 SpringBoot连接PrestoJDBC实战
SpringBoot连接PrestoJDBC实战





简介:PrestoDEMO(JAVA-JDBC)是一个基于SpringBoot框架的示例应用,演示了如何通过Java JDBC连接并操作Presto分布式SQL查询引擎。项目支持通过URL传递SQL语句,经由JDBC执行查询,并将结果转换为JSON格式返回前端。该DEMO涵盖了SpringBoot快速开发、RESTful接口设计、JDBC数据库连接、Presto查询引擎集成、SQL动态执行与JSON数据封装等关键技术,适用于学习大数据环境下Java后端与分布式数据库的交互实现。经过测试验证,项目具备良好的可运行性与扩展性,是掌握Presto与JDBC集成的优质实践案例。
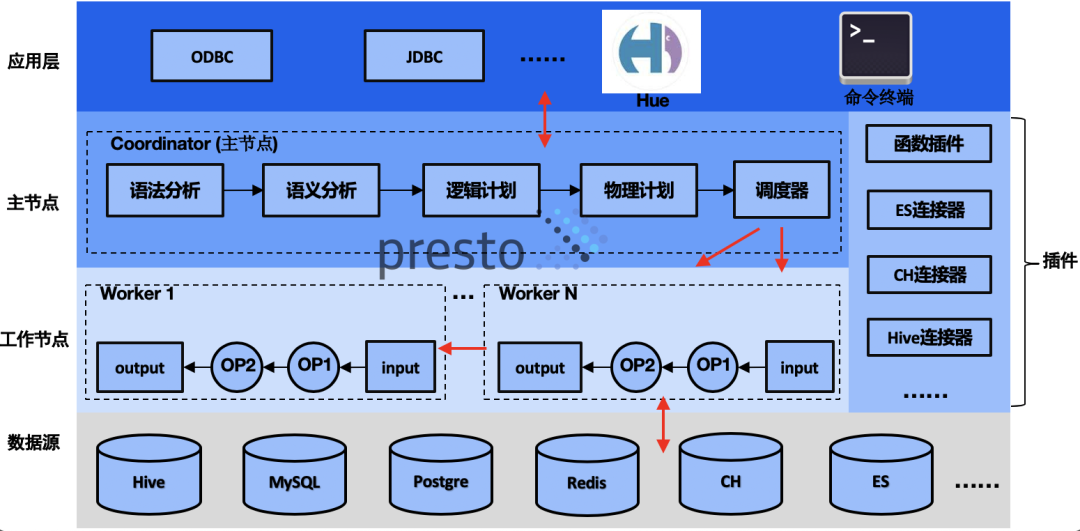
1. SpringBoot项目搭建与RESTful API设计基础
1.1 Spring Boot初始化与项目结构配置
使用Spring Initializr快速构建项目骨架,选择Web、Lombok、Configuration Processor等核心依赖。项目采用标准Maven多模块结构,主启动类配置 @SpringBootApplication 注解,启用自动配置机制。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
1.2 RESTful API设计规范与实现
遵循HTTP语义化原则,设计 /api/v1/query 作为SQL执行统一入口,采用POST方法提交查询体,返回标准化JSON响应结构,支持异步轮询机制应对长查询任务。
2. Java JDBC连接Presto数据库核心机制
在大数据分析系统中,Presto作为一款高性能的分布式SQL查询引擎,广泛应用于跨数据源实时查询场景。其架构支持多Catalog、多Schema的数据联邦查询能力,使得企业可以在不移动数据的前提下完成复杂分析任务。然而,要将 Presto 与 Java 应用程序深度集成,必须通过标准 JDBC 接口实现稳定可靠的连接机制。本章聚焦于 Java 环境下基于 JDBC 驱动连接 Presto 的核心技术路径,深入剖析驱动引入、连接配置、多数据源管理等关键环节,帮助开发者构建高效、可扩展且安全的数据库访问层。
JDBC(Java Database Connectivity)是 Java 提供的标准 API,用于与各种关系型和非关系型数据库进行交互。尽管 Presto 并非传统意义上的 RDBMS,但它提供了完整的 JDBC 驱动支持,允许客户端像操作 MySQL 或 PostgreSQL 一样发起 SQL 查询并获取结果集。这一特性极大地降低了接入门槛,但也带来了诸如版本兼容性、认证方式选择、连接池优化等一系列工程挑战。尤其是在微服务架构或高并发查询场景中,如何合理设计连接策略、避免资源泄漏、提升响应速度成为系统稳定性的重要保障。
此外,随着业务复杂度上升,单一 Presto 集群往往需要对接多个异构数据源(如 Hive、MySQL、Kafka、Iceberg),每个数据源对应不同的 Catalog 和 Schema。这就要求应用程序具备动态切换数据源的能力,并能正确处理跨 Catalog 联合查询的语法规范与执行逻辑。因此,理解 Presto JDBC 的底层工作机制,不仅是技术实现的基础,更是构建企业级数据分析平台的关键支撑。
2.1 Presto JDBC驱动引入与依赖管理
Presto JDBC 驱动是 Java 应用与 Presto 服务器通信的核心组件,负责封装网络协议、序列化请求、解析响应以及提供标准的 java.sql 接口实现。正确的驱动引入方式和依赖管理策略直接影响项目的可维护性和运行时稳定性。特别是在使用 Maven 构建工具的企业级项目中,合理的坐标声明与版本控制机制显得尤为重要。
2.1.1 Maven中引入Presto JDBC驱动坐标
在 Maven 项目中,引入 Presto JDBC 驱动需在 pom.xml 文件中添加对应的依赖项。官方推荐的方式是直接引用由 PrestoSQL(现更名为 Trino)社区发布的 trino-jdbc 包,该包兼容大多数开源 Presto 发行版(如 Starburst、Airlift 等)。以下是一个典型的依赖声明示例:
<dependency>
<groupId>io.trino</groupId>
<artifactId>trino-jdbc</artifactId>
<version>436</version>
</dependency>
说明 :自 Presto 分裂为 Trino 后,原
com.facebook.presto:presto-jdbc已不再更新,建议新项目统一采用io.trino:trino-jdbc坐标。
对于仍在使用旧版 Presto 的环境(如 Facebook 开源版本),可使用如下坐标:
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.280</version>
</dependency>
| 属性 | 说明 |
|---|---|
groupId | 组织标识符,Trino 使用 io.trino ,原始 Presto 使用 com.facebook.presto |
artifactId | 模块名称,固定为 trino-jdbc 或 presto-jdbc |
version | 版本号,应与目标 Presto/Trino 服务端版本尽量保持一致 |
需要注意的是,Presto JDBC 驱动为“fat jar”格式,即包含所有必要依赖(如 Guava、OkHttp 等),因此无需额外引入其他库即可运行。但这也可能导致依赖冲突问题,尤其是在已有大量第三方库的 Spring Boot 项目中。
为避免类路径冲突,推荐采取以下措施:
- 使用 <exclusions> 排除重复依赖;
- 在多模块项目中统一定义 BOM(Bill of Materials)管理版本;
- 启用 Maven 的 dependency:analyze 插件检测未使用或冲突的依赖。
<dependency>
<groupId>io.trino</groupId>
<artifactId>trino-jdbc</artifactId>
<version>436</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
上述配置排除了驱动自带的 Guava 库,转而使用项目中已有的更高版本,从而避免因版本不一致导致的 NoSuchMethodError 等运行时异常。
2.1.2 驱动版本兼容性与类路径加载机制
Presto JDBC 驱动的版本必须与 Presto 服务端保持良好的兼容性。虽然驱动具有一定的向后兼容能力,但在某些情况下仍可能出现协议不匹配、功能缺失或反序列化失败的问题。例如,较老版本的 JDBC 驱动可能无法识别新版 Presto 引入的函数(如 array_sort )、数据类型(如 TIMESTAMP(6) WITH TIME ZONE )或执行计划结构。
| 客户端驱动版本 | 支持的服务端最低版本 | 是否支持 LDAP 认证 | 是否支持 TLS 加密 |
|---|---|---|---|
| trino-jdbc 436 | Trino 350+ | 是 | 是 |
| presto-jdbc 0.280 | Presto 0.240+ | 否 | 有限支持 |
| trino-jdbc 400 | Trino 300+ | 是 | 是 |
