






网易云音乐如今占据着音乐app的半壁江山,有着大量用户。
想给你的好友或心仪的Ta来一张下图效果的小惊喜吗?
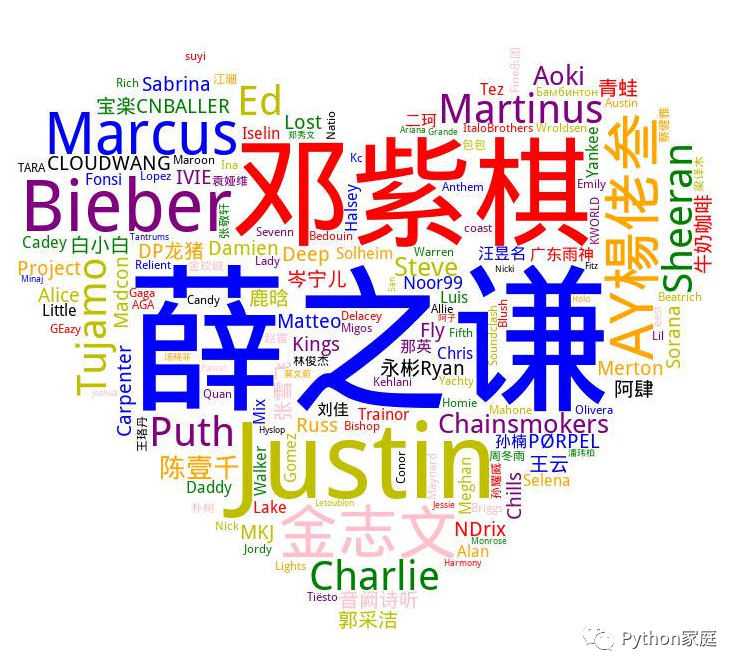
图中都是Ta喜爱的歌手哦,哪位歌手被听过的歌更多,显示的字号就越大~
今天就教大家如何利用python轻松做出一张网易云用户喜爱歌手的词云图。
文末会附上完整源码
实现思路
通过爬虫获取目标用户在所有时间的听歌排行信息
先浏览器打开网易云音乐网页版手动查看用户主页和听歌排行的url,观察之后确定通过selenium库处理该异步加载动态网页。
提取排行里所有音乐的歌手信息并生成本文
网页加载完毕后(等于变成了静态网页),通过bs4库的BeautifulSoup方法解析,并提取歌手信息。再从收录了全部歌手信息的列表中提取字符串
根据歌手文本信息做成词云图
将包含所有歌手名字的文本通过wordcloud库便捷的自动生成词云图,再由matplotlib库作图并展示出来。当然其中可以设置更多的参数来美化图片效果~
实现过程
1. 观察用户主页和听歌排行url
随便选择一位用户(出于保护隐私,以下会部分打码,但不影响代码以及学习技巧),观察其主页上红框标示之处:
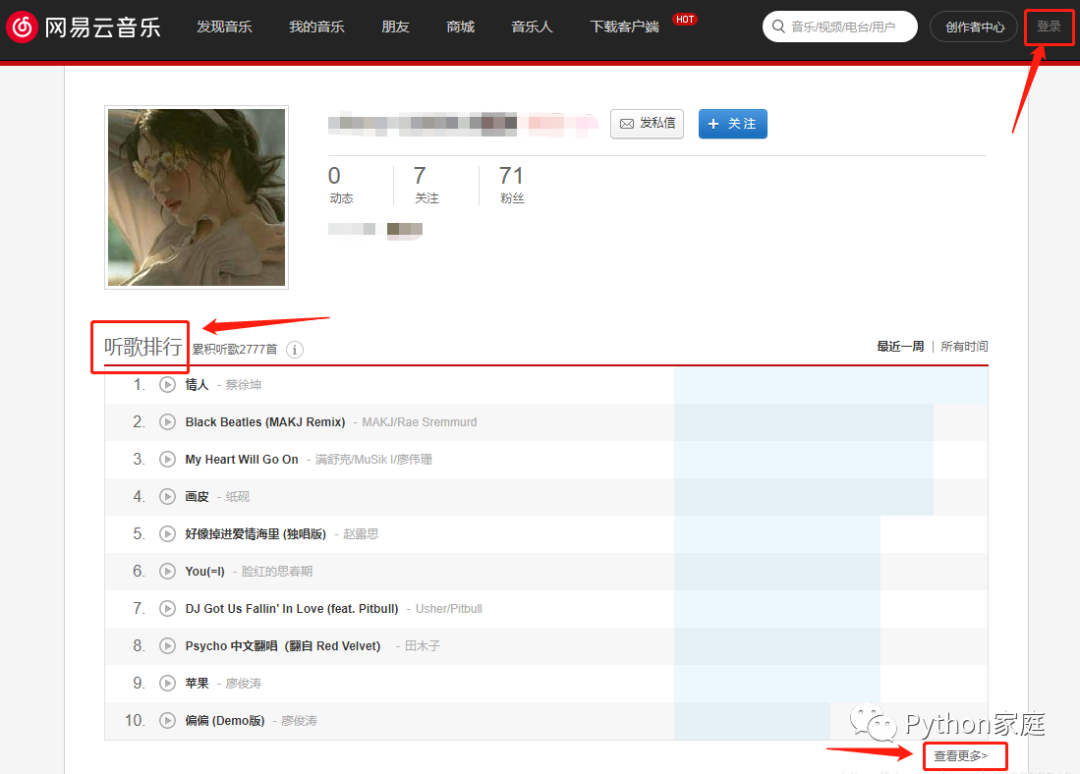
得知:在用户主页如果能看到听歌排行,那就说明Ta设置为可见。那我们接着就可以点右下角查看更多,前往完整听歌排行的页面。注意右上角,这些操作都是不需要我们登录自己账号的,这样在爬取时很方便。
点击进入查完完整听歌排行页面:
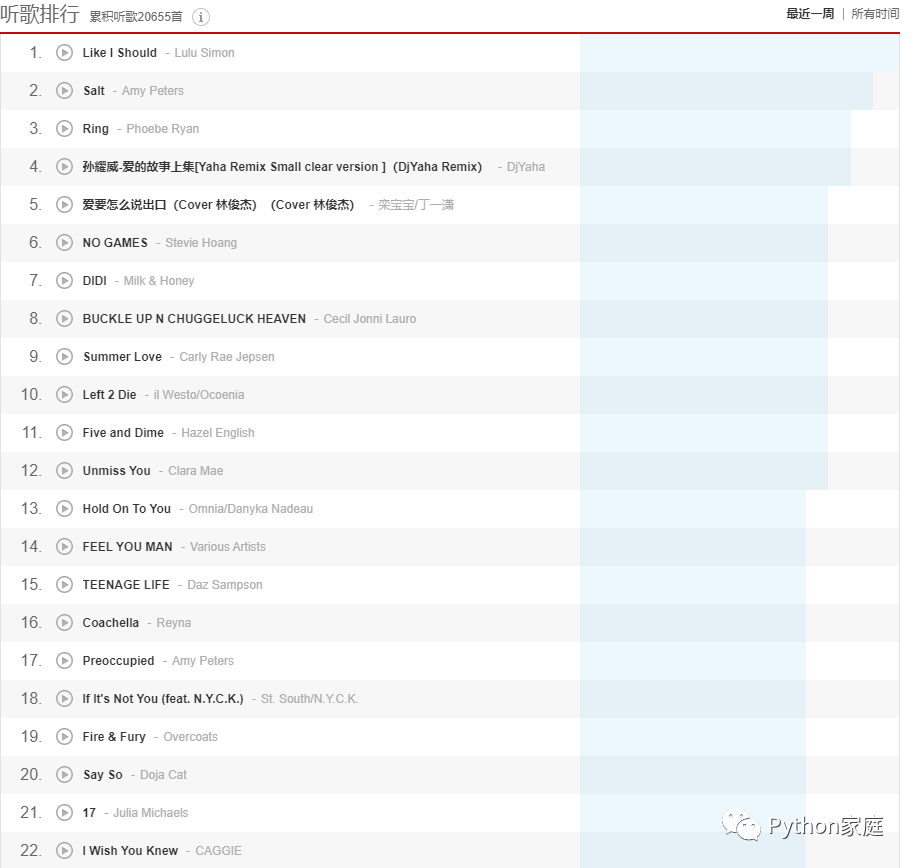
观察确认:等下爬取该动态页面时需要模拟点击右上角,位于最近一周右侧的所有时间,来加载出所有时间下听歌排行的全部歌手。
最后打开F12的(笔者是chrome浏览器)开发者工具,观察等下需要用来定位的标签:
