






 本文介绍了C++中哈希表的实现,包括使用分离链接法和开放定址法处理哈希冲突。通过示例展示了如何定义哈希函数,并解释了如何使用平方探测法解决开放定址法中的冲突。此外,还提供了哈希表的插入、删除、查找等操作的代码实现。
本文介绍了C++中哈希表的实现,包括使用分离链接法和开放定址法处理哈希冲突。通过示例展示了如何定义哈希函数,并解释了如何使用平方探测法解决开放定址法中的冲突。此外,还提供了哈希表的插入、删除、查找等操作的代码实现。
template<typename HashedObj>
void HashTable<HashedObj>::makeEmpty() {
for (auto& thislist : thelists)
thislist.clear();
}
template<typename HashedObj>
bool HashTable<HashedObj>::contains(const HashedObj&x)const {
auto& whichList = thelists[mahash(x)];
return find(begin(whichList), end(whichList), x) != end(whichList);
}
template<typename HashedObj>
bool HashTable<HashedObj>::remove(const HashedObj& x) {
auto& whichList = thelists[myhash(x)];
auto itr = find(begin(whichList), end(whichList), x);
if (itr == end(whichList))
return flase;
else
whichList.erase(itr);
--currentSize;
return true;
}
template<typename HashedObj>
bool HashTable<HashedObj>::insert(const HashedObj& x) {
auto& whichList = thelists[myhash(x)];
if (find(begin(whichList), end(whichList), x) != end(whichList))
return false;
whichList.push_back(x);
}class hash {
public:
size_t operator()(const Key& k)const;
};
template<>
class hash<std::string> {
public:
size_t operator()(const std::string& key) {
size_t hashVal = 0;
for (char ch : key)
hashVal = 37 * hashVal + ch;
return hashVal;
}
};
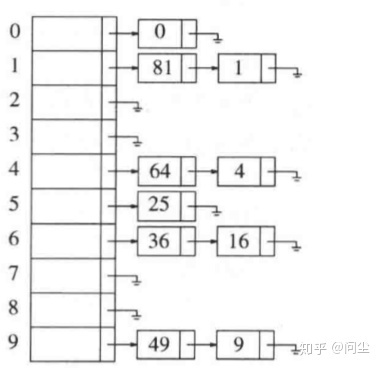
理想的散列表也就是哈希表只不过是一个包含一些项的具有固定大小的数组。
而哈希表的核心是映射。而对于映射,要解决2个问题:
要怎么映射?以及如果映射以后,如果待加入的键和哈希表中已知的项冲突,我们要怎么去解决?
如何映射是让哈希函数来解决这个问题。
通常,键是字符串。一种哈希函数如下所示:
int hash1( const string & key,int tablesize )
{
int hashVal = 0;
for (char ch : key)
hashVal += ch;
return hashVal % tablesize;
}
这个函数的局限性在于如果tablesize过大的话。譬如说对于10007(这个数是素数),并且我们假设我们的字符串最长为8位,那么问题就出现了——8*127=1016(ASCLL码的最大值为127),那么,这些键的分布就只能在0~1016之间了。因此,很容易就会出现冲突的问题。固然,冲突的问题我们有两套解决方法,但是如果有一个更好的分配方式的话,那就不用产生处理冲突的开销。