✅ 最佳实践建议 :始终让 JDBC 驱动版本 ≥ Presto 服务端版本,以确保获得最新特性和安全补丁。
在 JVM 运行时,JDBC 驱动通过 ServiceLoader 机制自动注册。具体而言, trino-jdbc.jar 内部包含 /META-INF/services/java.sql.Driver 文件,内容为:
io.trino.jdbc.TrinoDriver
当调用 Class.forName("io.trino.jdbc.TrinoDriver") 或使用 DriverManager.getConnection() 时,JVM 会扫描类路径下所有符合此规范的文件,并实例化相应的驱动类。这是 JDBC 规范的一部分,也是为什么现代框架无需显式加载驱动即可建立连接的原因——Spring Boot 自动配置机制正是基于这一点实现的。
然而,在 OSGi 容器或多 ClassLoader 环境中,类路径隔离可能导致驱动无法被正确发现。此时可通过强制注册方式解决:
try {
Class.forName("io.trino.jdbc.TrinoDriver");
} catch (ClassNotFoundException e) {
throw new IllegalStateException("Trino JDBC Driver not found in classpath", e);
}
该代码确保驱动类被主动加载到 JVM 中,绕过 ServiceLoader 查找失败的风险。同时也有助于提前暴露依赖缺失问题,便于在应用启动阶段快速定位故障。
classDiagram
class Driver {
+static void register()
+Connection connect(String url, Properties info)
}
class DriverManager {
+static Connection getConnection(String url, Properties props)
}
class ServiceLoader {
<<interface>>
+Iterator~S~ iterator()
}
Driver --> ServiceLoader : implements java.sql.Driver
DriverManager ..> Driver : uses
ServiceLoader --> Driver : loads via /META-INF/services
流程图说明 :展示了 JDBC 驱动加载的核心流程。
ServiceLoader扫描类路径下的java.sql.Driver实现类,DriverManager在请求连接时调用具体驱动的connect()方法完成连接建立。
综上所述,Maven 坐标引入与版本管理是整个连接链路的第一步,直接影响后续所有操作的可行性。只有在正确加载且兼容的驱动基础上,才能进一步开展连接参数配置、身份验证、连接池集成等工作。
3. 动态SQL执行与安全控制实践
在现代企业级Java应用中,尤其是基于Spring Boot构建的大数据查询平台,前端往往需要灵活提交自定义SQL语句以实现即席查询(Ad-hoc Query)功能。这类需求推动了后端系统对“动态SQL执行”的支持能力,但同时也带来了巨大的安全挑战,特别是SQL注入攻击的风险显著上升。因此,在保障接口灵活性的同时,必须建立一套完整的动态SQL接收、处理、防护和异常响应机制。
本章聚焦于如何在Spring Boot项目中安全地接收并执行用户传入的SQL语句,涵盖从前端参数设计到SQL构造逻辑封装的全流程;深入探讨SQL注入的常见攻击手段及对应的多层级防御策略;并通过统一异常处理机制提升系统的可观测性与调试效率。整个章节围绕 安全性、可维护性和用户体验 三大核心目标展开,旨在为高交互性的数据分析系统提供坚实的技术支撑。
3.1 动态SQL语句接收与处理流程
动态SQL的执行起点通常是一个RESTful API端点,用于接收前端发送的原始SQL文本或结构化查询参数。为了兼顾灵活性与可控性,合理的请求设计模式至关重要。同时,后端需对这些输入进行规范化处理,避免直接拼接字符串造成安全隐患,并通过抽象层封装SQL构造逻辑,提升代码复用性与可测试性。
3.1.1 RESTful接口接收前端传参的设计模式
在实际开发中,前端可能通过多种方式传递SQL查询请求,例如纯SQL语句、字段条件组合、分页参数等。设计良好的API应能区分不同类型的查询场景,并采用合适的HTTP方法与数据格式。
推荐使用 POST /api/v1/query 作为主入口,接受JSON格式的请求体,其典型结构如下:
{
"sql": "SELECT user_id, SUM(amount) FROM sales WHERE region = ? GROUP BY user_id LIMIT 100",
"params": ["north"],
"timeoutSeconds": 30
}
该设计具有以下优势:
- 使用 POST 而非 GET ,规避URL长度限制;
- 明确分离SQL模板与参数,便于后续预编译处理;
- 支持设置超时时间,防止长时间阻塞线程;
- 可扩展其他元信息如租户ID、审计标签等。
对应的Spring MVC控制器示例如下:
@RestController
@RequestMapping("/api/v1")
public class QueryController {
@Autowired
private DynamicQueryService queryService;
@PostMapping("/query")
public ResponseEntity<?> executeQuery(@RequestBody QueryRequest request) {
try {
Object result = queryService.executeQuery(request);
return ResponseEntity.ok(result);
} catch (Exception e) {
return ResponseEntity.status(500).body(Map.of("error", e.getMessage()));
}
}
}
class QueryRequest {
private String sql;
private List<Object> params;
private int timeoutSeconds = 60;
// getters and setters
}
代码逻辑逐行解读分析:
- 第4行:
@RestController表明该类为REST控制器,所有方法默认返回JSON。- 第5行:全局路径映射
/api/v1,符合版本化API设计规范。- 第9–17行:定义
executeQuery方法处理POST请求,接收一个QueryRequest对象。- 第11行:调用服务层执行查询,体现分层架构思想。
- 第14行:捕获异常并返回500错误,虽为简化写法,但在正式环境中应交由全局异常处理器处理(见3.3节)。
此外,还可以引入Swagger/OpenAPI文档注解(如 @Operation , @Parameter ),提升API可读性与自动化测试能力。
参数设计的最佳实践
| 参数名 | 类型 | 必填 | 描述说明 |
|---|---|---|---|
sql | String | 是 | 预编译风格的SQL语句(支持 ? 占位符) |
params | List | 否 | 按顺序填充占位符的实际参数值 |