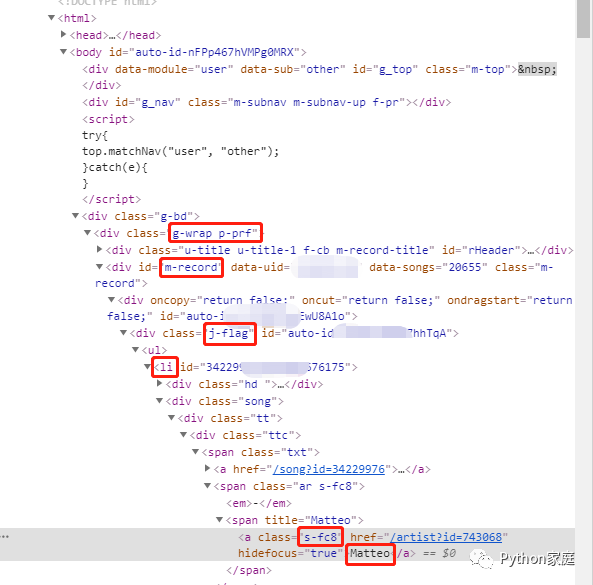
观察完毕,万事具备,开始写爬虫获取歌手信息。
2. 爬虫代码
以我用的chrome浏览器为例写代码。先来导入模块,我们要用到selenium、bs4和time模块:
import timefrom selenium import webdriverfrom bs4 import BeautifulSoup构建url以及设置等下要用到的变量名:
uid = '41209xxxx'#随时可替换用户idurl_recd = 'https://music.163.com/#/user/?id='+uid#构建爬取urlunknown = '未知'#特殊情况下错误提示用asingerlist = []#储存所有时间排行中所有歌手的列表start = time.time()#设置计时器samaritan =webdriver.Chrome()#webdriver实例化这里要注意网页有iframe页面嵌套,如果不能进入iframe里面,是不能定位到任何在它里面的标签的。
幸运的是这对selenium来说仍然不是问题:
def get_record():#创建获取歌手信息的方法 samaritan.get(url_recd) #实例化对象访问url samaritan.switch_to.frame('g_iframe') #找到指定iframe标签(这里是g_iframe)然后跳入 samaritan.implicitly_wait(10)#隐式等待 checkall = samaritan.find_element_by_id('songsall') #定位到切换到所有时间的按钮标签 checkall.click() #模拟鼠标点击查看所有时间下的听歌排行 samaritan.implicitly_wait(10)#隐式等待 time.sleep(0.5)#这里还需要强制等待加载时间,一般一秒内就可以了 htmlrec = samaritan.page_source #此时网页成为静态页面,获取所有页面信息 pagerec = BeautifulSoup(htmlrec, 'html.parser')#使用bs4解析静态网页 allrec = pagerec.find(class_="g-wrap p-prf").find(class_="m-record").find(class_="j-flag").find_all('li') #定位该位置下所有的标签 try:#使用try except结构防止意外报错中断运行 for i in allrec: #遍历刚才位置下每一个标签内信息 asinger = i.find(class_="s-fc8").text.replace('-', '') #定位并获取歌手文本信息,再用replace方法清洗文本去掉歌名和各种之间连结的'-' asingerlist.append(asinger) #将干净的歌手文本加入列表 except: print(unknown) #如遇到意外,提示'未知'。最后调用方法以及查看结果:
get_record()#调用爬取方法samaritan.close()#关闭浏览器end = time.time()#结束计时print(asingerlist)#打印所有歌手列表print(f'总共用时:{end-start}秒')#打印程序用时输出结果:[' Matteo', ' Russ', ' 永彬Ryan.B/AY楊佬叁', ' DP龙猪/宝楽CNBALLER/CLOUDWANG\xa0王云', ' 音阙诗听', ' Deep\xa0Chills/IVIE', ' 白小白', ' Fly\xa0Project', ' 金志文'...... #以下省略] 总共用时:4.079788398742676秒只要四秒钟,我们就完成了对目标用户所有时间听歌排行的歌手爬取。
但是这样一点看不清啊,而且怎么知道哪些歌手更被偏爱呢?
