







背景说明
由于班上有一批学生需要参加HSK5的考试,但是在实际授课中发现他们对于该级别的词几乎不怎么认识,甚至于HSK4的词都有很多没掌握的。所以为了短期突击,需要制作HSK4和5的核心词表。
制作思路如下:
1. 建立HSK标准词表,包括
- 汉字
- 拼音
- 英文
- 词性
- 级别
2. 建立基于标准词表的词频表
3. 按照词频筛选核心词汇(除名词/动词/形容词之外的词类)
4. 按照字族筛选核心词汇(名词/动词/形容词)
之所以要补上按照字族筛选核心词汇,是因为汉字的字族(也就是语素教学法中的语素)能有效降低学生的学习成本和记忆成本。比较适合名词/动词/形容词这三类数量比较多的词类。
具体步骤如下:
一,建立HSK标准词表(1-6级)
网上有现成旧词表下载,需要人工审核的是以下几个部分
1. 词表更新:根据HSK官方考纲2015版,有近12%的词汇是增补的,要替换进旧词表
2. 拼音审核:特别是多音字,大小写,还有谷歌翻译的莫名拼写(比如法国的拼音是Fàguó你敢信?)
3. 义项审核:有些多义词,是需要根据官方考纲的词性标注,进行修正的(比如长zhǎng和长cháng)
二,添加词性分类
在这里词性分类有两个方法
1)直接用手机拍照然后用OCR识别官方考纲上的词性标注,与标准词表进行一一对应
2)用Python调用jieba插件,进行词性标注
我用的是第二种方法,代码如下
#!usr/bin/env Python
# coding = utf-8
import jieba.posseg as pos
import xlrd
import xlwt
input_excel = xlrd.open_workbook('/Users/Arthur/learnPython/vocabulary/HSK5.xlsx')
input_sheet = input_excel.sheets()[0]
output_workbook = xlwt.Workbook(encoding="utf-8")
output_worksheet = output_workbook.add_sheet("new", cell_overwrite_ok=True)
row1 = 1
col1 = 1
#存在词典查不到的词,需要优化
for word_num in range(2144):
item1 = input_sheet.cell(row1,col1).value
part_of_speech = pos.cut(item1)
for word, flag in part_of_speech:
output_worksheet.write(row1-1, col1-1, word)
output_worksheet.write(row1-1, col1, flag)
row1=row1+1
output_workbook.save('/Users/Arthur/learnPython/vocabulary/HSK5-2.xls')标准好的词性分类如下
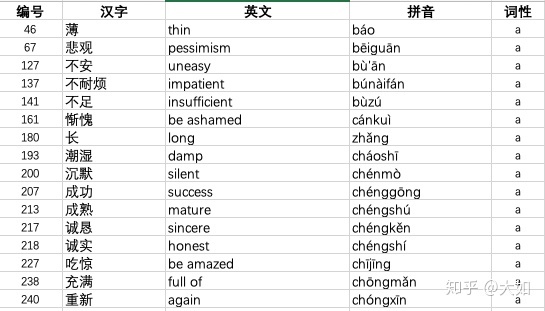
这里有一个问题就是jieba插件的词性分类是按照与ictclas 兼容的标记法进行标记的,很多标记与我们熟知的英语不一致,举例如下:

解决方法是复制到excel之后,进行批量替换即可。
三,建立词频表
因为没有HSK范围内的语料库支持,所以从网上找了一个八千多词频表作为基准。总体而言,针对HSK考试的有效性是不足的,但在时间有限的情况下,也没有更好的办法了。
将HSK标准词表与八千词频表进行比对(用excel的函数vlookup),自动填充HSK词汇的词频。
这里有一个问题就是有些词在词频表里没有出现,采取的处理方法就是:词频作为0处理。不过根据词类排序之后,大部分的虚词还是一眼就能看出来的,影响不大。
建立好的词频表如下:
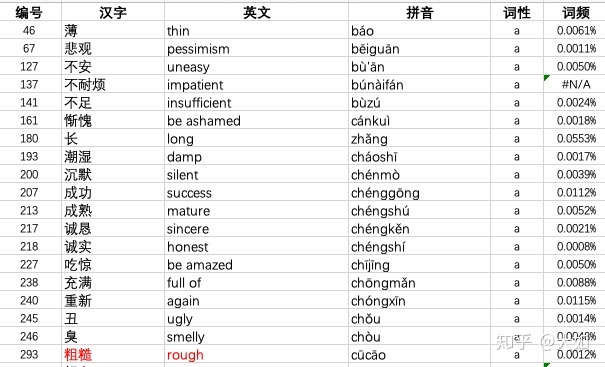
四,筛选核心词汇
筛选核心词汇我采用了两种方法
1)按照词频分
将副词/连词/介词/助词等数量较少的词类,在excel中按照词频排序。
实际情况是,词频基本没啥用,因为这些词类本身数量就比较少,所以基本都入选了核心词汇。
2)按照词频+字族分
前面已经介绍过,采用这种方法的原因是
1. 字族能有效降低学习成本和记忆成本,适合考试的时候猜测词义
2. 名动形这三个词类的词汇数量比较多,用字族就能打破一个一个记忆的障碍,以少驭多。
3. 当筛选出n个字族时,再用字族里所有词汇的权重之和去给字族排序,所以
- 字族的词越多,排名越前
- 不同字族的词一样多,词汇相加的权重之和多高,该字族排名越前
- 排序之后再人工筛选一遍
字族的筛选方式是用Python完成的,代码如下:
#!usr/bin/env Python
# coding = utf-8
import xlrd
import xlwt
input_excel = xlrd.open_workbook('/Users/Arthur/learnPython/vocabulary/HSK5.xlsx')
input_sheet_character = input_excel.sheets()[3]
input_sheet_words = input_excel.sheets()[4]
output_workbook = xlwt.Workbook(encoding="utf-8")
output_worksheet = output_workbook.add_sheet("new")
nrows_words = input_sheet_words.nrows
characters_list = input_sheet_character.col_values(colx=0, start_rowx=0, end_rowx=None)
for item1 in characters_list:
row1 = 0
col1 = 0
item1_list = []
item1_weight = 0
item1_list.append(item1)
for i in range(nrows_words-1):
item2 = input_sheet_words.cell(row1+1, col1+1).value
item2_weight = input_sheet_words.cell(row1+1, col1+5).value
if item2_weight == 42:
item2_weight = 0
if item1 is not item2 and item1 in item2:
item1_list.append(item2)
item1_weight = item1_weight + item2_weight
row1 = row1+1
if len(item1_list) > 3:
print (item1_weight, item1_list)
这里做了一个限制条件,只有字族的词汇数超过3的,才列入字族。
最终代码跑出了744个字族,通过权重排序和人肉筛选,最终挑选了30个字族共380个词,去重后共350个,作为名/动/形/的核心词汇。
本次的核心词汇表(HSK4/5)共582个词,分布如下:

HSK核心词汇(4&5级)是Excel和Python相结合的成果,对于以后其他级别的核心词制作有借鉴意义。目前来看,可以提升的地方有:
- 建立HSK范围的语料库,提高词频表的有效性
- 将字族再进行义项分类,提高字族的精度
其中语料库的建立是非常重要的,今后也会慢慢学习用Python进行语料库的相关编程。















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









