







我爬取京东上所有手机信息时会碰到如下问题:
1、返回值过多,如下图片所示:
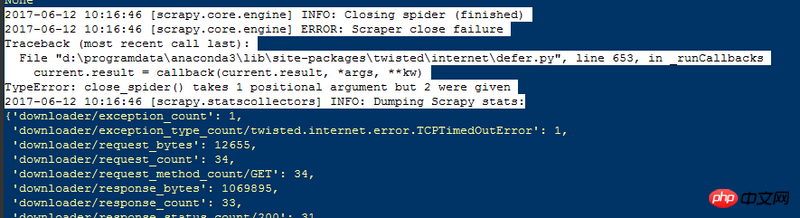
2、spider代码如下:
-- coding: utf-8 --
import scrapy
from scrapy.http import Request
from ueinfo.items import UeinfoItem
class MrueSpider(scrapy.Spider):
name = 'mrue'
allowed_domains = ['jd.com']
start_urls = ['http://jd.com/']
def parse(self, response):
key="手机"
for i in range(1,2):
url="https://search.jd.com/Search?keyword="+str(key)+"&enc=utf-8&page="+str((i*2)-1)
#print(url)
yield Request(url=url,callback=self.page)
def page(self,response):
#body=response.body.decode("utf-8","ignore")
allid=response.xpath("//p[@class='p-focus']//a/@data-sku").extract()
for j in range(0,len(allid)):
thisid=allid[j]
url1="https://item.jd.com/"+str(thisid)+".html"
#print(url1)
yield Request(url=url1,callback=self.next)
def next(self,response):
item=UeinfoItem()
item["pinpai"]=response.x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2147
2147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