timeoutSeconds | Integer | 否 | 查询最大执行时间(秒),默认60 |
catalog | String | 否 | 指定Presto Catalog(可用于多租户隔离) |
schema | String | 否 | 指定Schema上下文 |
此表格体现了参数设计的清晰边界,有助于前后端协同开发。
sequenceDiagram
participant Frontend
participant Controller
participant Service
participant JDBCExecutor
Frontend->>Controller: POST /api/v1/query + JSON body
Controller->>Service: 调用executeQuery(queryRequest)
Service->>JDBCExecutor: 构造PreparedStatement并绑定参数
JDBCExecutor->>Presto: 执行远程查询
Presto-->>JDBCExecutor: 返回ResultSet
JDBCExecutor-->>Service: 解析结果集
Service-->>Controller: 返回List<Map<String, Object>>
Controller-->>Frontend: 200 OK + JSON结果
上述流程图展示了从请求进入至结果返回的完整链路,强调了各组件之间的职责划分与数据流动方向。
3.1.2 参数化查询构造与SQL拼接逻辑封装
尽管允许用户提交任意SQL看似违背安全原则,但通过强制要求使用参数化查询(parameterized query),可在保留灵活性的同时大幅降低风险。关键在于禁止字符串拼接,转而依赖预编译机制绑定变量。
SQL拼接的风险示例
假设采用如下错误做法:
String userInput = request.getParameter("region");
String sql = "SELECT * FROM sales WHERE region = '" + userInput + "'";
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery(sql); // 危险!
若用户输入 north' OR '1'='1 ,最终SQL变为:
SELECT * FROM sales WHERE region = 'north' OR '1'='1'
这将导致全表扫描,构成典型的SQL注入漏洞。
安全的参数化构造方案
正确方式是使用 PreparedStatement 并配合占位符:
String sql = "SELECT user_id, amount FROM sales WHERE region = ? AND created_date >= ?";
try (PreparedStatement ps = connection.prepareStatement(sql)) {
ps.setString(1, "north");
ps.setObject(2, LocalDate.of(2024, 1, 1));
try (ResultSet rs = ps.executeQuery()) {
// 处理结果
}
}
然而,在动态SQL场景中,SQL本身由用户输入,无法预先编译。此时可通过中间层进行“二次包装”:
@Service
public class DynamicQueryService {
public List<Map<String, Object>> executeQuery(QueryRequest request) throws SQLException {
Connection conn = dataSource.getConnection();
// 设置查询超时
conn.setNetworkTimeout(Executors.newSingleThreadExecutor().submit(() -> {}),
request.getTimeoutSeconds() * 1000);
try (PreparedStatement ps = conn.prepareStatement(request.getSql())) {
// 绑定参数
List<Object> params = request.getParams();
if (params != null) {
for (int i = 0; i < params.size(); i++) {
ps.setObject(i + 1, params.get(i));
}
}
try (ResultSet rs = ps.executeQuery()) {
return ResultSetUtil.toList(rs);
}
}
}
}
代码逻辑逐行解读分析:
- 第6行:获取数据库连接,此处假设已配置好Presto DataSource。
- 第9–10行:设置网络超时,防止慢查询耗尽线程资源,这是Presto JDBC的重要调优点。
- 第12行:使用用户提供的SQL创建PreparedStatement——前提是该SQL已包含
?占位符。- 第17–20行:遍历参数列表,按位置依次绑定值,利用JDBC标准API完成安全赋值。
- 第23行:调用工具类将ResultSet转换为通用结构,详见第4章内容。
封装SQL构造器提升安全性
为进一步控制SQL内容,可引入 SqlBuilder 类,限制仅允许构造特定类型的查询:
public class SafeSqlBuilder {
private StringBuilder sql = new StringBuilder();
private List<Object> parameters = new ArrayList<>();
public SafeSqlBuilder select(String... columns) {
sql.append("SELECT ").append(String.join(", ", columns)).append(" ");
return this;
}
public SafeSqlBuilder from(String table) {
sql.append("FROM ").append(table).append(" ");
return this;
}
public SafeSqlBuilder where(String condition, Object param) {
sql.append("WHERE ").append(condition).append(" ");
parameters.add(param);
return this;
}
public String build() {
return sql.toString();
}
public List<Object> getParameters() {
return Collections.unmodifiableList(parameters);
}
}
使用示例:
SafeSqlBuilder builder = new SafeSqlBuilder()
.select("user_id", "SUM(amount)")
.from("sales")
.where("region = ?", "north");
String sql = builder.build(); // SELECT user_id, SUM(amount) FROM sales WHERE region = ?
