







当我们进行数据处理的时候,往往需要对数据进行查找操作,一个有序的数据集往往能够在高效的查找算法下快速得到结果。所以排序的效率就会显的十分重要,本篇我们将着重的介绍几个常见的排序算法,涉及如下内容:
排序相关的概念
插入类排序
交换类排序
选择类排序
归并排序算法实现
一、排序相关的基本概念
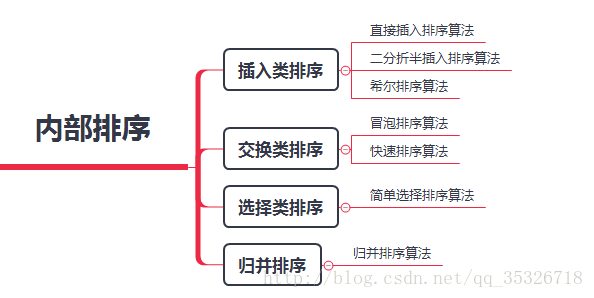
排序其实是一个相当大的概念,主要分为两类:内部排序和外部排序。而我们通常所说的各种排序算法其实指的是内部排序算法。内部排序是基于内存的,整个排序过程都是在内存中完成的,而外部排序指的是由于数据量太大,内存不能完全容纳,排序的时候需要借助外存才能完成(常常是算计着某一部分已经计算过的数据移出内存让另一部分未被计算的数据进入内存)。而我们本篇文章将主要介绍内排序中的几种常用排序算法:
还有一个概念问题,排序的稳定性问题。如果Ai = Aj,排序前Ai在Aj之前,排序后Ai还在Aj之前,则称这种排序算法是稳定的,否则说明该算法不稳定。
二、插入类排序算法
插入类排序算法的核心思想是,在一个有序的集合中,我们将当前值插入到适合位置上,使得插入结束之后整个集合依然是有序的。那我们接下来就学习下这几种同一类别的不同实现。
1、直接插入排序
直接插入排序算法的核心思想是,将第 i 个记录插入到前面 i-1 个已经有序的集合中。下图是一个完整的直接插入排序过程:

因为一个元素肯定是有序的,i 等于 2 的时候,将第二个元素插入到前 i-1个有序集合中,当 i 等于3的时候,将第三个元素插入到前 i-1(2)集合中,等等。直到我们去插入最后一个元素的时候,前面的 i-1 个元素构成的集合已经是有序的了,于是我们找到第 i 个元素的合适位置插入即可,整个插入排序完成。下面是具体的实现代码:
public static void InsertSort(int[] array){
int i=0,j=0,key;
for (i=1;i<10;i++){
key = array[i];
j = i-1;
while(j>=0&&key
//需要移动位置,将较大的值array[j]向后移动一个位置
array[j+1] = array[j];
j--;
}
//循环结束说明找到适当的位置了,是时候插入值了
array[j+1] = key;
}
//输出排序后的数组内容
for (int value : array){
System.out.print(value+",");
}
}
//主函数中对其进行调用
int[] array = {1,13,72,9,22,4,6,781,29,2};
InsertSort(array);
输出结果如下:
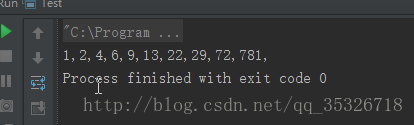
整个程序的逻辑是从数组的第二个元素开始,每个元素都以其前面所有的元素为基本,找到合适的位置进行插入。对于这种按照从小到大的排序原则,程序使用一个临时变量temp保存当前需要插入的元素的值,从前面的子序列的最后一个元素开始,循环的与temp进行比较,一旦发现有大于temp的元素,让它顺序的往后移动一个位置,直到找到一个元素小于temp,那么就找到合适的插入位置了。
因为我们使用的判断条件是,key>array[j]。所以来说,插入排序算法也是稳定的算法。对于值相同的元素并不会更改他们原来的位置顺序。至于该算法的效率,最好的情况是所有元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