如图所示,这是一个很好的哈希函数。它可以使映射后的分布相对更均匀。以下使其对应的代码:
unsigned int hash2(const string& key, int tablesize) {
unsigned int hashVal = 0;
for (char ch : key)
hashVal = 37 * hashVal + ch;
return hashVal % tablesize;
}
哈希函数的问题解决了,那接下来就该解决映射冲突的问题了。
首先是分离链接法。
如果发生了映射冲突怎么办?那我把整个表的每个表格扩大不就解决问题了?分离链接法就是用了这个手段,每个表格对应一个链表。
下面是一个哈希表的模板,用了分离链接法的思想:
template<typename HashedObj>
class HashTable {
public:
explicit HashTable(int size = 101);
bool contains(const HashedObj& x)const;
void makeEmpty();
bool insert(const HashedObj& x);
bool insert(HashedObj&& x);
bool remove(const HashedObj& x);
private:
vector<list<HashedObj>>thelists;//分离链接法的体现
int currentSize;
void rehash();
size_t myhash(const HashedObj& x)const {
static hash<HashedObj>hf;
return hf(x) % thelists.size();
};
};
之后是哈希函数,在这里我们不直接写一个哈希函数,而是利用模板的手段,写一个类模板:
class hash {
public:
size_t operator()(const Key& k)const;
};
template<>
class hash<std::string> {
public:
size_t operator()(const std::string& key) {
size_t hashVal = 0;
for (char ch : key)
hashVal = 37 * hashVal + ch;
return hashVal;
}
};
后者是一个模板偏特化的实现。
剩下的则是具体函数的实现:
template<typename HashedObj>
void HashTable<HashedObj>::makeEmpty() {
for (auto& thislist : thelists)
thislist.clear();
}
template<typename HashedObj>
bool HashTable<HashedObj>::contains(const HashedObj&x)const {
auto& whichList = thelists[mahash(x)];
return find(begin(whichList), end(whichList), x) != end(whichList);
}
template<typename HashedObj>
bool HashTable<HashedObj>::remove(const HashedObj& x) {
auto& whichList = thelists[myhash(x)];
auto itr = find(begin(whichList), end(whichList), x);
if (itr == end(whichList))
return flase;
else
whichList.erase(itr);
--currentSize;
return true;
}
template<typename HashedObj>
bool HashTable<HashedObj>::insert(const HashedObj& x) {
auto& whichList = thelists[myhash(x)];
if (find(begin(whichList), end(whichList), x) != end(whichList))
return false;
whichList.push_back(x);
}
myhash()函数的实现在类里。
另一个方法开放基址法,这个方法就是,把整个列表拉长。如果列表够大,那么虽然我的键的映射可能会冲突,那么冲突后的键可以分配到后续的其它地方。
但是要这样做,就要用算法来分配后续的映射。在这里用到的方法是平方探测法。
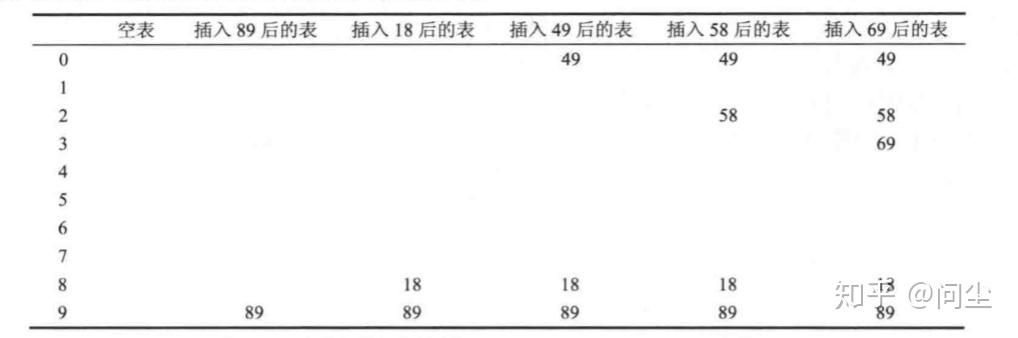
49取余后是9。而89已经占了9的位置了。索性把它分配到0。58取余后是8,位置也被占了。下一个位置在8为2的平方=4的远处,所以把它放到了2的位置。(这方面用语言不好描述,还是看代码吧)
代码如下:
class HashTable {
public:
explicit HashTable(int size = 101) :array(nextPrime(size)) {makeEmpty()};
bool contains(const HashedObj& x)const;
void makeEmpty();
bool insert(const HashedObj& x);
bool remove(const HashedObj& x);
enum EntryType{ACTIVE,EMPTY,DELETED};
private:
struct HashEntry {
HashedObj element;
EntryType info;
HashEntry(const HashedObj& e = HashedObj{}, Entritype i = Empty) :
element{ e }, info{ i };
};
vector<HashEntry>array;
int currentsize;
bool isActive(int currentPos)const;
int findPos(const HashedObj& x)const;
void rehash();
size_t myhash(const HashedObj& x)const;
};
template<typename HashedObj>
void HashTable<HashedObj>::makeEmpty() {
currentsize = 0;
for (auto& entry : array)
entry.info - contact with domain owner = EMPTY;
}
template<typename Key>
class hash {
public:
size_t operator()(const Key& x)const;
};
template<>
class hash<string> {
public:
size_t operator()(const string& x) {
int hashVal = 0;
for (char ch : x)
hashVal = 37 * hashVal + ch;
return hashVal;
}
};
template<typename HashedObj>
size_t HashTable<HashedObj>::myhash(const HashedObj& x)const {
static hash<HashedObj>hf;
return hf(x) % array.size();//存疑
}
template<typename HashedObj>
bool HashTable<HashedObj>::contains(const HashedObj& x)const {
return isActive(findPos(x));
}
template<typename HashedObj>
int HashTable<HashedObj>::findPos(const HashedObj& x)const {
int offset = 1;
int currentPos = myhash(x);
while (array[currentPos].info != EMPTY && array[currentPos].element != x)
{
currentPos += offset;//这两步是平方探测分配
offset += 2;
if (currentPos >= array.size())
currentPos -= array.size();
}
return currentPos;
}
template<typename HashedObj>
bool HashTable<HashedObj>::isActive(int currentPos)const {
return(array[currentPos].info == ACTIVE);
}
template<typename HashedObj>
bool HashTable<HashedObj>::insert(const HashedObj& x) {
int currentPos = findPos(x);
if (isActive(currentPos))
return false;
array[currentPos].element = x;
array[currentPos].info = ACTIVE;
if (++currentSize > array.size() / 2)
rehash();
return true;
}
template<typename HashedObj>
bool HashTable<HashedObj>::remove(const HashedObj& x) {
int currentPos = findPos(x);
if (!isActive(currentPos))
return;
array[currentPos].info = DELETED;
return true;
}
现在还有一个问题,当表快满了的时候怎么办?很简单,把表扩大然后再重新扫描即可。这就是rehash()函数。
分离链接法的rehash:
void rehash() {
vector<list<HashedObj>>oldLists = thelists;
thelists.resize(nextPrime(2 * thelists.size()));
for (auto& thislist : thelists)
thislist.clear();
currentSize = 0;
for (auto& thislist : oldLists)
for (auto& x : thislist)
insert(std::move(x));
};
开放定址法的rehash:
template<typename HashedObj>
void HashTable<HashedObj>::rehash() {
std::vector<HashedObj>oldArray = array;
array.resize(nextPrime(2 * oldArray.size()));
for (auto& entry : array)
entry.info = EMPTY;
currentSize = 0;
for (auto& entry : oldArray)
if (entry.info == ACTIVE)
insert(std::move(entry.element));
}















 2597
2597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