List<Object> params = builder.getParameters();
这种方式虽然牺牲了一定灵活性,但极大增强了可审计性与防注入能力,适合对安全性要求极高的场景。
graph TD
A[用户输入查询条件] --> B{是否允许原生SQL?}
B -->|否| C[使用SqlBuilder构造]
B -->|是| D[验证SQL语法合法性]
C --> E[生成参数化SQL]
D --> F[检查关键词黑名单]
E --> G[PreparedStatement.execute()]
F --> G
G --> H[返回结果]
该流程图展示了两种路径下的安全处理逻辑分支,体现了“默认拒绝、显式允许”的安全设计理念。
3.2 SQL注入防护机制构建
即使采用了参数化查询,仍不能完全杜绝SQL注入风险,特别是在允许执行原生SQL的系统中。因此,必须构建多层次的防护体系,包括输入校验、语义分析、行为拦截等手段,形成纵深防御(Defense in Depth)架构。
3.2.1 输入校验规则设计(正则匹配、白名单过滤)
最基础的防护措施是对用户输入进行格式校验。对于不允许包含特殊字符的字段(如用户名、区域码),可采用正则表达式限制输入范围。
public class InputValidator {
private static final Pattern SAFE_IDENTIFIER = Pattern.compile("^[a-zA-Z0-9_\\-]{1,64}$");
public static boolean isValidIdentifier(String input) {
return input != null && SAFE_IDENTIFIER.matcher(input).matches();
}
public static boolean containsDangerousKeywords(String sql) {
String lowerSql = sql.toLowerCase();
String[] dangerous = {"drop", "truncate", "delete", "update", "insert", "exec", "alter"};
for (String keyword : dangerous) {
if (lowerSql.contains(keyword)) {
return true;
}
}
return false;
}
}
代码逻辑逐行解读分析:
- 第4行:定义合法标识符正则,仅允许字母、数字、下划线和连字符,长度1~64。
- 第8–10行:判断输入是否符合安全命名规范,适用于表名、字段名等场景。
- 第13–19行:简单关键词检测,防止执行DDL/DML操作。
虽然这种黑名单机制容易被绕过(如 /* */DROP/**/TABLE ),但仍可作为第一道防线。
更高级的做法是结合ANTLR或JSqlParser等SQL解析库进行语法树分析,精确识别语句类型。
白名单控制策略对比表
| 控制维度 | 黑名单策略 | 白名单策略 |
|---|---|---|
| 安全强度 | 低 | 高 |
| 维护成本 | 高(需持续更新攻击变种) | 低(只需定义允许的操作) |
| 误杀率 | 高 | 低 |
| 适用场景 | 快速上线、临时补丁 | 核心系统、金融类应用 |
| 实现复杂度 | 简单 | 中等(需解析SQL AST) |
建议在生产环境中优先采用白名单机制,仅允许 SELECT 语句执行,并限制访问特定Catalog/Schema。
3.2.2 PreparedStatement预编译机制的应用局限与替代方案
许多人误以为只要使用 PreparedStatement 就能免疫SQL注入,但实际上这一机制的前提是 SQL模板固定 。当SQL本身来自用户输入时,预编译仅作用于参数部分,而SQL结构仍可被操控。
例如:
String userSql = "SELECT * FROM users WHERE id = ?; DROP TABLE accounts";
PreparedStatement ps = conn.prepareStatement(userSql);
ps.setInt(1, 123);
ps.execute(); // 在某些驱动中可能导致多语句执行!
虽然Presto JDBC驱动默认不支持多语句(multi-statement),但某些数据库(如MySQL)若未显式关闭 allowMultiQueries=true ,则存在风险。
替代防护方案
- SQL解析器验证 :使用 JSqlParser 解析语句,确保仅为单一
SELECT。
<!-- pom.xml -->
<dependency>
<groupId>com.github.jsqlparser</groupId>
<artifactId>jsqlparser</artifactId>
<version>4.7</version>
</dependency>
public boolean isSafeSelectOnly(String sql) throws JSQLParserException {
Statement statement = CCJSqlParserUtil.parse(sql.trim());
return statement instanceof Select &&
!containsForbiddenOperations(sql.toLowerCase());
}
- 执行前重写 :将原始SQL包装在子查询中,限制副作用:
-- 原始输入
DELETE FROM logs;
-- 重写后执行
SELECT * FROM (DELETE FROM logs) LIMIT 0;
-- 因外部SELECT限制,实际不会执行DELETE
此类技术可在不影响用户体验的前提下实现“只读沙箱”效果。
3.2.3 自定义SQL解析器对高危操作拦截
构建基于AST(抽象语法树)的SQL审查引擎,是实现精细化控制的关键。以下是一个简化的实现框架:
@Component
public class SqlSafetyInterceptor {
public void validateAndIntercept(String sql) throws SecurityException {
try {
Statement stmt = CCJSqlParserUtil.parse(sql);
if (!(stmt instanceof Select)) {
throw new SecurityException("Only SELECT statements are allowed");
}
Select select = (Select) stmt;
PlainSelect plain = (PlainSelect) select.getSelectBody();
if (plain.getInto() != null) {
throw new SecurityException("INTO clause is not permitted");
}
if (hasSubSelectWithModification(plain.getFromItem())) {
throw new SecurityException("Subquery with data modification detected");
}
} catch (Throwable t) {
throw new SecurityException("Invalid or unsafe SQL syntax: " + t.getMessage());
}
}
private boolean hasSubSelectWithModification(FromItem from) {
if (from instanceof SubSelect) {
Select subSelect = ((SubSelect) from).getSelect();
return !(subSelect.getSelectBody() instanceof PlainSelect);
}
return false;
}
}
代码逻辑逐行解读分析:
- 第6–7行:尝试解析SQL,任何语法错误均视为潜在攻击。
- 第10–11行:强制要求必须是
SELECT语句。- 第14–15行:禁止
SELECT ... INTO,防止写入操作。- 第18–21行:递归检查子查询是否存在非查询结构,增强防御深度。
该拦截器应在 DynamicQueryService 调用前执行,作为前置守门人。
flowchart LR
A[收到SQL请求] --> B{是否启用SQL解析?}
B -->|是| C[使用JSqlParser解析AST]
C --> D[检查是否为SELECT]
D --> E[检查有无危险子句]
E --> F[放行执行]
B -->|否| G[跳过解析]
G --> F
