







以自己能快速理解的方式重新梳理了innodb引擎的物理文件结构,从静态和动态的两种视角去
理解文件结构,增强对innodb引擎的运行的了解。静态视角,首先从文件读取的角度考虑整个文件的组织形式和存储结构,以便于能够顺利的解析innodb的ibd文件
动态视角,数据库文件是为数据库管理系统和数据库实例运行而服务的,在了解B+树原理的基础上,深刻理解数据在数据库中增加以后,是如何在数据库中存储,以及数据是如何落地的,既要保证数据存储的灵活性,又要保证数据库查询的性能。
1. 了解mysql的架构视图
了解mysql的架构视图如下图,有助于了解innodb引擎的几种物理文件组成,一共四种:一种是系统共享的表空间ibdata1;一种是各个数据库的表空间,一个数据库一个t.ibd文件;第三种是undo表空间,在mysql中通常被叫做rollback segment,第四种是redo日志文件
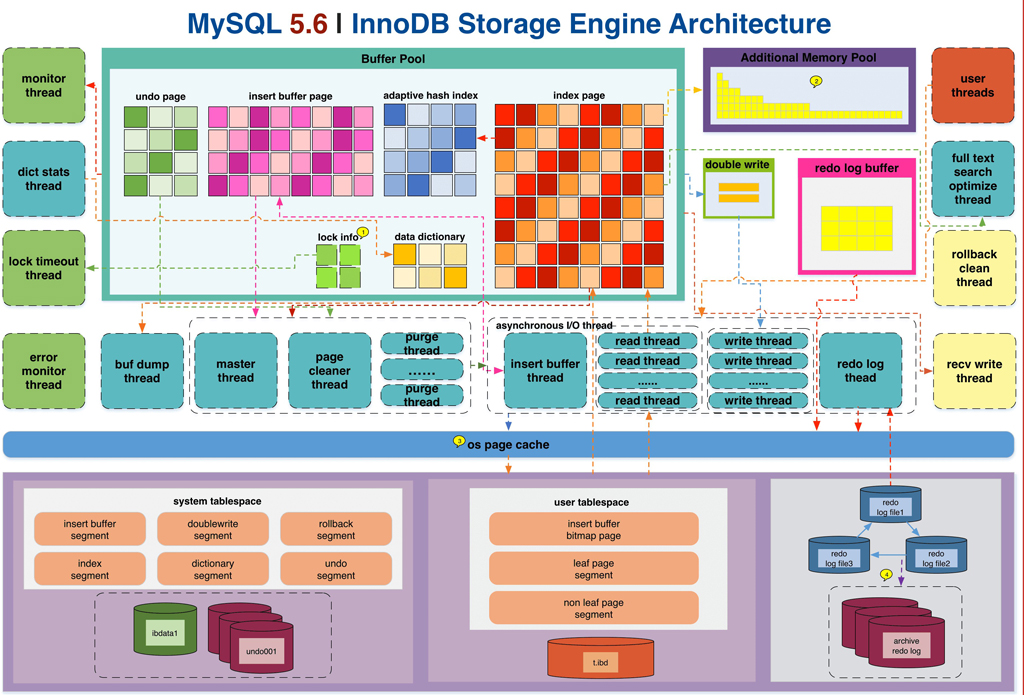
2. innodb的一页(pages)2.1 innodb的基本管理单位是页,这个让我联想到的操作系统的段页式管理,在操作系统中物理内存也被分成一页一页的,而一个进程的虚拟页可以分配到任意一页未使用的物理页上,这样就能充分使用物理内存;到数据库系统中,基本的管理单位也是页,也就是磁盘文件也分成一页一页的,每页的大小默认是16K,这个值的大小可以通过innodb_page_size参数来更改,innodb的页有不同的作用,枚举定义在fil0fil.h中(FIL_PAGE_TYPE);
2.2 数据库中表的行记录就保存在其中的某一页中,因此当数据发生变化时,数据落地的一定是某一些pages,查询时就是将某些匹配的记录页加载到内存中;其次页号也是用来组织数据结构的依据,相比内存中的指针来说,磁盘文件内部数据的组织通过页号和页内偏移,可以作为文件的偏移量而找到文件中的数据,加载到内存中.(类似链表中的指针)
2.3 这里引申了一个问题,一个表空间的最大容量是多少?(The astute may remember that InnoDB has a limit of 64TiB of data; this is actually a limit per space, and is due primarily to the page number being a 32-bit integer combined with the default page size: $ 2^32 x 16 KiB = 64 $ TiB.)
因为页号的最大值是32位的,一页的大小为16K,所以一个表空间的最大容量限制在64T
3. innodb的ibd文件静态视图
什么是静态视图,我想你可以这样理解,就是数据库关掉以后数据库的ibd文件的物理结构,从解析ibd文件的视角来看文件结构,以便区分在数据库运行过程中文件里数据的内在逻辑结构。
表空间文件结构图如下图,在ibd文件中第一页(第一个16K)里始终是FSP_HDR页,大概的英文意思是file space header;然后是每256M会建立一个XDES页,其中innodb的系统表空间和为每张表建立的表空间为这张表空间结构的实际例子

