文传递:
graph TD
A[请求进入] --> B[中间件1入栈]
B --> C[中间件2入栈]
C --> D[核心处理]
D --> E[中间件2出栈]
E --> F[中间件1出栈]
F --> G[响应返回]
在这个流程中,状态可以在每个中间件中被修改或扩展,从而实现跨层通信和数据共享。
6.2 洋葱模型中的状态流动机制
6.2.1 请求上下文中的状态传递
在基于洋葱模型的框架(如Koa)中, 请求上下文(Context) 是状态传递的核心载体。它通常包含以下内容:
const ctx = {
request: { /* 请求信息 */ },
response: { /* 响应信息 */ },
state: {}, // 可扩展的状态对象
app: { /* 应用实例 */ }
};
中间件可以通过修改 ctx.state 来共享数据:
async function middleware1(ctx, next) {
ctx.state.user = await fetchUser(); // 从数据库获取用户信息
await next(); // 传递给下一层中间件
}
async function middleware2(ctx, next) {
console.log(ctx.state.user); // 使用上一层中间件传入的用户信息
await next();
}
参数说明 :
-ctx:请求上下文对象,用于传递状态和数据。
-next():调用下一个中间件函数,形成洋葱模型的执行链条。
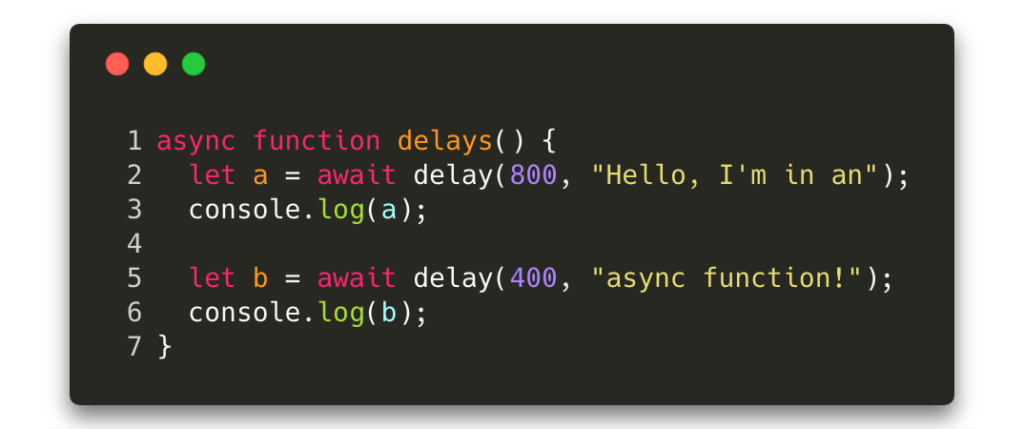
6.2.2 异步操作中的状态保持
异步操作(如数据库查询、API调用)中,状态必须通过 Promise 链或 async/await 机制保持:
async function authMiddleware(ctx, next) {
try {
const token = ctx.headers.authorization;
const user = await verifyToken(token); // 异步验证token
ctx.state.user = user; // 将用户信息存入状态
await next(); // 等待后续中间件执行
} catch (err) {
ctx.status = 401;
ctx.body = { error: 'Unauthorized' };
}
}
通过 await next() ,我们确保在异步操作完成后状态仍保持一致。
6.3 状态更新与响应机制
6.3.1 同步状态更新方式
同步更新状态通常用于请求处理的中间阶段,例如设置用户角色、权限状态等:
function setRoleMiddleware(ctx, next) {
if (ctx.state.user.isAdmin) {
ctx.state.role = 'admin';
} else {
ctx.state.role = 'guest';
}
next(); // 同步无需await
}
⚠️ 注意:同步中间件中不要使用
await next(),否则可能导致流程阻塞或执行顺序混乱。
6.3.2 异步回调与Promise链式调用
当状态更新依赖外部数据源时,应使用异步方式:
async function fetchProfileMiddleware(ctx, next) {
const profile = await fetchProfileFromAPI(ctx.state.user.id);
ctx.state.profile = profile;
await next();
}
function logProfileMiddleware(ctx, next) {
console.log('User profile:', ctx.state.profile);
next();
}
洋葱模型通过 Promise 链确保状态更新在后续中间件中可用。
6.4 状态管理的最佳实践
6.4.1 使用中间件统一状态处理
建议将状态管理逻辑封装在专用中间件中,便于复用和维护:
function createStateManagementMiddleware() {
return async function(ctx, next) {
ctx.state.startTime = Date.now();
await next();
const duration = Date.now() - ctx.state.startTime;
console.log(`Request processed in ${duration}ms`);
};
}
这样可以统一处理日志、性能监控、权限验证等跨切面逻辑。
6.4.2 状态变更的监听与响应
可以通过发布-订阅机制监听状态变更,实现响应式处理:
const EventEmitter = require('events');
class StateEmitter extends EventEmitter {}
const stateBus = new StateEmitter();
stateBus.on('user:login', (user) => {
console.log('User logged in:', user);
});
async function loginMiddleware(ctx, next) {
const user = await authenticate(ctx.request.body);
ctx.state.user = user;
stateBus.emit('user:login', user); // 发布状态变更事件
await next();
}
这种方式可以实现跨中间件通信和状态响应机制。
(本章节未完,后续内容将通过中间件与状态管理的结合进一步展开)
简介:JavaScript洋葱模型是一种通过高阶函数组织业务逻辑的设计模式,结构类似洋葱,层与层之间通过组合函数依次调用,提升代码的模块化、可维护性和可测试性。文章详解了如何使用函数组合实现洋葱结构,包括模块划分、状态管理、错误处理等内容,并结合示例代码讲解了从外到内再向外的执行流程,适合中高级前端开发者深入理解函数式编程在架构设计中的应用。

















 1561
1561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