F --> H[执行PreparedStatement]
此流程图展示了带解析校验的完整执行路径,突出了“先验后行”的安全哲学。
3.3 异常捕获与错误响应体系设计
动态SQL执行过程中可能出现各类异常,包括语法错误、权限不足、连接超时、资源耗尽等。若直接暴露原始异常堆栈,不仅影响用户体验,还可能泄露系统内部信息。因此,必须设计分级异常处理机制,并返回结构化错误响应。
3.3.1 SQLException分级处理策略
JDBC抛出的 SQLException 通常包含丰富上下文,但其层级结构复杂,需分类处理:
| 错误类别 | 示例错误码 | 处理建议 |
|---|---|---|
| 连接失败 | 08XXX | 返回503 Service Unavailable |
| 语法错误 | 42000 | 返回400 Bad Request + 错误位置 |
| 权限拒绝 | 42501 | 返回403 Forbidden |
| 资源超限(内存/时间) | HY001/HYT00 | 返回429 Too Many Requests 或 504 Gateway Timeout |
| 数据不存在 | 42S02 | 视业务决定是否报错 |
示例处理逻辑:
@ControllerAdvice
public class SqlExceptionHandler {
@ExceptionHandler(SQLException.class)
public ResponseEntity<Map<String, Object>> handleSqlException(SQLException e) {
Map<String, Object> error = new HashMap<>();
String state = e.getSQLState();
error.put("code", "SQL_ERROR");
error.put("message", e.getMessage());
if (state != null) {
if (state.startsWith("08")) {
error.put("severity", "FATAL");
error.put("httpStatus", 503);
} else if (state.startsWith("42")) {
error.put("severity", "ERROR");
if (state.equals("42000")) {
error.put("hint", "Check your SQL syntax");
} else if (state.equals("42501")) {
error.put("hint", "Insufficient privileges");
}
error.put("httpStatus", 400);
}
}
return ResponseEntity.status((Integer) error.get("httpStatus"))
.body(error);
}
}
代码逻辑逐行解读分析:
- 第1行:
@ControllerAdvice实现全局异常捕获。- 第5行:拦截所有
SQLException。- 第10–24行:根据SQLState前缀判断错误类别,设定严重等级与HTTP状态码。
- 第27行:统一返回结构化JSON,便于前端解析展示。
3.3.2 统一异常处理器(@ControllerAdvice)实现
除了数据库异常,还需处理参数绑定失败、空指针、IO异常等。完整异常处理器应覆盖常见类型:
@ExceptionHandler({MethodArgumentNotValidException.class, HttpMessageNotReadableException.class})
public ResponseEntity<?> handleValidationException(Exception e) {
return ResponseEntity.badRequest().body(Map.of(
"code", "VALIDATION_ERROR",
"message", e.getMessage(),
"httpStatus", 400
));
}
@ExceptionHandler(Exception.class)
public ResponseEntity<?> handleGenericException(Exception e) {
log.error("Unexpected error", e);
return ResponseEntity.status(500).body(Map.of(
"code", "INTERNAL_ERROR",
"message", "An internal server error occurred",
"httpStatus", 500
));
}
3.3.3 返回结构化错误信息以提升前端调试效率
标准化错误响应格式示例:
{
"timestamp": "2024-04-05T10:23:45Z",
"code": "SQL_SYNTAX_ERROR",
"message": "line 1:23: mismatched input 'FRM' expecting {'(', 'SELECT', 'SHOW', 'VALUES', 'WITH', 'DESCRIBE'}",
"severity": "ERROR",
"httpStatus": 400,
"traceId": "req-abc123xyz"
}
前端可根据 code 字段做国际化翻译, traceId 用于日志追踪,极大提升问题定位速度。
classDiagram
class ErrorResponse {
+String timestamp
+String code
+String message
+String severity
+Integer httpStatus
+String traceId
}
综上所述,健全的异常处理体系不仅是容错机制,更是提升系统专业度的重要组成部分。
4. 结果集处理与性能优化关键技术
在现代大数据实时查询系统中,Presto 作为一款分布式 SQL 查询引擎,具备跨数据源、低延迟、高并发的显著优势。然而,在实际生产环境中,仅依赖 Presto 自身的计算能力并不足以保障整体系统的响应效率和稳定性。特别是在 SpringBoot 构建的微服务架构下,如何高效地解析 JDBC 返回的结果集,并将其以最优方式转换为前端可消费的数据格式,同时结合连接池管理、并发控制和资源调度策略进行性能调优,是决定系统吞吐量和用户体验的关键环节。
本章将深入探讨从 ResultSet 到 JSON 的全流程数据处理机制,重点分析类型推断、列映射、流式读取等核心技术点;随后引入 HikariCP 连接池在 Presto 场景下的最佳实践配置方案,剖析最大连接数、超时机制与空闲回收策略之间的平衡关系;最后通过慢查询日志采集、执行计划分析(EXPLAIN)、分区裁剪优化以及客户端缓冲机制,揭示在高并发实时分析场景下识别并解决性能瓶颈的有效路径。整个过程不仅涵盖代码实现细节,还结合流程图与参数表格,提供一套完整、可落地的技术优化框架。
4.1 ResultSet解析与JSON格式转换
在 Java 应用通过 JDBC 执行 Presto 查询后,返回的核心对象是 java.sql.ResultSet ,它封装了查询结果的所有行与列信息。但由于其底层基于游标迭代的特性,若不加以合理封装,直接暴露给上层业务逻辑或 REST 接口,极易引发内存溢出、类型错误或序列化异常等问题。因此,构建一个高效、安全且通用的结果集解析器,成为连接数据库访问层与 Web 层之间不可或缺的桥梁。
4.1.1 迭代遍历结果集并提取元数据信息
ResultSet 提供了丰富的元数据接口,允许开发者在运行时动态获取字段名称、数据类型、精度、是否为空等结构化信息。这些信息对于后续的 JSON 转换至关重要,尤其是在面对动态 SQL 查询或未知 Schema 的场景时,无法预先定义 POJO 类型,必须依赖元数据完成自动映射。
以下是一个典型的元数据提取示例:
import java.sql.*;
import java.util.*;
public Map<String, Object> extractMetaData(ResultSet rs) throws SQLException {
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();
Map<String, Object> schemaInfo = new HashMap<>();
List<Map<String, String>> columns = new ArrayList<>();
for (int i = 1; i <= columnCount; i++) {
Map<String, String> col = new HashMap<>();