innodb引擎有一个默认的系统表空间

当配置文件中配置1innodb_file_per_table=ON
将为每张表建立一个表空间,这个名字叫file per table,实际上叫每张表一个表空间更加合理,图中显示的FSP_HDR页,INODE页以及INDEX页的结构在接下来将有讲述。

3.1 FSP_HDR页
这里强调一下在ibd文件中第一页(第一个16K)里始终是FSP_HDR页,他的作用是管理接下来的0~255一共256个区的信息,其中在这个页中包含一个FSP header结构和XDES集合,将在概览图后讲述
 FSP header,这个主要是用来管理接下来的区中包含的页,更好分配区和区里面的页提供的数据信息
FSP header,这个主要是用来管理接下来的区中包含的页,更好分配区和区里面的页提供的数据信息

XEDS Entry包含一个区内的64页的操作相关的信息

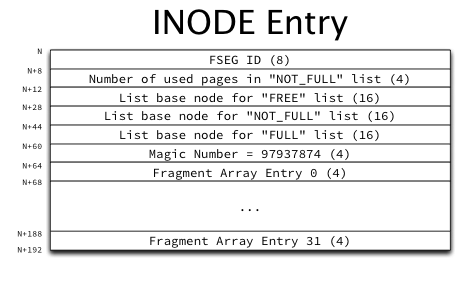
3.2 INODE页inode页一直让人疑惑,刚开始我以为是文件系统里那个inode节点信息重用磁盘节点信息,后来提出疑问用页可以管理了整个数据结构,为什么还需要inode呢?直到看到索引文件段管理结构图,才理解inode页实际是为了在同一个表内的数据页之上在建立不同的索引结构,而组织的逻辑数据,不同于页的是,页承载的是各种数据集,而inode页承载的是不同的索引结构,INODE页的结构比较简单,包含了INODE Entry的集合

INODE Entry主要是组织不同目的页的链表信息
3.3 INDEX页
索引页实际上就是数据页,叫法不一样,如果是叶子节点,那么这个页里面保存里我们同说所说的行记录数据,虽然我们不管不顾的只看文件的格式,但是一直要注意我们所提到的这个结构的作用,为什么这样设计很重要,以及他们的局限性

每个索引页都有一个INDEX Header;一个FSEG Header;两个System Records,若干个User Record,以及Page DirectoryIndex Header

System Recoders

Page Directory

User records
4. 行记录格式
这里重点讲述一下行记录格式,大概他的性能关系到表的大小,这里以Compact行记录格式为例;在每个行记录里都会有record header,如下图
 变长字段长度列表:记录非NULL变长字段的长度列表,按列的逆序排列,使用1字节还是2字节,字节的前缀有(1exxxxxxx xxxxxxxx)
变长字段长度列表:记录非NULL变长字段的长度列表,按列的逆序排列,使用1字节还是2字节,字节的前缀有(1exxxxxxx xxxxxxxx)
NULL 标志位:标示值为NULL的列的bitmap,某列为NULL时相应bit位为1
记录头信息:五个字节一共40位
列数据部分:除了记录每一列对应的数据外,还有隐藏列,它们分别是 Transaction ID、Roll Pointer 以及 row_id。结论:通过以上的概览,可以清晰的看到整个物理文件的组成结构,足以写出解析ibd文件的信息
参考资料















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