接下去我们就要把这个歌手列表里的内容制作成一目了然的词云图了~
3. 制作词云图
本次制作词云我们还将用到以下库:
os、PIL、numpy、matplotlib、wordcloud
这些库的安装使用也不在本篇讲解了,只是展示给大家这种实战情况下如何调用,有兴趣的一样可以自行搜索深入学习。
开始制作词云,依旧先导入模块:
from os import pathfrom PIL import Imageimport numpy as npimport matplotlib.pyplot as pltfrom matplotlib import colorsfrom wordcloud import WordCloud我们用wordcloud的方法处理文本,以生成词云。一行代码先将刚才的歌手列表变成wordcloud可以处理的字符串,再两行代码给词云戴上爱心“面具”:
astext = ','.join(asingerlist)#将列表所有元素依序合并成字符串,并用'逗号'连接d = path.dirname(__file__)#获取当前文件路径alice_mask = np.array(Image.open(path.join(d,"love.png")))#读取模板的图片模板图片:love.png

现在我们来美化一下这个词云,使它的颜色再丰富一些:
color_list=['r','g','b','y','pink','purple','orange','black']#建立颜色数组,列表中的颜色可以随便改动,除了常用颜色英文名外,也可以直接使用RGB色值,例如'#FDF5E6'colormap=colors.ListedColormap(color_list) #调用颜色数组万事俱备啦,设置wordcloud对象参数:
wc = WordCloud(#创建wordcloud实例 font_path='wqy-microhei.ttc', #设置字体路径,如果要制作的词云中有中文我们需要下载字体文件调用 background_color="white", #设置图片背景色,默认为黑色,这里我觉得用白色比较好看 max_words=1000, #设置显示最大单词数 colormap=colormap, #设置字体颜色 mask=alice_mask, #设置模板图片,戴上'面具')wc.generate(astext)#根据所有歌手信息的文本生成词云词云到这里就做好啦,不过别急,现在运行是什么都看不见的哦!我们需要通过matplotlib模块来作图并展示:
plt.imshow(wc, interpolation='bilinear')#生成词云图片plt.axis("off")# 关闭图像坐标系plt.figure('singer')#指定所绘图名称plt.show()#显示图片运行一下(变量里目标用户的uid需要自己填入)
结果是不是一目了然?
结尾
到此为止你已经get到所有源码,也掌握了对任意网易云用户迅速了解其喜爱歌手的方法以及制作帅气的词云图。
对词云感兴趣的话可以自行深入学习或期待以后更新的文章哦,其实还有不少使用的技巧如安装jieba模块,用来中文分词后制作词云,本篇没用到是因为中文都是歌手名字,不需要分词。如果你的文本是句子等,就会需要先用jieba模块。又比如wordcloud参数,你可以有更多设置选择以及保存图片:
max_font_size=50,min_font_size=10,#设置最大、最小字体collocations=False,#设置是否过滤重复关键字stopwords=stopwords#设置忽略显示的词,比如无意义的噪声词(因为、所以、这些、哪些、said、the等)wc.to_file(path.join(d,"wordcloud.jpg"))#保存刚制作的词云图到指定路径最后,如果你还没动手开始的话,赶紧去找个你的网易云音乐好友,制作一张词云图秀Ta一脸吧!
我们下期再见~
附完整源码:
import timefrom bs4 import BeautifulSoupfrom selenium import webdriverfrom os import pathimport matplotlib.pyplot as pltimport numpy as npfrom matplotlib import colorsfrom PIL import Imagefrom wordcloud import WordCloud, STOPWORDSuid = '填入用户id'url_recd = 'https://music.163.com/#/user/songs/rank?id='+uidunknown = '未知'asingerlist = []start = time.time()samaritan =webdriver.Chrome()def get_record(): samaritan.get(url_recd) samaritan.refresh() samaritan.switch_to.frame('g_iframe') samaritan.implicitly_wait(10) time.sleep(0.5) checkall = samaritan.find_element_by_id('songsall') checkall.click() samaritan.implicitly_wait(10) time.sleep(0.5) htmlrec = samaritan.page_source pagerec = BeautifulSoup(htmlrec, 'html.parser') allrec = pagerec.find(class_="g-wrap p-prf").find(class_="m-record").find(class_="j-flag").find_all('li') try: for i in allrec: asinger = i.find(class_="s-fc8").text.replace('-', '') asingerlist.append(asinger) except: print(unknown)get_record()samaritan.close()print(asingerlist)astext = ','.join(asingerlist)d = path.dirname(__file__)alice_mask = np.array(Image.open(path.join(d,r"love.png")))color_list=['r','g','b','y','pink','purple','orange','black']colormap=colors.ListedColormap(color_list)wc = WordCloud( font_path=r'wqy-microhei.ttc', collocations=False, background_color="white", max_words=1500, colormap=colormap, mask=alice_mask,)wc.generate(astext)wc.to_file(path.join(d,r"wordcloud.jpg"))plt.imshow(wc, interpolation='bilinear')plt.axis("off")plt.figure()plt.show()end = time.time()print(f'总共用时:{end-start}秒')1、Python微信飞机大战
2、Python用10行代码【批量抠图】
3、10行爬虫代码搞定数据 - 新冠肺炎疫情
(完)
看完本文有收获?
关注我们,一起学Python吧




Python家庭
点个 “在看” 转发 “朋友圈” 和大家一起分享吧 















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