col.put("name", metaData.getColumnName(i));
col.put("type", metaData.getColumnTypeName(i));
col.put("className", metaData.getColumnClassName(i));
col.put("label", metaData.getColumnLabel(i));
col.put("nullable", String.valueOf(metaData.isNullable(i)));
col.put("precision", String.valueOf(metaData.getPrecision(i)));
columns.add(col);
}
schemaInfo.put("totalColumns", columnCount);
schemaInfo.put("columns", columns);
return schemaInfo;
}
代码逻辑逐行解读:
- 第 5 行:调用
getMetaData()获取当前结果集的元数据对象。 - 第 6 行:获取总列数,用于循环遍历。
- 第 9–18 行:遍历每一列,使用标准 JDBC 元数据方法提取关键属性:
-
getColumnName(i):物理列名; -
getColumnTypeName(i):数据库中的类型名(如 VARCHAR、BIGINT); -
getColumnClassName(i):Java 对应类名(如java.lang.String); -
getColumnLabel(i):别名或显示标签; -
isNullable(i):判断是否允许 NULL; -
getPrecision(i):数值类型的精度。 - 第 20–23 行:将所有列信息组织成结构化 Map 并返回。
该元数据可用于前端展示表头、生成 Swagger 示例响应、构建动态表单等场景。
使用 Mermaid 流程图描述结果集解析流程
graph TD
A[执行SQL查询] --> B{ResultSet 是否为空?}
B -- 是 --> C[返回空列表]
B -- 否 --> D[获取ResultSetMetaData]
D --> E[初始化列定义集合]
E --> F[遍历每列]
F --> G[提取列名、类型、精度等属性]
G --> H[存储到Map结构]
H --> I{是否还有下一列?}
I -- 是 --> F
I -- 否 --> J[开始逐行读取数据]
J --> K[创建空List<Map<String, Object>>]
K --> L[while next() 循环]
L --> M[按列索引读取值]
M --> N[根据类型调用getInt/getString等]
N --> O[放入当前行Map]
O --> P{是否为NULL?}
P -- 是 --> Q[设为null]
P -- 否 --> R[保留原值]
R --> S[添加到结果List]
S --> T[继续下一行]
T --> L
L -- 结束 --> U[序列化为JSON]
U --> V[返回HTTP响应]
此流程清晰展示了从执行查询到最终输出 JSON 的完整生命周期,强调了元数据先行、类型判断、空值处理等关键节点。
4.1.2 列名映射与类型自动推断机制
由于 Presto 支持复杂嵌套类型(如 ROW、ARRAY、MAP),JDBC 驱动会将其映射为特定字符串格式或 JSON 文本。例如, ROW(name VARCHAR, age INT) 可能表现为 "{'name': 'Alice', 'age': 30}" 字符串形式。因此,在解析过程中需结合元数据中的类型信息进行智能转换。
下面是一个增强型类型推断处理器:
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public Object inferAndConvert(ResultSet rs, int columnIndex, String columnType)
throws SQLException {
if (rs.getObject(columnIndex) == null) {
return null;
}
switch (columnType.toUpperCase()) {
case "VARCHAR":
case "CHAR":
return rs.getString(columnIndex);
case "BIGINT":
case "INTEGER":
return rs.getLong(columnIndex);
case "DOUBLE":
case "REAL":
return rs.getDouble(columnIndex);
case "BOOLEAN":
return rs.getBoolean(columnIndex);
case "DATE":
return rs.getDate(columnIndex).toString();
case "TIMESTAMP":
return rs.getTimestamp(columnIndex).toInstant().toString();
case "ARRAY":
case "MAP":
case "ROW":
String rawJson = rs.getString(columnIndex);
try {
return new ObjectMapper().readTree(rawJson);
} catch (JsonProcessingException e) {
throw new SQLException("Failed to parse JSON-like structure: " + rawJson, e);
}
default:
return rs.getObject(columnIndex).toString();
}
}
参数说明与扩展性分析:
-
columnIndex:列索引(从 1 开始),符合 JDBC 规范。 -
columnType:来自getColumnTypeName()的数据库类型标识。 -
ObjectMapper.readTree():将字符串解析为 Jackson 的JsonNode,支持嵌套结构。 - 默认分支使用
.toString()保证兼容未知类型。
该机制实现了对常见标量类型的安全转换,并对复合类型尝试 JSON 解析,避免简单 toString 导致的数据失真。
类型映射对照表示例
| Presto 类型 | JDBC Type Name | Java 映射类 | 处理方式 |
|---|---|---|---|
| VARCHAR | VARCHAR | String | 直接 getString |
| INTEGER | INTEGER | Integer | getLong 转 Number |
| DOUBLE | DOUBLE | Double | getDouble |
| BOOLEAN | BOOLEAN | Boolean | getBoolean |
| TIMESTAMP | TIMESTAMP | Instant | toInstant().toString() |
| DATE | DATE | LocalDate | toString 输出 ISO 格式 |
| ARRAY/VARCHAR | ARRAY | List | JSON 解析 |
| MAP(VARCHAR, INTEGER) | MAP | Map | JSON 解析 |
| ROW(a INT, b VARCHAR) | ROW | Map | JSON 解析 |
此表可用于指导 ORM 框架设计或生成文档,提升团队协作效率。
4.1.3 高效转换为List >并序列化为JSON
为了满足 RESTful API 返回通用 JSON 数组的需求,通常采用 List<Map<String, Object>> 作为中间结构。这种“无模型”模式适用于动态查询,但需注意性能开销与 GC 压力。
以下是完整的转换方法实现:
public List<Map<String, Object>> resultSetToList(ResultSet rs) throws SQLException {
ResultSetMetaData metaData = rs.getMetaData();
int columnCount = metaData.getColumnCount();
List<Map<String, Object>> result = new ArrayList<>();
while (rs.next()) {
Map<String, Object> row = new HashMap<>(columnCount);
for (int i = 1; i <= columnCount; i++) {
String columnName = metaData.getColumnLabel(i); // 使用 label 更友好
Object value = inferAndConvert(rs, i, metaData.getColumnTypeName(i));
row.put(columnName, value);
}
result.add(row);
}
return result;
}
逻辑分析:
- 使用
getColumnLabel(i)而非getColumnName(i),优先使用别名(AS 子句),更适合前端展示。 - 每次
rs.next()触发一次行移动,内部循环填充该行各列。 - 调用前文定义的
inferAndConvert方法确保类型正确。 - 最终返回
List<Map<String, Object>>,Spring MVC 可自动通过 Jackson 序列化为 JSON 数组。
假设查询结果如下:
SELECT user_id AS id, name AS fullName, ARRAY['a','b'] AS tags FROM users LIMIT 2;
则输出 JSON 将为:
[
{
"id": 1001,
"fullName": "Alice",
"tags": ["a", "b"]
},
{
"id": 1002,
"fullName": "Bob",
"tags": ["x", "y"]
}
]
完全保留原始语义,且支持嵌套结构。
性能建议
尽管该模式灵活,但在大结果集场景下应谨慎使用。建议:
- 控制单次查询行数(LIMIT);
- 启用流式读取(见 4.3.3);
- 若结构固定,优先使用 DTO + ResultTransformer 减少 Map 创建开销;
- 配合 Jackson 的
@JsonRawValue或自定义 Serializer 进一步优化序列化性能。
4.2 连接池集成与查询性能调优
在高频调用 Presto 查询的服务中,频繁创建和销毁 JDBC 连接会导致显著的性能损耗。HikariCP 作为目前最快的生产级连接池之一,凭借极低的延迟和高效的资源管理能力,成为 SpringBoot 项目中的首选方案。然而,将其应用于 Presto 这类远程 OLAP 引擎时,需针对网络延迟、查询耗时长等特点调整默认配置。
4.2.1 HikariCP在Presto JDBC场景中的适配配置
Spring Boot 自动装配 HikariCP 作为默认 DataSource 实现,但默认配置偏向 OLTP 场景(短事务、快速释放)。而 Presto 查询往往持续数秒甚至数十秒,容易触发连接超时或耗尽池资源。
推荐配置如下( application.yml ):
spring:
datasource:
url: jdbc:presto://presto-coordinator:8080/hive/default
username: admin
password:
driver-class-name: com.facebook.presto.jdbc.PrestoDriver
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
validation-timeout: 5000
idle-timeout: 600000
max-lifetime: 1800000
leak-detection-threshold: 60000
pool-name: PrestoHikariPool
参数详细说明表
| 参数名 | 推荐值 | 说明 |
|---|---|---|
maximum-pool-size | 20 | 根据并发需求设定,过高易导致 Coordinator 压力过大 |
minimum-idle | 5 | 保持最小空闲连接,减少冷启动延迟 |
connection-timeout | 30000ms | 获取连接的最大等待时间 |
validation-timeout | 5000ms | 连接有效性检测超时 |
idle-timeout | 600000ms (10min) | 空闲连接回收时间,避免过早关闭活跃连接 |
max-lifetime | 1800000ms (30min) | 连接最大存活时间,防止长期连接老化 |
leak-detection-threshold | 60000ms | 检测连接泄露,帮助定位未关闭的 Statement/Connection |
pool-name | 自定义 | 方便监控与日志追踪 |
这些参数需根据实际负载压测调优,尤其注意 maximum-pool-size 不宜盲目增大,否则可能压垮 Presto Coordinator。
4.2.2 最大连接数、超时时间与空闲回收策略设定
连接池的核心在于平衡资源利用率与响应速度。以下为典型调优策略:
- 最大连接数 :应小于 Presto Coordinator 的
query.max-concurrent-plans-per-node设置,避免反压。 - 连接超时 :设置合理阈值防止线程阻塞太久,一般设为业务 SLA 的 80%。
- 空闲回收 :不宜过短,因 Presto 建立连接涉及认证开销,频繁重建影响性能。
可通过编程方式进一步定制:
@Bean
@ConfigurationProperties("spring.datasource.hikari")
public HikariDataSource hikariDataSource() {
return new HikariDataSource();
}
配合外部化配置,便于不同环境差异化部署。
4.2.3 查询并发控制与资源隔离机制
当多个用户同时提交复杂查询时,单一连接池可能被占满,影响其他轻量请求。为此可引入资源隔离机制:
多连接池架构设计
| 查询类型 | 用途 | 最大连接数 | 超时设置 |
|---|---|---|---|
fast-pool | 简单统计、维度查询 | 10 | 10s |
heavy-pool | 复杂聚合、跨表 JOIN | 10 | 60s+ |
adhoc-pool | 即席查询(管理员专用) | 5 | 120s |
通过自定义 AbstractRoutingDataSource 实现动态路由:
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return QueryContextHolder.getQueryType(); // ThreadLocal 绑定
}
}
前端可通过 Header 指定查询类别,后端据此选择对应池,实现资源分级管控。
4.3 实时分析场景下的性能瓶颈识别与优化
4.3.1 慢查询日志收集与执行计划查看(EXPLAIN)
启用慢查询日志是性能诊断的第一步。可在应用层记录执行时间超过阈值的 SQL:
long start = System.currentTimeMillis();
try {
ResultSet rs = stmt.executeQuery(sql);
long duration = System.currentTimeMillis() - start;
if (duration > 5000) {
log.warn("Slow query detected: {}ms\nSQL: {}", duration, sql);
}
} catch (SQLException e) {
log.error("Query failed: {}", sql, e);
}
同时利用 Presto 的 EXPLAIN 命令分析执行计划:
EXPLAIN SELECT count(*) FROM large_table WHERE dt = '2024-01-01';
输出将显示 Stage 分布、算子成本、是否下推等信息,辅助判断是否命中分区、能否向 Hive 元数据下推过滤条件。
4.3.2 分区裁剪与列式扫描优化建议
确保 WHERE 条件中包含分区列(如 dt , hour ),以便 Presto 实现 Partition Pruning:
✅ 有效裁剪:
SELECT * FROM logs WHERE dt = '2024-05-01' AND city = 'Beijing';
❌ 无效裁剪:
SELECT * FROM logs WHERE substr(dt, 1, 7) = '2024-05'; -- 函数阻止裁剪
此外,只 SELECT 必要字段,避免 SELECT * 浪费 I/O 带宽。
4.3.3 客户端缓冲与流式读取结合降低内存压力
对于超大规模结果集,应启用流式读取模式:
Statement stmt = connection.createStatement();
stmt.setFetchSize(1000); // 启用分页拉取
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
// 逐行处理,避免一次性加载全部
}
配合 Jackson 的 JsonGenerator 直接写入 HttpServletResponse 输出流,实现零内存缓存的 Streaming API。
graph LR
A[客户端发起查询] --> B{结果集大小预估}
B -- 小于1万行 --> C[全量加载+缓存]
B -- 大于1万行 --> D[启用setFetchSize流式读取]
D --> E[每次fetch 1000行]
E --> F[边读边序列化JSON]
F --> G[写入OutputStream]
G --> H[客户端渐进式接收]
此举可将内存占用从 GB 级降至 MB 级,极大提升系统稳定性。
5. PrestoDEMO完整项目架构与工程实践
5.1 项目整体结构与模块划分
在构建一个面向生产环境的 Presto 数据查询平台时,合理的项目结构是保障可维护性、扩展性和稳定性的关键。本节将围绕 PrestoDEMO 示例项目的实际工程结构展开,详细说明其分层设计、配置管理及核心工具类封装。
5.1.1 Controller-Service-DAO分层架构实现
项目采用标准的三层架构模式:
- Controller 层 :负责接收 RESTful 请求,校验参数并调用 Service。
- Service 层 :处理业务逻辑,协调 DAO 调用,并进行异常转换。
- DAO 层(Data Access Object) :直接与 Presto JDBC 交互,执行 SQL 查询并返回结果集。
// 示例:QueryController.java
@RestController
@RequestMapping("/api/v1/query")
public class QueryController {
@Autowired
private QueryService queryService;
@PostMapping
public ResponseEntity<?> executeQuery(@RequestBody Map<String, String> request) {
String sql = request.get("sql");
try {
List<Map<String, Object>> result = queryService.executeQuery(sql);
return ResponseEntity.ok(result);
} catch (SQLException e) {
return ResponseEntity.status(500).body(Map.of("error", e.getMessage()));
}
}
}
该结构清晰分离关注点,便于单元测试和后期横向扩展。
5.1.2 配置类自动装载JDBC Bean实例
通过 @Configuration 类集中管理 Presto 连接资源,利用 Spring 的依赖注入机制实现连接池初始化。
@Configuration
public class PrestoConfig {
@Value("${presto.jdbc.url}")
private String jdbcUrl;
@Value("${presto.user}")
private String user;
@Value("${presto.password}")
private String password;
@Bean
@Primary
public DataSource prestoDataSource() {
HikariConfig config = new HikariConfig();
config.setJdbcUrl(jdbcUrl);
config.setUsername(user);
config.setPassword(password);
config.setMaximumPoolSize(20);
config.setConnectionTimeout(30_000);
config.setIdleTimeout(600_000);
config.setMaxLifetime(1_800_000);
return new HikariDataSource(config);
}
}
上述配置确保了连接池高效复用,避免频繁创建销毁连接带来的性能损耗。
5.1.3 工具类封装:SQL执行器与JSON转换器
为提升代码复用率,封装两个核心工具类:
| 工具类 | 功能描述 |
|---|---|
SqlExecutorUtil | 执行预编译或动态 SQL,安全处理 ResultSet |
JsonConverterUtil | 将 List > 转换为 JSON 字符串 |
public class SqlExecutorUtil {
public static List<Map<String, Object>> executeQuery(Connection conn, String sql)
throws SQLException {
try (PreparedStatement stmt = conn.prepareStatement(sql);
ResultSet rs = stmt.executeQuery()) {
ResultSetMetaData meta = rs.getMetaData();
int columnCount = meta.getColumnCount();
List<Map<String, Object>> rows = new ArrayList<>();
while (rs.next()) {
Map<String, Object> row = new HashMap<>();
for (int i = 1; i <= columnCount; i++) {
String colName = meta.getColumnName(i);
Object value = rs.getObject(i);
row.put(colName, value);
}
rows.add(row);
}
return rows;
}
}
}
此工具类屏蔽底层 JDBC 细节,对外提供简洁 API 接口,降低开发门槛。
classDiagram
class QueryController {
+executeQuery()
}
class QueryService {
+executeQuery()
}
class QueryDao {
+fetchResultSet()
}
class SqlExecutorUtil {
+executeQuery()
}
class JsonConverterUtil {
+toJson()
}
class PrestoConfig {
+prestoDataSource()
}
QueryController --> QueryService
QueryService --> QueryDao
QueryDao --> SqlExecutorUtil
QueryDao --> DataSource
QueryService --> JsonConverterUtil
PrestoConfig --> DataSource
以上 UML 类图展示了各组件之间的协作关系,体现了高内聚、低耦合的设计原则。
此外,项目目录结构如下所示:
src/
├── main/
│ ├── java/
│ │ └── com/example/prestodemo/
│ │ ├── controller/ # REST接口
│ │ ├── service/ # 业务逻辑
│ │ ├── dao/ # 数据访问
│ │ ├── config/ # 配置类
│ │ ├── util/ # 工具类
│ │ └── PrestoDemoApp.java
│ └── resources/
│ ├── application.yml # 包含 presto.jdbc.url 等配置
│ └── logback-spring.xml
└── test/
└── java/ # 单元与集成测试
这种标准化布局符合 Spring Boot 官方推荐,有利于 CI/CD 流水线集成和团队协作开发。
每个模块职责明确,支持独立演进,例如未来可替换 DAO 实现为 MyBatis 或 JPA,而不影响上层逻辑。
简介:PrestoDEMO(JAVA-JDBC)是一个基于SpringBoot框架的示例应用,演示了如何通过Java JDBC连接并操作Presto分布式SQL查询引擎。项目支持通过URL传递SQL语句,经由JDBC执行查询,并将结果转换为JSON格式返回前端。该DEMO涵盖了SpringBoot快速开发、RESTful接口设计、JDBC数据库连接、Presto查询引擎集成、SQL动态执行与JSON数据封装等关键技术,适用于学习大数据环境下Java后端与分布式数据库的交互实现。经过测试验证,项目具备良好的可运行性与扩展性,是掌握Presto与JDBC集成的优质实践案例。


















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









